论文解读---一种新的红外可见光图像融合算法
An infrared and visible image fusion method based on multi-scale transformation and norm optimization
- 引言
- 方法论
-
- 预融合图像的生成
- 基于MDLatLRR的图像分解
- 基础层与细节层的图像融合
-
- 基础层
- 细节层
- 逆变换
- 总结
- 对于红外可见光图像融合的思考
论文:
An infrared and visible image fusion method based on multi-scale transformation and norm optimization
代码:(如果觉得论文的思想对你们有帮助,请帮我点亮小星星哈哈哈):
LYJ/IVFusion
以下分为三大部分介绍这篇论文:
研究背景以及现存问题:论文的引言部分对当前红外可见光图像融合研究现状进行了详细总结,相信对于刚接触该方向的同学也可以起到综述的作用,篇幅有限,在这里就不展开了。
方法论:介绍该融合算法的步骤,就单纯介绍,这一步不做讨论。
总结:结合论文实验部分讨论其创新性。
引言
可见图像可以为计算机视觉任务提供最直观的细节。 但是,由于数据收集环境的影响,可见图像可能无法突出显示重要目标。 与可见图像不同,红外图像可以根据热辐射差异将目标与背景区分开,而不受照明和天气条件的影响。 但是,红外图像的局限性在于它们无法提供纹理细节。 因此,仅使用可见图像或红外图像不能提供足够的信息来促进计算机视觉应用,例如各种环境中的目标检测,识别和跟踪。 为了解决这个问题,多种红外和可见光图像融合方法被提出。
文章提出的算法属于多尺度变换与范数优化结合的混合算法,多尺度变换将图像分解为基础层与细节层,其中基础层控制着图像目标背景整体对比度,细节层控制着图像中细节信息。当前融合算法在基础层与细节层融合中存在以下问题:
第一:传统的基础层“权重分配”融合规则通常使融合图像在源图像中保留高像素强度的特征,而忽略全局对比度,导致融合图像无法在复杂场景(例如,汽车或路灯的夜间情况)中突出目标。
第二:对于细节层的常规融合策略旨在保留更多的源图像细节。 然而,并非所有可见光图像中的细节信息都是有效的,特别是在复杂的场景中。 因此,通过从可见图像中包含更多细节来提高融合图像的质量并不总是有帮助的。
方法论
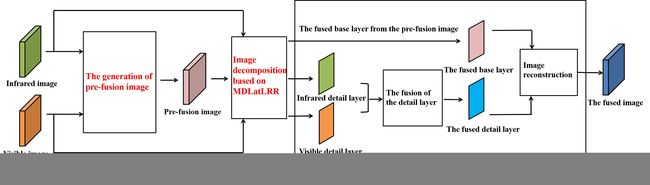
这张图三个红色部位分别是下面三个标题。
首先对红外可见图像进行预处理得到预融合图像。接着将红外图像、可见光图像与预融合图像经图像分解算法MDLatLRR分解出基础层与细节层。其中,来自预融合图像的基础层作为最终融合图像的基础层,来自红外可见图像的细节层在预融合图像的协助下融合得到最终融合图像的细节层。
预融合图像的生成
预融合图像有两个作用:
A:提高最终融合图像中目标与背景的对比度。
B:作为细节层融合中消除可见光图像无效细节信息的参考。
具体来说,预融合处理可视作一个优化问题:由对比度保真项与梯度稀疏约束项构成:
对比度保真项:f表示预融合图,Ir是红外图像。
![]()
我们希望最终融合图像保留红外图像的目标背景对比度,而不是直接跟红外图像每个像素值一模一样 (毕竟红外图像并不符合人眼视觉感知嘛) ,也就是(f-Ir)大部分区域不为0,但接近0,即我们认为(f-Ir)应当是高斯分布,采用的是L2范数。
梯度稀疏约束:
![]()
这一项是预融合图像梯度项,既考虑了红外图像,也考虑了可见光图像。显然,在νf-梯度分布上,我们当然希望是梯度可以一模一样转移到预融合图像中,也就是大部分值为0,本来用L0范数最直白了,但是L0范数是一个NP问题,所以采用L1范数来作为近似。
综合起来:
![]()
令 k = f - Ir - Vis,r = -Vis,u = 2·ρ。可得:f = k+Ir+Vis,如下形式:
梯度可拆分为水平方向与垂直方向:

最后优化函数为:

最后应用Split Bregman求该式子最小值k,可得到预融合图像f。
基于MDLatLRR的图像分解
论文中的图像分解算法参考自论文:MDLatLRR、代码来自:MDLatLRR
事实上,所谓将图像分解为高频与低频、基础层与细节层的算法,其实本质上都是拿滤波算法来进行改造的。比如:导向滤波、最小二乘法滤波、双边滤波。
基于MDLatLRR的算法本质上是利用图像的低秩性来分解图像。
秩的通俗理解:秩就是秩序,看到过别人举的一个例子:一群人排队,如果里面的人互相不认识,那么就不会让对方插队,此时该队伍就井然有序 (秩序),这时我们就称该队伍的秩序比较好 (高秩)。但是如果里面互相认识的人比较多,那么待会就会出现走后门、插队的现象发生,此时的队伍就乱成一锅粥,秩序差,也就是低秩。
线性代数中的秩:表示矩阵行列之间的相关性。行列之间的相关性越高,秩越低,矩阵行或列之间就可以互相表示。引申到图像中,就是在说图像里面的像素结构彼此的相关程度。一幅图像往往是低秩或者近似低秩的,这是因为其中的图像信息具有很大的相关性。所以一幅自然图像往往可以由其内部少部分数据表示 (这就是图像压缩)。但如果图像存在噪声,那么存在随机幅值任意大但是分布稀疏的误差就会破坏了原有数据的低秩性。
下面的图片来源于:低秩恢复算法(图像去噪)

上面的LRR将图像中的噪声E与低秩矩阵DZ分离,低秩矩阵DZ就是经过去噪的图像。基于MDLatLRR的图像分解算法将上图中式(13)改造成:多出来的L是显著系数投影矩阵。即上图的图像低秩矩阵DZ进一步被拆分为基础部分和显著部分。

以上是对图像单个尺度进行分解,引申到多尺度变换中即分解多次,每一次以上一次尺度分解得到的基础层为输入。如下图所示:

基础层与细节层的图像融合
基础层
基础层来自预融合图像经MDLatLRR图像分解算法所得的基础层。
细节层
细节层的融合过程如下:
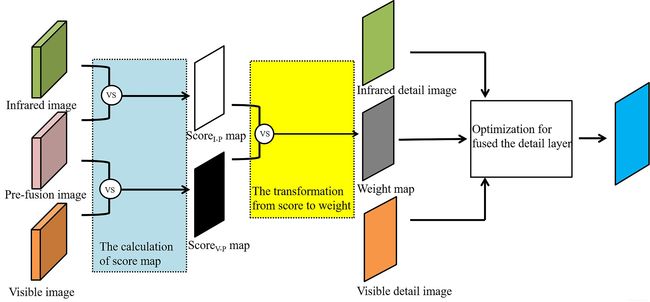
得分图的生成:
对预融合图像与红外图像、预融合图像与可见图像分别使用滑动窗口计算局部SSIM,得到Score(V-P) Map (可见与预融合图像)与Score(I-P) Map (红外与预融合图像)。
得分图到权重图的转换:
得到的两个得分图再经由如下式子:
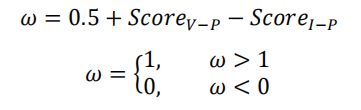
转换为以下权重图:

由于最终权重图作用于可见图像细节层中,所以权重图亮度越暗的位置代表着对应位置的可见图像细节信息权重越低。可以明显看到,不利于最终融合结果的可见光信息权重被降低了。
用于细节层融合的优化算法:
该优化过程旨在使可见光图像信息有效的地方对应在融合细节层中倾向于可见光信息,在红外图像信息有效的地方倾向红外光信息。设计出如下优化等式:
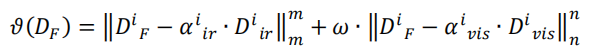
DF代表最终优化得到的融合细节层、Dir表示来自红外图像的细节层、Dvis表示来自可见图像的细节层。既然对可见光图像细节层进行了过滤,难免会影响到有效的信息,所以分别对红外可见的细节信息进行了增强,即加入增强系数αir与αvis,增强的思想是自适应局部均方差(公式见论文)。ω为上一步得到的权重图。同样的,我们希望融合细节层在红外与可见图像细节中取得一个平衡,即接近0,但不等于0,故采用的还是L2范数。
构建出上述式子后,首先证明其为凸函数,然后利用凸函数的性质: 局部最小值即为全局最小值。
这部分式子推导比较多,下面贴一下论文这部分的过程:

以上证明了优化函数为凸函数,以下求解最终优化结果:

逆变换
与其他基于多尺度变换一样,该论文的逆变换也只是简单将细节层与基础层的图像相加就行了。
B代表最终的融合基础层base layer,也就是预融合图像经过4次分解所得到的
D代表最终的融合细节层detail layer。
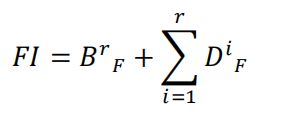
总结
第一:这篇论文与其他论文最大的不同在于融合思想的转变: 作者认为源图像的信息并不全是有效信息,不应该全部放到融合图像中。目前大多数融合论文追求的是融合图像应具有更多源图像的信息,这可以从其采用的评价指标中看出 ,大多数为有参考图像评价指标(图像结构相似度SSIM、视觉信息保真度VIF、互信息MI等)。从实验部分可以看出作者的这种思想是有效果的 (尤其对于强光)。



第二:当前红外与可见光图像融合的主流观点是:
红外光图像目标突出,但细节信息不够丰富,可见光图像细节信息丰富,但目标不够突出
对于目标突出
当前许多处理是分解红外可见光图像得到两个基础层,然后通过设计权重分配函数。特别的,图像显著性被引入到该领域中,但是对于可见光图像,显著并不等于有效,没错,最典型的还是强光信息。所以,既然红外光图像能够突出目标,而且是不受影响,是有效的,那我们直接将红外图像中目标与背景的亮度比保留下来不就行了吗???
对于细节信息
可见光图像细节信息虽然丰富,但由于环境的干扰,并非都是有效信息。相反,红外光图像细节信息虽然不够丰富,但反映的都是真实信息,这可以为细节信息的融合提供帮助。
所以基于上述两点,作者就提出了两阶段融合策略:
第一阶段:预融合,既保留红外图像目标与背景的亮度比 ( 针对第一点) , 又加入了梯度稀疏约束 (针对第二点,由于红外图像细节信息较少,所以适当加入一些可见光图像细节信息来弥补,参数ρ可用于调节所加入的可见光图像细节信息的量)。
第二阶段:细节层融合,以预融合图像为基准,分别与红外、可见图像进行局部SSIM评分。下图可明显看到强光部分在最后参与融合的权重极低,在最终融合结果中可以看到,强光信息基本被消除。最后,我们再比较一下采用了同种图像分解算法MDLatLRR,但不同融合规则的方法—MDLatLRR,以证明我们的两阶段融合策略是有效的。

对于红外可见光图像融合的思考
当前该领域虽然出现了许多基于深度学习的融合方法,但基于深度学习的融合方法并没有比传统方法好多少,原因在于这是一个无监督任务,损失函数较难设计。
如若还想在这个方向继续做下去,
我从个人看法提出如下几个方向,权当抛砖引玉:
第一:损失函数的设计是一个挑战,结合感知损失的IFCNN、结合SSIM的DenseFuse(这篇论文挺有趣的,使用COCO数据集训练了一个可用于图像分解与重建的网络,然后在中间加入人工设计规则进行融合)。
第二:从网络结构入手,比如2019年的对抗网络FusionGAN,2020年的双对抗网络DDcGAN
第三:其实本文存在的缺点就是两阶段融合所使用的时间较长,时间花费主要在于局部SSIM的计算,也就是对可见光图像信息有效性的评分,不知可否考虑转化为基于深度学习的方法呢?即自己学习给可见图像信息打分。在联想得的远一些,之前看到过一篇红外可见融合来进行行人检测的(Illumination-aware faster R-CNN for robust multispectral pedestrian
detection),其探究了低光跟强光场景下,红外可见融合中哪个贡献更大。
第四:模仿传统算法中的视觉显著性,加入注意力模块CBAM
还可以考虑一下分组卷积,显著性检测论文Deep Salient Object Detection With Contextual
Information Guidance中证明了分组卷积有利于突出重要目标。事实上确实是有道理的,传统卷积将多通道特征组合在一起处理,可能会淹没掉某些通道的特征。
第四:针对实际应用,红外可见光融合之后进行分割、检测。比如融合分割的MFNet与RTFNet
第五:也可以从评价指标入手,设计专门针对红外可见图像融合的评价指标。
第六:图像分割算法UNet网络结构采用了是4次下采样,再上采样恢复。但是UNet++作者通过做实验得出结论,4次下采样并不是对所有分割任务都有效,最后作者抓住这一点,设计了一个基于UNet的新网络,即让对应网络自己学习对应任务,需要几次下采样。最后还可以有的分割任务还可以剪枝。引申到红外可见融合尺度中,每次基于多尺度变换的传统融合算法,分解尺度总是固定的,大部分为4次分解,然后就开始对应融合了。而事实上并没有谁证明了分解4次再融合就一定是最好的,所以,我们是不是也可以通过一些实验,甚至可以结合深度学习,加入多种尺度,让算法针对不同场景的图像自适应找到一种合适的融合尺度呢?
Emmmm,就先暂时想到这里吧,有什么想法再给大家分享。
最后的最后,如果觉得本文不错,那就来个:点赞、关注、收藏吧哈哈哈。