在上一次我进行了超万亿规模的Hadoop NameNode问题的排查,通过为时四天的努力,终于解决了Hadoop2.6.0版本的瓶颈问题,但是生活往往就是墨菲定律,你所极力避免的那些最坏的可能也许终将会发生。
为了防止遇到NameNode的第二次瓶颈,我决定将当前集群由Hadoop2.6.0版本升级到Hadoop3.2.1版本,且启用联邦模式。但是在升级之后,我们还是遇到了很多意向不到的问题,虽然最终经过一系列的排查还是解决了这些问题,但是我认为这次集群的升级经验能够帮助一些同学少走弯路。
下面,enjoy:
一、升级前的准备
在进行Hadoop集群升级,尤其是类似本次案例中这样上千节点的超大集群的升级,首先需要明确两点:
第一,是否确实有必要进行集群的升级,以目前的数据增长量级是否会触及当前版本的瓶颈。
首先需要声明一点,像本次案例中这样的超大规模的Hadoop集群,升级本身的难度就极大,需要消耗非常多的人力物力去修改数据库底层源码,仅仅对于我们产品LSQL的源码修改就花费了我们小组整整两周时间。更无需说我下文中会列明的在升级后会遇到的一系列问题的排查和处理,更是需要投入极大的时间精力。
本次我们选择进行Hadoop集群升级的主要原因是由于原先2.6.0版本过老,可能会存在其他未发现的问题。同时客户每天有近千亿条的数据增长,如不进行升级,很快还是会遇到NameNode的第二次瓶颈。如果客户在当前版本系统能够稳定运行,并且未来的数据体量不会有大幅增长,我们也不会采取升级集群的方案。
第二,是否做足了升级前的准备工作,以及是否有应对升级出现的各类问题的应急方案。
在本次升级前我们就做了大量的前期准备工作。我们进行了多次的升级演练,确保能应对在升级过程中出现的各类突发情况。同时鉴于客户数十万亿的生产系统的特性决定了在升级过程中决不能出现丢失数据或者服务长时间停止的情况。为此,我们制定了一旦升级出现问题就会采取的系统回退方案,遭遇数据丢失的挽回方案,以及在升级后的功能性验证等。
二、 升级后所出现的问题&解决
1.Hadoop跨多个联邦后,速度不快反慢
理论上,Hadoop升级成跨联邦机制,读写请求会分别均衡到三个不同的NameNode上,降低NameNode负载,提升读写性能,然而事实是NameNode负载不但没有降低,相反变得非常非常慢。
对于目前集群的卡顿程度,是肯定无法满足生产系统的运行需求的。而此时升级已经进行了三天了,如果卡顿问题不能得到解决,哪怕我们心有不甘也只能立即启动回退方案。但是毕竟我们都为这次升级准备了许久,而且客户也很期待升级后所带来的性能提升,我轻轻抚了抚头顶那沉睡多年的毛囊,一狠心决定连夜奋战。
首先需要做的就是定位造成卡顿的原因,我先从堆栈入手,发现主要问题还是NameNode卡顿,生产系统已经不能继续调查下去了,如果不想回退系统,就得让系统可用,那就只能从我们最熟悉的地方下手---修改录信LSQL,给所有请求NameNode文件的地方加上缓存,只要请求过的文件,就缓存下来,避免二次请求NameNode。
录信LSQL修改后NameNode状态有非常大的改善,系统基本可用。但具体为何升级到联邦后NameNode的吞吐量不升反降,我们没能给出合理的解释,只能初步断定是由于历史数据还在一个联邦上,导致数据的分布不均衡,希望之后能随着新数据的逐步导入,重新形成一个较为均衡的态势。
2.升级联邦后数据库稳定性降低,极易挂掉
在进行升级之后,我们发现几乎每隔几天我们的数据库系统LSQL就会挂掉一次。
观察录信LSQL的宕机日志,发现有大量的如下输出,证明Hadoop NameNode经常位于standby模式,导致Hadoop服务整体不可用,从而引起录信LSQL数据库宕机。
进一步分析NameNode发现Hadoop的NameNode并未宕机,active与standby都活着。结合Zookeeper日志分析发现,期间发生了NameNode的activer与standby的切换。
这里涉及两个问题,一是为什么发生了主备切换,二是切换过程中是否会导致服务不可用。
针对主备切换的原因,经过对比切换发生的时间,发现切换时NameNode做了比较大的负载请求,如删除快照,或者业务进行了一些负载较大的查询。这很有可能是因为NameNode负载较高,导致的Zookeeper链接超时。具体为什么NameNode负载很高,这个我们在后面阐述。
至于切换过程中是否会导致服务不可用,我们做了测试。第一次测试,直接通过Hadoop 提供的切换命令切换,结果切换对服务没有影响。第二次测试,直接将其中的Active NameNode给kill掉,问题复现了。可见在Hadoop 3.2.1版本里,active 与standby的切换,在切换过程中,是存在服务不可用的问题的。我们针对报错位置进一步分析如下:
看RouterRpcClient类的设计实现,应该是存在failover的逻辑。相关配置参数key值如下:
最终分析RouterRpcClient.java这个类,发现其设计逻辑是有问题的,虽然预留了上面那些参数,但没有生效,NameNode在主备切换过程中,存在两个NameNode同时处于Standby的过程。并且这个阶段,会直接报错,导致因报错而服务不可用。
我们详细阅读了该类的实现,发现该类虽然预留了重试的逻辑,但是这些重试的逻辑并没生效,存在BUG,故我们对此进行了修复。修复后录信LSQL的宕机问题不再出现,如下是涉及源码的分析过程:
如下是修复版本后,router重试过程中记录的日志:

3.数据库查询出现间接性卡顿
Hadoop升级到3.2.1版本后,录信LSQL会出现间歇性的卡顿情形,导致业务查询页面总是在“转圈圈”。
到现场后第二天遇到了该现象,经过了一系列的排查和追踪,最终定位在Hadoop 的NameNode卡顿(是不是很熟悉的感觉,没错它又来了......)。具体体现在进行一次ls操作,会卡顿20~30秒的时间。进入NameNode节点的机器观察负载情况,发现CPU的负载占用在3000%上下。
后经过多次抓取jstack,发现导致NameNode卡顿的堆栈的位置点如下:
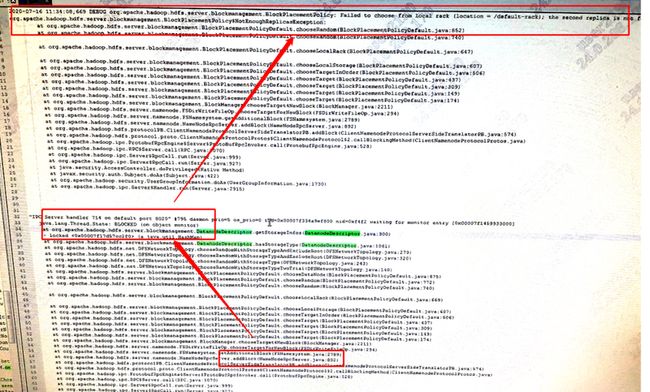
没错,是addBlock,也就是写数据的写锁会阻塞所有的查询。按照以往的经验,我们认为是上图中的锁引起的,故我们进行了去锁操作。
由于NameNode主备切换的问题已经解决,所以我们可以在生产系统通过热切的方式来验证我们的问题。去锁后的结果非常糟糕,卡顿现象不但没有减少,相反变得更严重,整台NameNode的负载不但没有降低,反而直接飙升到全满。
没办法,我们只好继续排查原因,仔细分析该类的相关实现,最终发现如下问题:
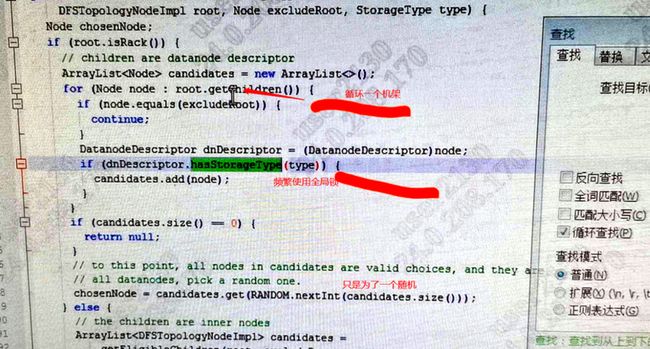
结合上面的原因,我们稍微改了下代码实现。

经分析发现每进行一次addBlock的请求,这里就会产生一次循环,这是一个机架上的所有机器。这意味着每调用一次addBlock方法,NameNode就要对一个机架内的设备进行一次循环,集群设备上千台,就是循环上千次,那这CPU使用率还了得!之前加锁状态,因为有锁的限制,只是会导致写入慢,查询还算可用。现在把锁去掉了,干脆CPU飚满,更是查不动了。然后jstack发现卡顿的地方变了,如下图所示:
我们临时调整NameNode的日志级别,调整为DEBUG级别,看到了如下的输出,更是进一步的验证了我们的想法。
同时我们对比了下Hadoop2.8.5版本的源码,发现这个地方的逻辑在Hadoop3.2.1中做了较大的变更。存在设计不当的问题,这种循环方式会耗费很多CPU。设计的本意是随机抽取节点,却要遍历一个机架下的所有节点,挨个加一遍锁。为了一次addBlock,平白无故加了几百次锁,哪能这样设计呢?我们仿照2.8.5的一些写法,重新修正了一下,针对这里的随机方式进行了重新改造。
改动完毕后,再继续抓jstack,崩溃的是,这块的逻辑确实抓不到了,但又在别的地方出现了,一样有个类似的循环。详细看代码发现Hadoop3.2.1的这个类里面,这样的循环太多了,在生产系统上改不起,也不敢改了。只能转变思路来解决,如果是因为这个循环的问题导致的NameNode卡顿,为何不是一直卡顿,而是间歇性卡顿,理清楚这个思路,也许就打开了一扇窗。
(1)SSD机器的Xreceiver引发的血案
我们分析了循环里的IP列表(DataNode的IP),并且结合现场日志的设备,发现了一个规律,这些循环里面的IP,均是SSD设备的IP,并非是SATA设备的IP。现场设备分为六组,每组一个机架,SATA和SSD各占一半。从IP的规律上来看,这些IP均是SSD设备。进一步分析,什么情况下这些DN会被加入到这个循环里面,从日志和源码分析,我们最终定位在Exclude上,也就是说Hadoop认为这些设备是坏了的,是应该被排除掉的设备。
难道是我们的SSD设备全都宕机了,或者他们的网络有问题?但经过排查,我们排除了这些问题。问题又回归到了源码层面,经过了大约1天的追踪定位,发现如下逻辑:
Hadoop在选择写入DN的时候,会考虑到DN的负载情况,如果DN负载比较高,它会将这个节点加入到Execude里面,从而排除掉这个节点,以此判断一个DN负载高低的就是Xreceiver的链接数量。默认情况下,只要Xreceiver的链接数量超过了整个集群连接数量的2倍,就会排除掉这个节点。而LSQL本身采用了异构的特性,意味着我们会优先从SSD盘读取数据,而SSD盘设备的性能好,数量又相对较少,导致这些SSD设备的机器连接数远高于SATA盘的链接数。SATA盘冷数据偏多,几乎很少有人去查询。针对这一情况,就会出现在一瞬间,因为连接数的问题,导致所有的或大多数的SSD设备被排除掉的情形。
我们的Hadoop集群有一部分数据的写入是采用ONE_SSD的模式,也就是一份数据存储在SATA设备上,另一份数据会存储在SSD设备上。而Hadoop3.2.1的特性,会随机在SSD设备里抽取一个节点,如果它没有在排除的execlude列表里,则会写入到这个设备里。而如果该设备被排除了,那么Hadoop就会再次尝试,再随机抽取其他节点,如此反复循环。但是我们的SSD设备因为Xreceiver负载的关系,绝大多数或全部都被排除掉了,直接导致了不断的循环,甚至上百次,最终还有可能发现一个SSD设备都不可用。日志里会提示2个副本1个SATA的写入成功了,还缺少一个副本没写成功,如下图所示:
上述问题中,直接导致大数据集群的两个致命性问题为:第一,NameNode CPU飚高,产生严重的间歇性卡顿;第二,SSD设备间歇性的被排除掉,只写成功了一个SATA副本,如果SATA设备突然损坏一个盘,那么数据就会丢失。
针对SSD的Xreceiver修复方法很简单,禁用该功能,或者调大倍数,如下图所示:
调整完毕后,我们非常明显的感受到了NameNode负载的下降,同时业务的所有查询,响应速度回归正常。
(2)机架分配策略不合理导致的同样问题
在我们验证上述问题的过程中,虽然NameNode的负载明显下降,但是上面所说的循环情况依然存在,查看DEBUG日志,令我们非常惊讶的是,这次循环的设备不是SSD设备,变成了SATA设备,这是什么情况?说不通啊。
还好,经过几天时间研读Hadoop源码,初步了解了这部分逻辑,我们打开Hadoop的DEBUG日志,观察到如下日志:

我们发现,一个机架下允许写入的块数超了,而别的机架没有可用的存储策略写入时,就会出现上述的循环。我们看下,一个机架下允许写入多少个数据块,又是怎么决定的?如下图所示:
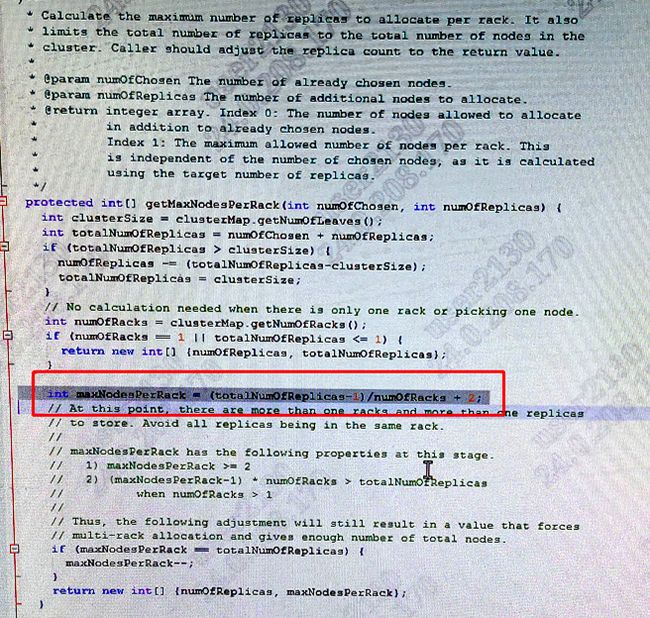
我们分了6个机架,3个SATA,3个SSD,从日志看,我们一个数据块要写入24个副本,这24个副本均要写入到SATA设备上。每个机架Rack上最多可以写入5个副本,3个SATA机架可以写入15个,另外的9个写入失败。Hadoop3.2.1在计算机架策略的时候并未考虑到这种情况,另外的SSD设备无法写入SATA存储策略的数据,导致了Hadoop在这种情况下将SATA设备循环几百遍,CPU飙升。
由于后续的9个副本,一直没有地方写入,Hadoop就会又像之前那样,将所有的SATA的设备循环上几百遍。这也会导致CPU的飙升。
我们实际生产环境中,写入24个副本的情况是极少的,只存在更新的一些场景,由于带更新的数据,需要被每个节点读取(有点类似Hadoop的DistirbuteCache),如果2副本,会造成个别DataNode的压力过大,故我们增大了副本数。
这一情况也跟之前业务提出,只要一执行更新,就会明显感受到业务查询的卡顿的现象对应上。
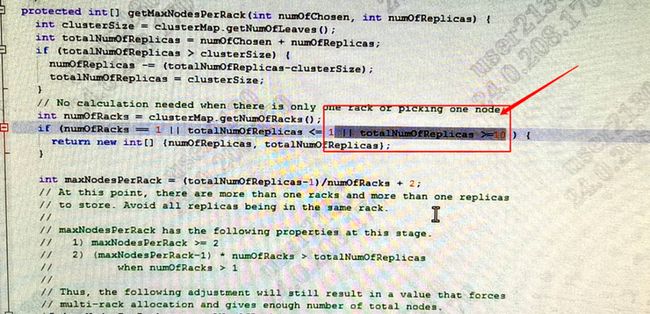
针对这个问题,我们认为应该对机架分配策略进行调整,不允许单独的SSD与SATA在各自不同的机架上,一个机架上必须即有SSD设备,也要有SATA设备。这样这个问题就可以规避了。但我们担心一旦更改了此时的机架策略,会造成Hadoop的副本大量迁移(为了满足新的机架策略的需要),我们的集群规模太大了,我们最终还是选择了修改NameNode的源码。从源码层面解决这个问题,如下图所示:
三、总 结
总结一下,本次升级过程主要分享的知识点有两个:
第一,Hadoop Router针对NameNode的failover没有进行重试处理,在主备切换期间,会发生服务报错,导致系统整体不可用;
第二,Hadoop addBlock 在3.2.1版本的设计思路上会因为机架策略的问题而进行循环处理,结果导致CPU占用过高,频繁加锁。
最后,本次Hadoop集群升级过程总体而言不算顺利,在升级之后也遇到了一些让我们感到棘手的问题,在此我们还是希望同学们在准备进行Hadoop集群升级,尤其是超大规模的集群升级时一定要做好充足的准备,在发现升级后系统无法满足生产需求时也要有壮士断腕的勇气,及时进行系统版本的回退。
PS:更多hadoop技术实践干货欢迎在微信中关注公众号“录信数软”~