docker搭建Elasticsearch-ik中文分词器- 安装Kibana Java中使用
前言:Elasticsearch 是一个开源的搜索引擎,建立在一个全文搜索引擎库 Apache Lucene™ 基础之上。 Lucene 可以说是当下最先进、高性能、全功能的搜索引擎库—无论是开源还是私有。
但是 Lucene 仅仅只是一个库。为了充分发挥其功能,你需要使用 Java 并将 Lucene 直接集成到应用程序中。 更糟糕的是,您可能需要获得信息检索学位才能了解其工作原理。Lucene 非常 复杂。
Elasticsearch 也是使用 Java 编写的,它的内部使用 Lucene 做索引与搜索,但是它的目的是使全文检索变得简单, 通过隐藏 Lucene 的复杂性,取而代之的提供一套简单一致的 RESTful API。
然而,Elasticsearch 不仅仅是 Lucene,并且也不仅仅只是一个全文搜索引擎。 它可以被下面这样准确的形容:
一个分布式的实时文档存储,每个字段 可以被索引与搜索
一个分布式实时分析搜索引擎
能胜任上百个服务节点的扩展,并支持 PB 级别的结构化或者非结构化数据
Elasticsearch 将所有的功能打包成一个单独的服务,这样你可以通过程序与它提供的简单的 RESTful API 进行通信, 可以使用自己喜欢的编程语言充当 web 客户端,甚至可以使用命令行(去充当这个客户端)。
就 Elasticsearch 而言,起步很简单。对于初学者来说,它预设了一些适当的默认值,并隐藏了复杂的搜索理论知识。 它 开箱即用 。只需最少的理解,你很快就能具有生产力。
中文文档官网:https://www.elastic.co/guide/cn/elasticsearch/guide/current/routing-value.html
搭建使用:Elasticsearch的镜像用7.9.0
docker pull elasticsearch:7.9.0
修改es单个节点 运行大小 启动完成
docker run -e ES_JAVA_OPTS="-Xms256m -Xmx256m" -e "discovery.type=single-node" -d --name elasticsearch -p 9200:9200 -p 9300:9300 elasticsearch:7.9.0

访问IP加端口
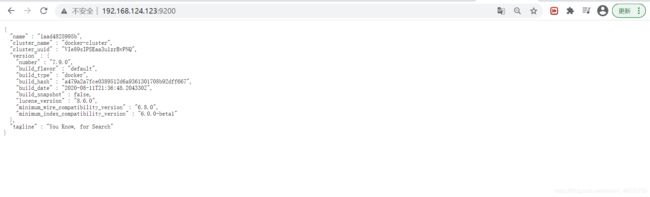
安装 ik分词器我也是用7.0.0版本的
下载地址https://github.com/medcl/elasticsearch-analysis-ik/releases

进入es的容器里
docker exec -it elasticsearch /bin/bash
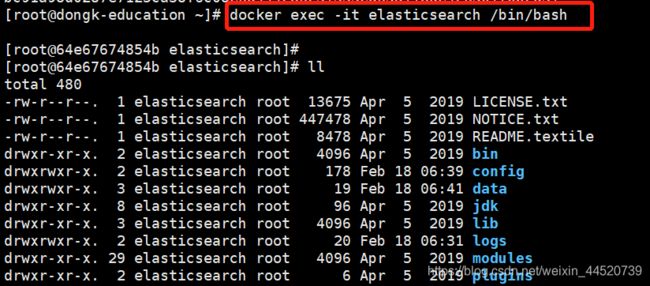
在plugins目录下创建ik文件夹:
mkdir /usr/share/elasticsearch/plugins/ik
退出容器:exit
拷贝下载好的ik分词器压缩包到ik文件夹中:
docker cp elasticsearch-analysis-ik-7.9.0.zip elasticsearch:/usr/share/elasticsearch/plugins/ik/
在进入容器
##进入容器
docker exec -it elasticsearch /bin/bash
##进入IK文件夹下
cd plugins/ik/
解压文件
unzip elasticsearch-analysis-ik-7.9.0.zip

退出容器 重启
docker restart elasticsearch
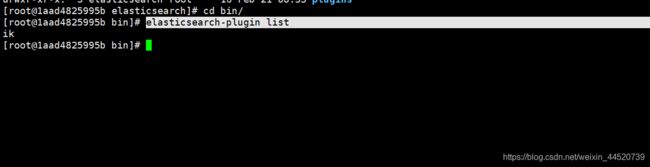
查看 ik 分词器是否安装成功 可已经进去es容器里的bin目录下
elasticsearch-plugin list
接下来安装Kibana 7 可视化工具
拉取镜像
docker pull kibana:7.9.0
启动容器
docker run -d -p 5601:5601 --name kibana --link elasticsearch:elasticsearch docker.io/kibana:7.9.0
ip加端口访问

安装之后测试一下数据是否根据官方文档提供的一个文档 新增一条
6.0版本以后就没有类型这个 只有索引 我先在是7.0但是他没报错
穿件索引 类型 数据 PUT 请求
PUT http://192.168.124.123:9200/user/test/1
修改 有就修改没有就新增 PUT 请求
PUT http://192.168.124.123:9200/user/test/1
新增修改 如果不带Id es自动生成一个字符串Id 带id修改 POST 请求
POST http://192.168.124.123:9200/user/test
删除 DELETE 请求
DELETE http://192.168.124.123:9200/user/test/1
查询 GET 请求
GET http://192.168.124.123:9200/user/test/1

查看es索引

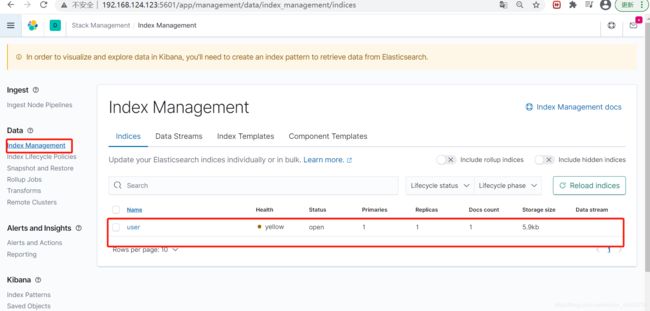
先说一下 查询 条件
(1) 获取所有数据 :索引/类型/_search
空搜索,它没有任何查询条件,查询集群中的所有索引,默认返回前10个文档。
①took:整个搜索请求耗费了多少毫秒。
②timed_out:是否超时,false是没有,默认无timeout
1)默认情况下,搜索请求不会超时。如果响应时间比完成结果更重要,你可以指定 timeout 为 10 或者 10ms(10毫秒),或者 1s(1秒):
2)GET /_search?timeout=10ms
3)timeout 不是停止执行查询,它仅仅是告知正在协调的节点返回到目前为止收集的结果并且关闭连接。
③_shards:分片数量
④hits.total:本次搜索,返回了几条结果
⑤hits.max_score:score的含义,就是document对于一个search的相关度的匹配分数,越相关,就越匹配,分数也高
⑥hits.hits:包含了匹配搜索的document的详细数据,默认查询前10条数据,按_score降序排序
⑦多索引,多类型
1)/_search:在所有的索引中搜索所有的类型
2)/gb/_search:在 gb 索引中搜索所有的类型
3)/gb,us/_search:在 gb 和 us 索引中搜索所有的文档
4)/g*,u*/_search:在任何以 g 或者 u 开头的索引中搜索所有的类型
5)/gb/user/_search:在 gb 索引中搜索 user 类型
6)/gb,us/user,tweet/_search:在 gb 和 us 索引中搜索 user 和 tweet 类型
7)/_all/user,tweet/_search:在所有的索引中搜索 user 和 tweet 类型
用Kibana 操作

range 查询找出那些落在指定区间内的数字或者时间:
①gt大于
②gte大于等于
③lt小于
④lte小于等于
(2)term 查询:
term 查询被用于精确值匹配,这些精确值可能是数字、时间、布尔或者那些 not_analyzed 的字符串
(3)terms 查询:
terms 查询和 term 查询一样,但它允许你指定多值进行匹配。如果这个字段包含了指定值中的任何一个值,那么这个文档满足条件
(4)exists 查询和 missing 查询:
exists 查询和 missing 查询被用于查找那些指定字段中有值或无值的文档。
(5)bool查询 : 用于多字段组合查询
①must:文档 必须 匹配这些条件才能被包含进来。
②must_not:文档 必须不 匹配这些条件才能被包含进来。
③should:如果满足这些语句中的任意语句,将增加 _score ,否则,无任何影响。它们主要用于修正每个文档的相关性得分。
④filter:必须 匹配,但它以不评分、过滤模式来进行。
##match_all:返回所有文档
GET _search
{
"query": {
"match_all": {
}
}
}
##查询user索引中所有的数据
GET /user/_search
##查询user索引下employee类型中所有的数据
GET /user/employee/_search
##term 查询被用于精确值匹配,这些精确值可能是数字、时间
GET /user/employee/_search
{
"query": {
"term": {
"first_name":"张"
}
}
}
## 精确查询
GET /user/employee/_search
{
"query": {
"match": {
"first_name":"张"
}
}
}
## match_phrase:短语匹配查询 必须完全匹配才返回
GET /user/employee/_search
{
"query": {
"match_phrase": {
"first_name":"张"
}
}
}
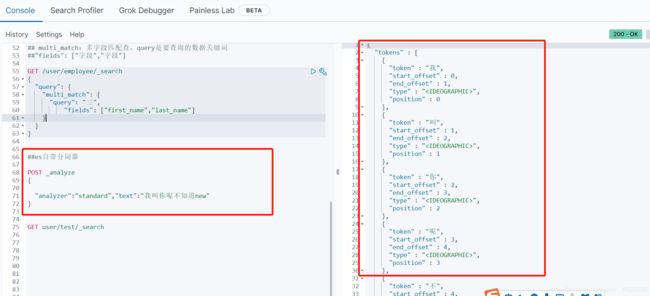
## multi_match:多字段匹配查,query是要查询的数据关键词
##"fields": ["字段","字段"]
GET /user/employee/_search
{
"query": {
"multi_match": {
"query": "三",
"fields": ["first_name","last_name"]
}
}
}
当然还有聚合函数 这些按照es的 官方文档就可以
使用ik 分词器查询
使用es自带分词器
##es自带分词器
POST _analyze
{
"analyzer":"standard","text":"我叫你呢不知道new"
}
IK分词器,支持两种算法。分别为:
ik_smart :最少切分
ik_max_word :最细粒度切分
##es使用 IK分词器
POST _analyze
{
"analyzer":"ik_smart","text":"我叫你呢不知道new"
}

搭建好在项目中使用
springboot
pom依赖
我安装的es是7.9.0的所以依赖也是7.9.0 这 里注意springboot的版本必须2.2以上的版本
<!-- https://mvnrepository.com/artifact/org.elasticsearch.client/elasticsearch-rest-high-level-client -->
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
<version>7.9.0</version>
</dependency>
pom文件
注意 : <!--指定Springboot的es版本-->
<elasticsearch.version>7.9.0</elasticsearch.version>
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.3.9.RELEASE</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
<groupId>com.example</groupId>
<artifactId>demo</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>demo</name>
<description>Demo project for Spring Boot</description>
<properties>
<java.version>1.8</java.version>
<!--指定Springboot的es版本-->
<elasticsearch.version>7.9.0</elasticsearch.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
<version>7.9.0</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
<exclusions>
<exclusion>
<groupId>org.junit.vintage</groupId>
<artifactId>junit-vintage-engine</artifactId>
</exclusion>
</exclusions>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>
</project>
config文件
package com.tang.cloud.config;
import org.apache.http.HttpHost;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestHighLevelClient;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class EsConfig {
//设置项
public static final RequestOptions COMMON_OPTIONS;
static {
RequestOptions.Builder builder = RequestOptions.DEFAULT.toBuilder();
COMMON_OPTIONS = builder.build();
}
@Bean
public RestHighLevelClient restHighLevelClient() {
RestHighLevelClient restHighLevelClient = new RestHighLevelClient(
RestClient.builder(
new HttpHost("192.168.124.123", 9200, "http")
)
);
return restHighLevelClient;
}
}
对es 操作
注入RestHighLevelClient 对es操作
@Autowired
private RestHighLevelClient client;
新增索引
@Test
public void test() throws IOException {
//创建索引
IndexRequest indexRequest = new IndexRequest("user");
//设置id
indexRequest.id("1");
//创建user对象
User user=new User();
user.setName("张三");
user.setAge(18);
user.setSex("男");
String userJson = JSON.toJSONString(user );
//创建索引
indexRequest.source(userJson,XContentType.JSON);
IndexResponse index = client.index(indexRequest, EsConfig.COMMON_OPTIONS);
System.out.println(index);
System.out.println("ok");
}
查询
GET /user/_search

查询
按id查询
//按 id查询
@Test
public void test2() throws IOException {
//创建es检索查询条件
GetRequest getRequest = new GetRequest(
"user", //索引名称
"1"); //文档id
GetResponse getResponse = client.get(getRequest, RequestOptions.DEFAULT);
String s = JSON.toJSONString(getResponse.getSource());
System.out.println(s);
User user=JSON.parseObject(s,User.class);
System.out.println(user+"测试结果");
}
查看索引是不是存在
//查看索引是不是存在 boolean类型
@Test
public void indexExists() throws IOException {
GetIndexRequest request = new GetIndexRequest("user");
boolean exists = client.indices().exists(request, RequestOptions.DEFAULT);
System.out.println(exists);
}
查询文档是是否存在
//查询文档是是否存在 返回boolean类型
@Test
public void test3() throws IOException {
GetRequest getRequest = new GetRequest(
"user", //索引
"1"); //文档id
getRequest.fetchSourceContext(new FetchSourceContext(false)); //禁用fetching _source.
getRequest.storedFields("_none_");
boolean exists = client.exists(getRequest, RequestOptions.DEFAULT);
System.out.println(exists);
}
query查询
@Test
public void test1() throws IOException {
//创建检索
SearchRequest searchRequest =new SearchRequest();
//要检索的索引
searchRequest.indices("user");
//指定检索条件
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
//使用 match 查询
searchSourceBuilder.query(QueryBuilders.matchQuery("name","张"));
searchRequest.source(searchSourceBuilder);
//开始检索
SearchResponse search = client.search(searchRequest, EsConfig.COMMON_OPTIONS);
//获取检索的数据
SearchHits hits = search.getHits();
//获取对象
SearchHit[] hits1 = hits.getHits();
for (SearchHit s:hits1) {
String sourceAsString = s.getSourceAsString();
User user = JSON.parseObject(sourceAsString, User.class);
System.out.println(user);
}
}

封装工具类
@Slf4j
@Component
public class RestHighLevelClientUtil {
@Qualifier("restHighLevelClient")
@Autowired
private RestHighLevelClient client;
@Autowired
private ObjectMapper mapper;
/**
* 创建索引
* @param indexName
* @param settings
* @param mapping
* @return
* @throws IOException
*/
public CreateIndexResponse createIndex(String indexName, String settings, String mapping) throws IOException {
CreateIndexRequest request = new CreateIndexRequest(indexName);
if (null != settings && !"".equals(settings)) {
request.settings(settings, XContentType.JSON);
}
if (null != mapping && !"".equals(mapping)) {
request.mapping(mapping, XContentType.JSON);
}
// 同步方式创建索引
return client.indices().create(request, RequestOptions.DEFAULT);
}
/**
* 删除索引
* @param indexNames
* @return
* @throws IOException
*/
public AcknowledgedResponse deleteIndex(String ... indexNames) throws IOException{
DeleteIndexRequest request = new DeleteIndexRequest(indexNames);
return client.indices().delete(request, RequestOptions.DEFAULT);
}
/**
* 判断 index 是否存在
* @param indexName
* @return
* @throws IOException
*/
public boolean indexExists(String indexName) throws IOException {
GetIndexRequest request = new GetIndexRequest(indexName);
return client.indices().exists(request, RequestOptions.DEFAULT);
}
/**
* 简单模糊匹配 默认分页为 0,10
* @param field
* @param key
* @param page
* @param size
* @param indexNames
* @return
* @throws IOException
*/
public SearchResponse searchPage(String field, String key, int page, int size, String[] includeFields, String[] excludeFields, String ... indexNames) throws IOException{
SearchRequest request = new SearchRequest(indexNames);
SearchSourceBuilder builder = new SearchSourceBuilder();
builder.query(new MatchQueryBuilder(field, key))
.from(page)
.size(size);
if (includeFields.length != 0 && excludeFields.length !=0) {
builder.fetchSource(includeFields, excludeFields);
}
request.source(builder);
return client.search(request, RequestOptions.DEFAULT);
}
/**
* 使用scroll查询所有符合条件的不分页
* @param field
* @param key
* @param includeFields
* @param excludeFields
* @param indexNames
* @return
* @throws IOException
*/
public List<SearchHit> searchAllByMatch(String field, String key, String[] includeFields, String[] excludeFields, String ... indexNames) throws IOException{
// 建立查询请求
SearchRequest request = new SearchRequest(indexNames);
SearchSourceBuilder builder = new SearchSourceBuilder();
builder.query(new MatchQueryBuilder(field, key));
if (includeFields.length != 0 && excludeFields.length !=0) {
builder.fetchSource(includeFields, excludeFields);
}
request.source(builder);
return this.searchAllByScroll(request);
}
public List<SearchHit> searchAllByWildcard(String field, String key, String[] includeFields, String[] excludeFields, String ... indexNames) throws IOException{
// 建立查询请求
SearchRequest request = new SearchRequest(indexNames);
SearchSourceBuilder builder = new SearchSourceBuilder();
// builder.query(new MatchQueryBuilder(field, key));
builder.query(new WildcardQueryBuilder(field, "*" + key + "*"));
if (includeFields.length != 0 && excludeFields.length !=0) {
builder.fetchSource(includeFields, excludeFields);
}
request.source(builder);
return this.searchAllByScroll(request);
}
/**
* 针对查询请求,通过 Scroll 查询所有,不分页
* @param request 查询请求
* @return
*/
public List<SearchHit> searchAllByScroll(SearchRequest request) throws IOException {
request.scroll(TimeValue.timeValueSeconds(10));
List<SearchHit> searchHitList = new ArrayList<>();
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
String scrollId = response.getScrollId();
SearchHit[] searchHits = response.getHits().getHits();
while (searchHits != null && searchHits.length > 0) {
searchHitList.addAll(Arrays.asList(searchHits));
response = client.scroll(new SearchScrollRequest(scrollId).scroll(TimeValue.timeValueSeconds(10)), RequestOptions.DEFAULT);
scrollId = response.getScrollId();
searchHits = response.getHits().getHits();
}
ClearScrollRequest clearScrollRequest = new ClearScrollRequest();
clearScrollRequest.addScrollId(scrollId);
ClearScrollResponse clearScrollResponse = client.clearScroll(clearScrollRequest, RequestOptions.DEFAULT);
boolean succeeded = clearScrollResponse.isSucceeded();
System.out.println("clearScroll: " + succeeded);
return searchHitList;
}
public SearchResponse search(String field, String key, String rangeField, String from, String to,
String termField, String termVal, String ... indexNames) throws IOException{
SearchRequest request = new SearchRequest(indexNames);
SearchSourceBuilder builder = new SearchSourceBuilder();
BoolQueryBuilder boolQueryBuilder = new BoolQueryBuilder();
boolQueryBuilder.must(new MatchQueryBuilder(field, key)).must(new RangeQueryBuilder(rangeField).from(from).to(to)).must(new TermQueryBuilder(termField, termVal));
builder.query(boolQueryBuilder);
request.source(builder);
log.info("[搜索语句为:{}]",request.source().toString());
return client.search(request, RequestOptions.DEFAULT);
}
/**
* term 查询 精准匹配
* @param field
* @param key
* @param page
* @param size
* @param indexNames
* @return
* @throws IOException
*/
public SearchResponse termSearch(String field, String key, int page, int size, String ... indexNames) throws IOException{
SearchRequest request = new SearchRequest(indexNames);
SearchSourceBuilder builder = new SearchSourceBuilder();
builder.query(QueryBuilders.termsQuery(field, key))
.from(page)
.size(size);
request.source(builder);
return client.search(request, RequestOptions.DEFAULT);
}
/**
* 批量导入
* @param indexName
* @param sourceList
* @return
* @throws IOException
*/
public BulkResponse importAll(String indexName, List<String> sourceList) throws IOException{
if (0 == sourceList.size()){
//todo 抛出异常 导入数据为空
}
BulkRequest request = new BulkRequest();
for (String source : sourceList) {
request.add(new IndexRequest(indexName).source(source, XContentType.JSON));
}
return client.bulk(request, RequestOptions.DEFAULT);
}
/**
* 插入或者更新
* @param indexName
* @param jsonMap
* @return
* @throws IOException
*/
public IndexResponse insertOrUpdateOne(String indexName, String id, Map<String, Object> jsonMap) throws IOException {
IndexRequest request = new IndexRequest(indexName);
request.id(id);
request.source(jsonMap);
return client.index(request, RequestOptions.DEFAULT);
}
public DeleteResponse deleteDocumentById(String indexName, String id) throws IOException {
DeleteRequest request = new DeleteRequest(indexName, id);
return client.delete(request, RequestOptions.DEFAULT);
}
}
更多操作 查看官方 文档
https://www.elastic.co/guide/en/elasticsearch/client/java-api/7.11/java-docs-get.html
倒排索引
https://lesliefish.blog.csdn.net/article/details/49648363?utm_medium=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-7.control&dist_request_id=a74b41a9-38fb-45f7-80f1-b4bb059093f8&depth_1-utm_source=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-7.control