excel poi 的xml配置_手把手教你JSON解析完Cube数据,如何输出到Excel
最近公司有一个需求,需要解析Kylin上某个Cube的JSON格式的数据,并输出到Excel文件中。
我们先来看看这个Cube内部都有些什么?
这里我以其中一个JSON文件为例
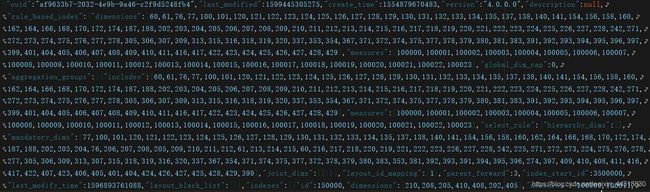
是不是JSON内部的层级关系有点混乱,没关系,我们将里面的内容放到网页上去解析看看。
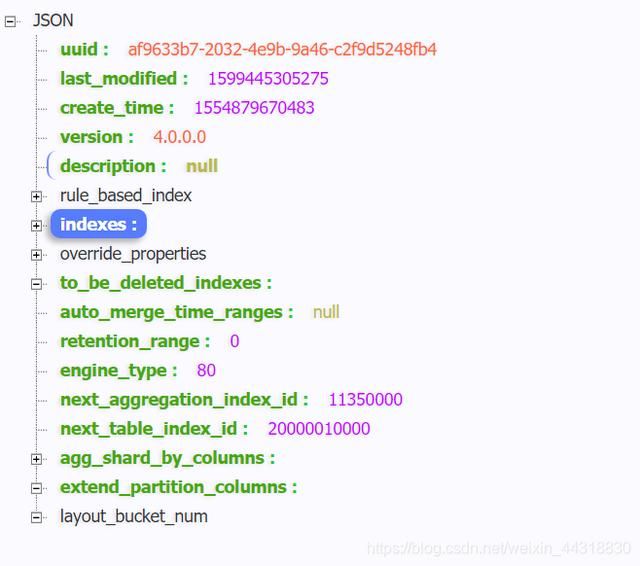
我们想要操作的是 key值为 indexes下的数组,并对 key = layouts 下的 id 和col_order集合 拿出来,并对col_order集合中的元素做一个过滤,只获取其中 < 100000的元素,并将其输出到 Excel 文件中。
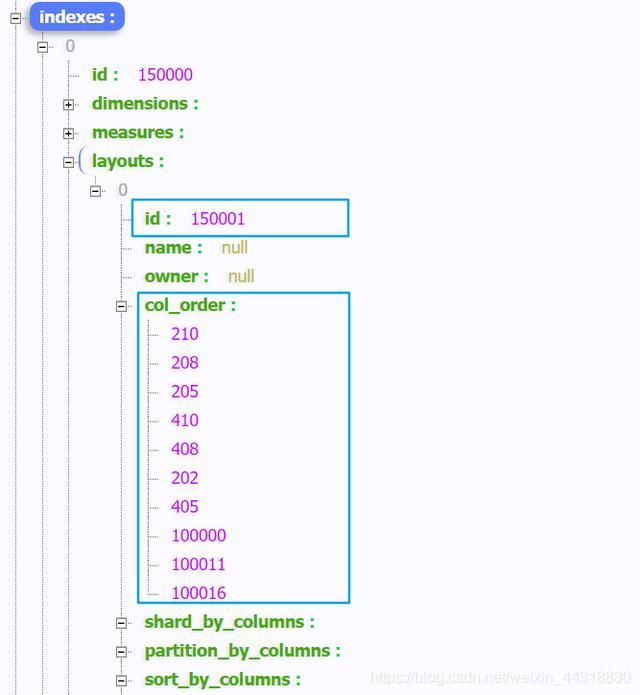
现在似乎需求已经看懂了,那我们就开始上手代码吧。

首先我们先创建一个 Maven 项目,因为涉及到JSON的解析,我们先在Pom中导入相关坐标:
org.json json 20090211com.alibaba fastjson 1.2.47然后我们创建一个ParseJson类,在main方法中,我们先定义好动态参数。
// 输入路径 String fileIntputPath = "G:idea arcParseJsonsrcmainesourcesest.json"; // 输出路径 String fileOutputPath = "G:idea arcParseJsonsrcmainesourceswriteTest2.xlsx"; // 限制大小 int limitNumber = 100000;因为我们需要根据 指定的输入路径 去本地读取 JSON数据,所以我们还需要写一个方法。
/** * 读取指定文件路径的内容 * @param filePath 文件路径 * @return 文件内容 */ private static String readJsonFile(String filePath) { String jsonStr = ""; try { File jsonFile = new File(filePath); FileReader fileReader = new FileReader(jsonFile); Reader reader = new InputStreamReader(new FileInputStream(jsonFile),"utf-8"); int ch = 0; StringBuilder sb = new StringBuilder(); while ((ch = reader.read()) != -1) { sb.append((char) ch); } fileReader.close(); reader.close(); jsonStr = sb.toString(); return jsonStr; } catch (IOException e) { e.printStackTrace(); return null; } }有了读取文件内容的方法,我们就可以在接下来自己书写一个解析 JSON 文件的方法了。根据刚在网页上展示的层级关系图,我们不难得出写出以下代码:
// 调用方法,获取到指定路径的文件内容 String str = readJsonFile(filePath); // 调用 JSON 库的内容,获取到解析的对象 JSONObject jsonObject = JSON.parseObject(str); // 获取到 indexes 数组 JSONArray jsonArray = jsonObject.getJSONArray("indexes"); for (Object o : jsonArray) { JSONArray layouts = ((JSONObject) o).getJSONArray("layouts"); for (Object layout : layouts) { int id = ((JSONObject) layout).getIntValue("id"); JSONArray colOrder = ((JSONObject) layout).getJSONArray("col_order"); // 定义一个 StringBuilder,用于保存每次累加的结果 StringBuilder stringBuilder = new StringBuilder(); // 定义一个字段 size 保存原来数组的长度 int size = colOrder.size(); // 调用自己写的静态方法,获取到满足需求的数组长度 int greaterThanlakh = getGreaterThan(colOrder, size,limitNumber); // 定义一个字段保存每次循环的次数 int loopCount = 0; for (Object o1 : colOrder) { // 每循环一次,loopCount数值+1 loopCount ++; // 将其转换成 int 类型的数字 int number = Integer.parseInt(o1.toString()); if(number < 100000){ if (loopCount==greaterThanlakh){ stringBuilder.append(number); }else{ stringBuilder.append(number).append(","); } } } } } }在这个过程中,因为涉及到判断一个数组中,元素没有被过滤的个数,所以又自己写的一个功能方法。
/** * 计算出元素中小于100000的元素个数 * @param jsonArray JSON数组 * @param size JSON数组的容量大小 * @param limitNumber 过滤条件 * @return 小于100000的元素个数 */ private static int getGreaterThan (JSONArray jsonArray,int size,int limitNumber){ // 定义一个变量保存数组中 > 100000 的元素个数 int numberCount = 0; for (Object o : jsonArray) { int number = Integer.parseInt(o.toString()); if (number >= limitNumber){ numberCount ++; } } return size - numberCount; }现在我们已经获取到了每一个id ,以及它所对应小于 100000 的 col_order数组中的元素。那么我们就应该开始考虑一下,如何将这些值输出到Excel文件中。

可能熟悉Java的朋友能马上想起来 POI
poi 组件是由Apache提供的组件包,主要职责是为我们的Java程序提供对于office文档的相关操作。
但是像菌这样的小白,一看到这些常用的类,还不吓得原地昏厥。

所以说,这辈子都不可能用的。但是需求还没完全实现,我们该怎么办呢?
正当本菌一筹莫展之际,突然在经友人的提醒下,想起了在GitHub上一个神奇的仓库。
https://github.com/looly/hutool
可以看到,目前该开源项目,已经斩获了 15.3k Star。
该仓库中包含了对大部分常用功能的代码封装。

根据作者介绍,Hutool 的存在就是为了减少代码搜索成本,避免网络上参差不齐的代码出现导致的bug。
关于 Hutool 在 maven 项目中的使用也非常简单,我们只需要在项目的pom.xml的dependencies中加入以下内容:
cn.hutool hutool-all 5.4.1关于更多 Hutool 的具体使用,我们可以去参考 中文手册
因为我们需要参考如何生成Excel,我们可以定位到这个位置

这里我将它的使用例子贴出来:
使用例子
1、将行列对象写出到Excel
我们先定义一个嵌套的List,List的元素也是一个List,内层的一个List代表一行数据,每行都有4个单元格,最终list对象代表多行数据。
List row1 = CollUtil.newArrayList("aa", "bb", "cc", "dd");List row2 = CollUtil.newArrayList("aa1", "bb1", "cc1", "dd1");List row3 = CollUtil.newArrayList("aa2", "bb2", "cc2", "dd2");List row4 = CollUtil.newArrayList("aa3", "bb3", "cc3", "dd3");List row5 = CollUtil.newArrayList("aa4", "bb4", "cc4", "dd4");List> rows = CollUtil.newArrayList(row1, row2, row3, row4, row5);然后我们创建ExcelWriter对象后写出数据:
//通过工具类创建writerExcelWriter writer = ExcelUtil.getWriter("d:/writeTest.xlsx");//通过构造方法创建writer//ExcelWriter writer = new ExcelWriter("d:/writeTest.xls");//跳过当前行,既第一行,非必须,在此演示用writer.passCurrentRow();//合并单元格后的标题行,使用默认标题样式writer.merge(row1.size() - 1, "测试标题");//一次性写出内容,强制输出标题writer.write(rows, true);//关闭writer,释放内存writer.close();运行一下程序,我们观察案例代码实现的效果,打开 writeTest.xlsx

可谓是非常的 nice,我们只需要根据案例代码所给的提示把我们之前的代码 "完善"一下就好了。
但是还需要注意一点的就是,
Hutool-poi是针对Apache POI的封装,因此需要用户自行引入POI库,Hutool默认不引入。到目前为止,Hutool-poi支持:
Excel文件(xls, xlsx)的读取(ExcelReader)Excel文件(xls,xlsx)的写出(ExcelWriter)
如果我们想要输出Excel,推荐引入poi-ooxml,这个包会自动关联引入poi包,且可以很好的支持Office2007+的文档格式
org.apache.poi poi-ooxml ${poi.version}如果需要使用Sax方式读取Excel,需要引入以下依赖:
xerces xercesImpl ${xerces.version}说明 hutool-4.x的poi-ooxml 版本需高于3.17(别问我3.8版本为啥不行,因为3.17 > 3.8 ) hutool-5.x的poi-ooxml 版本需高于 4.1.2 xercesImpl版本高于2.12.0
引入后即可使用Hutool的方法操作Office文件了,下面贴出正式的代码:
package com.czxy;import cn.hutool.core.collection.CollUtil;import cn.hutool.poi.excel.ExcelUtil;import cn.hutool.poi.excel.ExcelWriter;import com.alibaba.fastjson.JSON;import com.alibaba.fastjson.JSONArray;import com.alibaba.fastjson.JSONObject;import java.io.*;import java.util.List;/** * @Author: Alice菌 * @Date: 2020/9/7 18:27 * @Description: */public class ParseJson { public static void main(String[] args) throws Exception { // 输入路径 //String fileIntputPath = "G:idea arcParseJsonsrcmainesourcesest.json"; String fileIntputPath = args[0]; // 输出路径 //String fileOutputPath = "G:idea arcParseJsonsrcmainesourceswriteTest2.xlsx"; String fileOutputPath = args[1]; // 限制大小 //int limitNumber = 100000; int limitNumber = Integer.parseInt(args[2]); strWriteToJSONObject(fileIntputPath,fileOutputPath,limitNumber); } /** * 读取指定文件路径的内容 * @param filePath 文件路径 * @return 文件内容 */ private static String readJsonFile(String filePath) { String jsonStr = ""; try { File jsonFile = new File(filePath); FileReader fileReader = new FileReader(jsonFile); Reader reader = new InputStreamReader(new FileInputStream(jsonFile),"utf-8"); int ch = 0; StringBuilder sb = new StringBuilder(); while ((ch = reader.read()) != -1) { sb.append((char) ch); } fileReader.close(); reader.close(); jsonStr = sb.toString(); return jsonStr; } catch (IOException e) { e.printStackTrace(); return null; } } private static void strWriteToJSONObject(String filePath,String fileOutPut,int limitNumber) throws Exception { // 调用方法,获取到指定路径的文件内容 String str = readJsonFile(filePath); // 调用 JSON 库的内容,获取到解析的对象 JSONObject jsonObject = JSON.parseObject(str); // 获取到 indexes 数组 JSONArray jsonArray = jsonObject.getJSONArray("indexes"); //如果需要输出到 txt 文本中,则使用下面这种方式 //FileWriter fw = new FileWriter(fileOutPut, true); //BufferedWriter bw = new BufferedWriter(fw); //初始化一个集合,用于存储所有需要输出到Excel的列 List> rows = CollUtil.newArrayList(); for (Object o : jsonArray) { JSONArray layouts = ((JSONObject) o).getJSONArray("layouts"); for (Object layout : layouts) { int id = ((JSONObject) layout).getIntValue("id"); JSONArray colOrder = ((JSONObject) layout).getJSONArray("col_order"); // 定义一个 StringBuilder,用于保存每次累加的结果 StringBuilder stringBuilder = new StringBuilder(); // 定义一个字段 size 保存原来数组的长度 int size = colOrder.size(); // 调用自己写的静态方法,获取到满足需求的数组长度 int greaterThanlakh = getGreaterThan(colOrder, size,limitNumber); // 定义一个字段保存每次循环的次数 int loopCount = 0; for (Object o1 : colOrder) { // 每循环一次,loopCount数值+1 loopCount ++; // 将其转换成 int 类型的数字 int number = Integer.parseInt(o1.toString()); if(number < 100000){ if (loopCount==greaterThanlakh){ stringBuilder.append(number); }else{ stringBuilder.append(number).append(","); } } } List row = CollUtil.newArrayList(id+"",stringBuilder.toString()); rows.add(row); } } OutToExcel(rows,fileOutPut); } /** * 计算出元素中小于100000的元素个数 * @param jsonArray JSON数组 * @param size JSON数组的容量大小 * @param limitNumber 过滤条件 * @return 小于100000的元素个数 */ private static int getGreaterThan (JSONArray jsonArray,int size,int limitNumber){ // 定义一个变量保存数组中 > 100000 的元素个数 int numberCount = 0; for (Object o : jsonArray) { int number = Integer.parseInt(o.toString()); if (number >= limitNumber){ numberCount ++; } } return size - numberCount; } public static void OutToExcel(List> rows,String fileOutPut){ for (List row : rows) { System.out.println(row); } System.out.println("fileOutPath:"+fileOutPut); //通过工具类创建writer ExcelWriter writer = ExcelUtil.getWriter(fileOutPut); //通过构造方法创建writer //ExcelWriter writer = new ExcelWriter("d:/writeTest.xls"); //跳过当前行,既第一行,非必须,在此演示用 //writer.passCurrentRow(); //合并单元格后的标题行,使用默认标题样式 //writer.merge(row1.size() - 1, "测试标题"); //一次性写出内容,强制输出标题 writer.write(rows, true); //关闭writer,释放内存 writer.close(); } }
细心的朋友们可能已经发现,博主已经将 main 方法中的变量替换成了参数,主要的目的就是可以将代码打包到Linux上运行,就像这样。
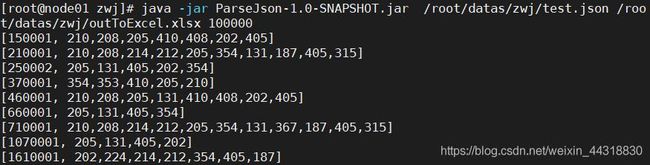
这里我们打开 outToExcel.xlsx 文件,看下效果。
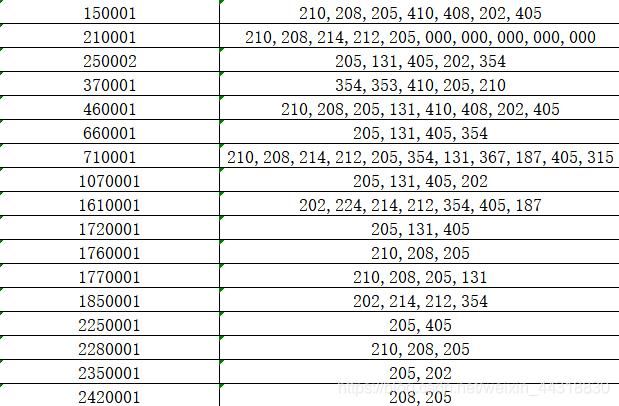
小结
本篇博客,博主主要为大家介绍了如何通过Json去解析Cube中的数据,并将需要的数据输出到Excel当中。菌着重为大家安利了一款非常实用的工具库——hutool,希望大家都能在不断探索的过程中,发现一些新鲜好玩的东西。
如果以上过程中出现了任何的纰漏错误,烦请大佬们指正
受益的朋友或对大数据技术感兴趣的伙伴记得点赞关注支持一波
希望我们都能在学习的道路上越走越远
