索引优化分析
join查询
SQL执行顺序
mysql 从 FROM 开始执行~
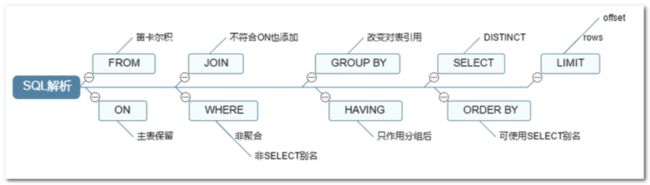
join连接查询

7 种 JOIN 示例
建表
- tbl_dept 表结构(部门表)
mysql> select * from tbl_dept;
+----+----------+--------+
| id | deptName | locAdd |
+----+----------+--------+
| 1 | RD | 11 |
| 2 | HR | 12 |
| 3 | MK | 13 |
| 4 | MIS | 14 |
| 5 | FD | 15 |
+----+----------+--------+
5 rows in set (0.00 sec)- tbl_emp 表结构(员工表)
mysql> select * from tbl_emp;
+----+------+--------+
| id | NAME | deptId |
+----+------+--------+
| 1 | z3 | 1 |
| 2 | z4 | 1 |
| 3 | z5 | 1 |
| 4 | w5 | 2 |
| 5 | w6 | 2 |
| 6 | s7 | 3 |
| 7 | s8 | 4 |
| 8 | s9 | 51 |
+----+------+--------+
8 rows in set (0.00 sec)笛卡尔积
- tbl_emp 表和 tbl_dept 表的笛卡尔乘积:
select * from tbl_emp, tbl_dept; - 其结果集的个数为:5 * 8 = 40
inner join
tbl_emp 表和 tbl_dept 的交集部分(公共部分)
select * from tbl_emp e inner join tbl_dept d on e.deptId = d.id;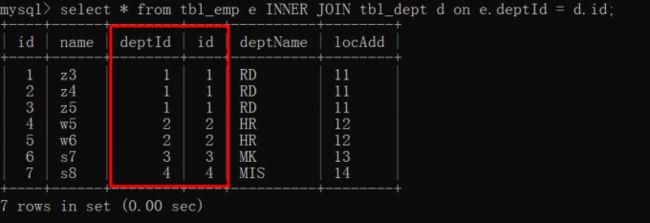
员工表的部门编号 和 部门表的id编号,就是他们的公共部分。
left join
tbl_emp 与 tbl_dept 的公共部分 + tbl_emp 表的独有部分
select * from tbl_emp e left join tbl_dept d on e.deptId = d.id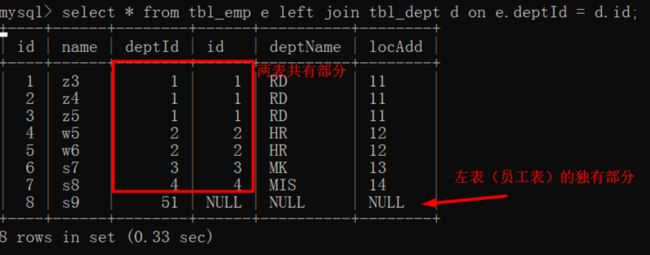
right join
tbl_emp 与 tbl_dept 的公共部分 + tbl_dept 表的独有部分
select * from tbl_emp e right join tbl_dept d on e.deptId = d.id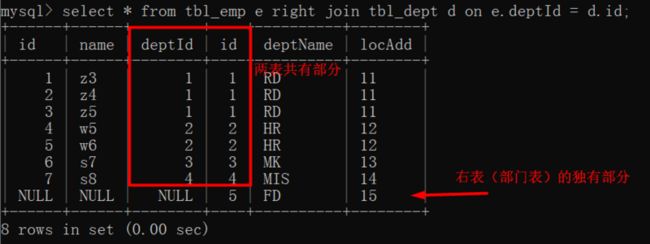
left join without common part
tbl_emp 表的独有部分。
员工表要独占,有部门表什么事吗?所以用where d.id is null去掉部门表的内容即可。
select * from tbl_emp e left join tbl_dept d on e.deptId = d.id where d.id is null
right join without common part
tbl_dept 表的独有部分。
部门表要独占,有员工表什么事吗?所以用where e.deptId is null去掉员工表的内容即可。
select * from tbl_emp e right join tbl_dept d on e.deptId = d.id where e.deptId is null
full join
- MySQL不支持full join,但是我们可以用union关键字连接结果集,并且自动去重。
- 将 left join 的结果集和 right join 的结果集使用 union 合并即可
select * from tbl_emp e left join tbl_dept d on e.deptId = d.id
union
select * from tbl_emp e right join tbl_dept d on e.deptId = d.id;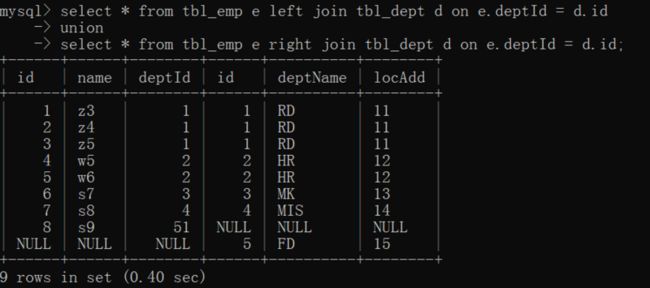
full join without common part
tbl_emp 表的独有部分 + tbl_dept表的独有部分。
select * from tbl_emp e left join tbl_dept d on e.deptId = d.id where d.id is null
union
select * from tbl_emp e right join tbl_dept d on e.deptId = d.id where e.deptId is null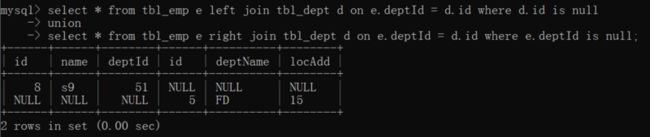
索引简介
索引是什么
- MySQL官方对索引的定义:索引是帮助MySQL高效获取数据的数据结构。
- 简单理解为“排好序的快速查找的数据结构”,索引 = 排序 + 查找
- 一般来说索引本身占用内存空间很大,因此索引往往以文件形式存储在硬盘上
- 我们平时所说的索引,如果没有特别指明,都是指B树(多路搜索树)结构组织的索引。
- 聚集索引,次要索引,覆盖索引,复合索引,前缀索引,唯一索引默认都是使用B+树索引,统称索引。除了B+树这种类型的索引之外,还有哈希索引(hash index)等。
索引原理
- 索引以某种方式指向数据,这样就可以在这些数据结构上实现高级查找算法。
下图就是一种可能的索引方式:
为了加快col2的查找,可以维护右边所示的二叉查找树,每个节点分别包含索引键值和一个指向对应数据物理地址的指针。

索引优劣势
优势
- 快速找到数据,降低数据库的IO成本
- 通过索引列对数据进行排序,降低数据排序成本,降低了CPU的消耗
劣势
- 实际上索引也是一张表,该表保存了主键和索引字段,并指向实体表的记录,所以索引列也是要占用空间的
- 以表中的数据进行增、删、改的时候,索引也要动态的维护,这就降低了更新表的速度。
MySQL索引分类
- 单值索引:最基本的索引,即一个索引只包含单个列,一个表可以有多个单列索引。(建议一张表索引不超过5个,优先考虑复合索引)
- 唯一索引:索引列的值必须唯一,但允许有空值。(例如:身份证号不能重复)
- 复合索引:即一个索引包含多个列。
- 主键索引:一个表只能有一个主键,不允许有空值。一般是在建表的时候同时创建主键。
- 全文索引:主要用来查找文本中的关键字,而不是直接与索引中的值相比较。fulltext索引跟其它索引大不相同,它更像是一个搜索引擎,而不是简单的where语句的参数匹配。
MySQL索引结构
- BTree索引
- Hash索引
- full-text索引(全文索引)
- R-Tree索引(空间索引)
索引实现是用
B+Tree,MySQL中看到的索引
index_type=BTree也就是个索引类型的名词;而真正的底层实现是用的B+tree
为什么不用hash表结构?
- hash的值是无序的值,不能进行范围查找。如果要排序操作,也不能用哈希值去排序。
为什么不用平衡二叉树结构?
- 随着树的高度增加,查找速度会越来越慢。而且范围查询是在二叉树间 回旋查找,速度也不快
为什么不用B树结构?
- 高度相比于平衡二叉树矮,查找速度会更快。但是范围查询会 回旋查找 的问题依然存在。
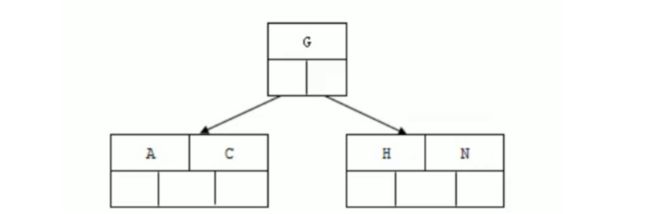
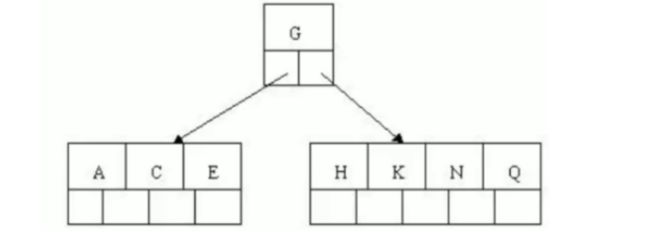
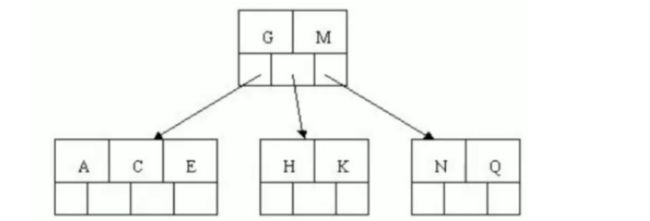
BTree结构
BTree又叫多路平衡搜索树,以5叉BTree为例,当k元素大于4时,中间节点分裂到父结点,两边节点分裂。
插入 C N G A H E K Q M数据为例:
- 因为key最大为4,我们先插入4个
- 然后插入H,H根据大小放在G和N中间,这时n>4,中间元素G向上分裂为父节点,两边节点分裂。
- 插入E,K,Q不需要分裂
- 插入M,中间元素M向上分裂到父结点G
BTREE树和二叉树相比,查询数据的效率更高,因为对于相同的数据量来说,BTREE的层级结构比二叉树小,因此搜索速度快。(二分查找)

B+TREE结构
B+Tree 与 BTree 的区别
- B+Tree只有叶子节点上存放数据,非叶子节点存放索引就行
- B+Tree的叶子节点间还有一个链表将所有的叶子节点连接起来,方便遍历
- BTree中所有节点都有索引和数据,这样带来的问题是,如果数据过大,会影响索引的存储,从而可能深度会更高,影响I/O的读取效率。
B+树的查询效率更加稳定
- 在BTree中,越靠近根节点的记录查找时间越快。
而B+Tree中每个记录的查找时间基本是一致的,都需要从根节点走到叶子节点。
- 在BTree中,越靠近根节点的记录查找时间越快。
B+树的磁盘读写代价更低
- 但是在实际应用中却是B+Tree性能比较好,因为B+Tree的非叶子节点不存放数据,这样每个节点可容纳的元素就比BTree多,树高就比BTree小,这样的好处是减少磁盘访问次数(一次磁盘访问的时间相当于成百上千次内存比较的时间)。
- 而且B+树的叶子节点使用指针连接在一起,方便顺序遍历(范围搜索)
聚簇索引和非聚簇索引
聚簇索引(InnoDB)
- 将数据存储与索引放到一块,索引结构的叶子节点保存了行数据。表数据安装索引的顺序来存储,也就是说索引的顺序和表中记录的顺序一致。
- InnoDB中,在聚簇索引之上创建的索引被称为辅助索引,像复合索引,前缀索引,唯一索引等等。
聚簇索引默认是主键,如果表中没有主键,InnoDB会选择一个唯一的非空索引代替,如果没有,InnoDB会在内部生成一个隐式的聚簇索引。
非聚簇索引(MyISAM)
将数据与索引分开,表数据记录顺序与索引顺序无关。
MyISAM索引查询数据过程
- 非聚簇索引的索引和数据是分开的,有两个文件。
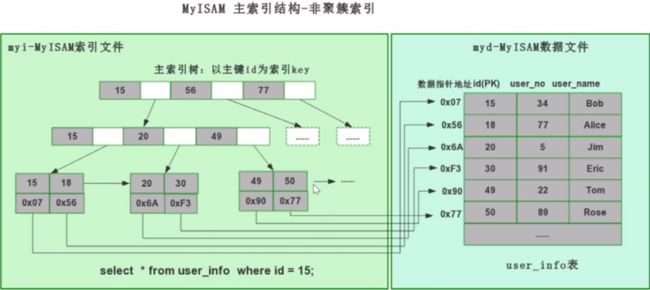
- B+树的每一个节点就是我们的主键id,最后一层是叶子节点,叶子节点上面存储的是数据的物理地址。通过地址在数据文件里面查询相应的数据。
InnoDB索引查询数据过程
- 聚簇索引的索引和数据是存储到同一个文件里面的。

- 左边的是一个主键索引,也叫聚簇索引。右边的是一个辅助索引。
- 聚簇索引:B+树的每一个节点就是我们的主键id,最后一层是叶子节点,叶子节点上存储的是真实的数据。例如我查找id等于15,我找到这个叶子节点后,能把id=15这一行的数据全部拿出来。
- 辅助索引:以name字段为索引,B+树的每一个节点,存储的是相应的名字,但是叶子节点上存储的是主键id值,这就是聚簇索引和辅助索引的区别。然后通过主键的id值,去聚簇索引上查找相应的数据。
- 如果查询语句是 select * from table where ID = 21,即主键查询的方式,则只需要搜索 ID 这棵 B+树。
- 如果查询语句是 select * from table where name='hce',即非主键的查询方式,则先搜索 name索引树 ,得到ID,再到ID索引树搜索一次,这个过程也被称为回表。
从图中不难看出,主键索引和非主键索引的区别是:非主键索引的叶子节点存放的是 主键的值,而主键索引的叶子节点存放的是 整行数据,其中非主键索引也被称为 辅助(二级)索引,而主键索引也被称为 聚簇索引。
索引的创建与否
哪些情况下适合建立索引
- 主键自动建立唯一索引
- 频繁作为查询的条件的字段应该创建索引
- 查询中与其他表关联的字段,外键关系建立索引
哪些情况不适合建立索引
- 表记录太少
- 更新太频繁地字段不适合创建索引,除了更新数据,还会自动的更新索引。
- Where条件里用不到的字段不创建索引
唯一性太差的字段不适合建立索引(例如登录状态,性别字段)
例如性别字段,因为只有两个值,比较很简单,排序也方便,加索引所消耗的系统资源比不加更多。
意味着索引的二叉树级别少,多是平级。这样的二叉树查找无异于全表扫描。
性能分析
MySQL常见瓶颈
CPU:CPU饱和的时候,一般发生在数据装入在内存或从磁盘上读取数据的时候
IO:磁盘I/O瓶颈发生在 装入数据远大于内存容量的时候
服务器硬件的性能瓶颈:top、free、iostat和vmstat来查看系统的性能状态
Explain详解
适用Explain可以模拟优化器执行SQL语句,从而知道MySQL是如何处理这条SQL语句的。
explain select * from tbl_emp;
字段解释:
id(表示查询中执行select子句或操作表的顺序)
- id相同,执行顺序由上至下
- id不同,如果是子查询,id序号会递增。id值越大优先级越高,越先被执行。
select_type(查询的类型)
- simple:简单的select查询
- primary:如果包含任何复杂的子部分,最外层查询被标记为primary
- subquery:在select或where列表中包含了子查询
- derived:在FROM列表中包含的子查询被标记为derived(衍生)
- union:若第二个select出现在union之后,则被标记为UNION;若UNION包含在FROM子句的子查询中,外层select将被标记为:DERIVED
- union result:从UNION表获取结果的select
- table(显示这一行的数据是哪张表的)
type(访问类型排列)
- 从最好到最差依次是:
system > const > eq_ref > ref > range> index > ALL - system:表只有一行记录,这是const类型的特例,平时不会出现
- const:表示通过索引一次就找到了
- eq_ref:唯一性索引,常见于主键或唯一索引扫描
- ref:非唯一索引扫描
- range:只检索给定范围的行,使用一个索引来选择行,一般是where中出现了
between,<,>,in等 - index:从索引中读取全表
- all:从硬盘数据库文件中读取全表
- 从最好到最差依次是:
- possible_keys(显示可能应用在这张表中的索引,一个或多个)
- key(实际使用的索引,如果为null,则没有使用索引)
- key_len(key_len显示的值为索引最大可能长度,并非实际使用长度)
- ref(显示索引哪一列被使用了)
- rows(估算出找到所需的记录所需要读取的行数)
Extra(包含不适合在其他列中显示但十分重要的额外信息)
- Using filesort 文件排序:MySQL无法利用索引完成排序,需要尽快优化!
- Using temporary 创建临时表:使用了临时表保存中间结果,需要尽快优化!!
- Using index 覆盖索引:表示相应的select操作中使用了覆盖索引,避免访问了表的数据行,效率不错
- Using where :表明使用了WHERE过滤
- Using join buffer:表明使用了连接缓存
- impossible where:where子句的值总是false,不能用来获取任何元组
索引失效
建表SQL
CREATE TABLE staffs(
id INT PRIMARY KEY AUTO_INCREMENT,
`name` VARCHAR(24)NOT NULL DEFAULT'' COMMENT'姓名',
`age` INT NOT NULL DEFAULT 0 COMMENT'年龄',
`pos` VARCHAR(20) NOT NULL DEFAULT'' COMMENT'职位',
`add_time` TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT'入职时间'
)CHARSET utf8 COMMENT'员工记录表';
INSERT INTO staffs(`name`,`age`,`pos`,`add_time`) VALUES('z3',22,'manager',NOW());
INSERT INTO staffs(`name`,`age`,`pos`,`add_time`) VALUES('July',23,'dev',NOW());
INSERT INTO staffs(`name`,`age`,`pos`,`add_time`) VALUES('2000',23,'dev',NOW());
# 创建索引
ALTER TABLE staffs ADD INDEX index_staffs_nameAgePos(`name`,`age`,`pos`);索引失效判断准则
要遵循最左前缀法则
- 查询从索引的最左前列开始,并且不跳过索引中的列。例如我们创建了复合索引
(name,age,pos),WHERE查询时,要从name开始;如果只查询pos是不走索引的。 - 和WHERE后面的顺序无关
- 跳过中间的age也会走索引,但是因为违反了最左前缀法则,实际只走了name索引。
- 查询从索引的最左前列开始,并且不跳过索引中的列。例如我们创建了复合索引
在索引列上进行任何操作,会导致索引失效
- 包含 计算、使用函数、类型转换等
- 例如使用
substring函数 截取子串。
- 使用is null,is not null 可能索引失效
%或者_开头的Like模糊查询,索引失效- 只要不是放在头部,放在其他地方索引不会失效
- 解决办法:使用覆盖索引
- 使用or,如果有部分条件没有索引,索引都失效
- 使用不等于
!=、<>,当前的索引会失效 - 如果是var类型的数字,查询时要用单引号括起来,不然会自动类型转换,使得索引失效。
尽量使用 覆盖索引(只访问索引的查询(索引列和查询列一致)),减少select*好处:如果一个索引包含所有需要的查询的字段的值,直接根据索引的查询结果返回数据,而无需对比,能够极大的提高性能。
索引的案例分析
- test03表中的测试数据
mysql> select * from test03;
+----+------+------+------+------+------+
| id | c1 | c2 | c3 | c4 | c5 |
+----+------+------+------+------+------+
| 1 | a1 | a2 | a3 | a4 | a5 |
| 2 | b1 | b2 | b3 | b4 | b5 |
| 3 | c1 | c2 | c3 | c4 | c5 |
| 4 | d1 | d2 | d3 | d4 | d5 |
| 5 | e1 | e2 | e3 | e4 | e5 |
+----+------+------+------+------+------+
5 rows in set (0.00 sec)#给test03表创建索引
create index idx_test03_c1234 on test03(c1,c2,c3,c4);我们创建了复合索引idx_test03_c1234,根据以下SQL分析下索引使用情况?
SELECT * FROM test03 WHERE c1='a1' AND c2='a2' AND c3='a3' AND c4='a4';- 全值匹配,索引全生效
SELECT * FROM test03 WHERE c4='a4' AND c3='a3' AND c2='a2' AND c1='a1';- 虽然顺序不同,但是mysql的优化器会进行优化,索引全生效
SELECT * FROM test03 WHERE c1='a1' AND c2='a2' AND c3>'a3' AND c4='a4';- c3列字段使用了索引进行排序,没有进行查找,导致c4无法用索引进行查找。使用到了3个索引,其中一个用于排序。(范围之后全失效)
SELECT * FROM test03 WHERE c1='a1' AND c2='a2' AND c4='a4' ORDER BY c3;- 和上面相似,c3字段将索引用于排序,c4列没用到索引。
SELECT * FROM test03 WHERE c1='a1' AND c2='a2' ORDER BY c4;- 索引在c3处断了,c4的排序没用到索引,显示了Using filesort(文件排序),必须优化
SELECT * FROM test03 WHERE c1='a1' ORDER BY c2, c3;- 只用到了c1索引,但是c2、c3用于排序且顺序正确。无filesort
SELECT * FROM test03 WHERE c1='a1' ORDER BY c3, c2;- 出现了filesort,我们建的索引是1234,它没有按照顺序来,32颠倒了
SELECT * FROM test03 WHERE c1='a1' AND c2='a2' ORDER BY c3, c2;- 为什么c3, c2颠倒了但是没有出现filesort?
- 因为查询条件
c2='a2',我都把c2查询出来了,就不用排序了。使用了3个索引,1个用于给c3排序。
group by表面上叫分组,分组之前必排序,group by 和 order by 在索引上的问题基本是一样的。
SELECT * FROM test03 WHERE c1='a1' and c2 like '%kk';- 只使用到了c1索引,c2索引失效了
SELECT * FROM test03 WHERE c1='a1' and c2 like 'k%k%';- 使用到了c1和c2索引,因为不是以%开头的,可以理解为常量。
索引失效的底层原理

- 索引失效的情况主要是针对复合索引。
- 左边的值是有顺序的:112233
右边的值是没有顺序的:121412
因为排序是先排左边的a索引,只有在a相等的情况下,b索引才是有序的。
- 如果不遵循最左前缀原则,在没有a的情况下,b肯定是无序的。就不能在一个无序的B+树上面找到需要的值。
- 如果使用范围查找,
a>1 and b=1。当我们找到a>1的索引后,b索引是没有序的,就不能通过二分查找找到。(范围后面的失效,这个后面是看联合索引的顺序的)