趣谈多线程(Python版)
温馨提示:本文篇幅较长,建议读者耐心阅读,本文中的代码经过笔者精心构思,可以复制过去运行一下,观察输出结果,所有代码在python3.5.0中测试通过。
文章目录
- What is 多线程?
- Why we choose 多线程?
- How to use 多线程?
-
- Thread类剖析(关键)
- 线程创建的方法(关键中的关键)
- 同步原语
-
- 锁
- 信号量
- 条件变量[^2]
What is 多线程?
谈起多线程,大家或多或少地都听说过,和它黏在一起的还有两个兄弟我想大家也不会太陌生——多核和多进程1。它们之间有着错综复杂的关系,一时半会也很难捋清它们千丝万缕的联系,教科书上的定义又宛如天书,但有网友这么比喻就很形象了,每个核心的CPU就好比一个工厂,而每个进程又是工厂中的车间,每个线程又是进程中干活的工人,而我们普通的程序一般就是串行程序,也就是就开了一个工厂,一个工厂中又只有一个车间运作,一个车间中又只有一个干活的工人,这种情景是这样的:

这显然不是我们所希望的,所以多进程,多线程的概念便应运而生了,它的目的就是让cpu不闲着,同时做好几样的活,这看起来很残忍,但对cpu来说却也很简单,毕竟它处理的只有0和1嘛(故称二愣子)!我们来给个简单的普通程序和多线程程序的比较:

Why we choose 多线程?
每个进程车间中的线程是共享资源的(车床啥的可以共享),所以处理起来比较容易,因此我们先来谈谈多线程。并且,在windows下,创建线程的开销比较小,所以windows下比较鼓励创建多线程
How to use 多线程?
Thread类剖析(关键)
我们通过创建threading模块中的Thread类来创建线程,所以,我们首先需要来看一下Thread类的原型:class threading.Thread(group=None, target=None, name=None, args=(), kwargs={}, *, daemon=None) 我们大概来介绍一下,group参数,官方文档说为以后的版本保留,也就是现在我们不用管他,而第二个target参数就比较关键了,它需要传递一个需要调用的函数,或类作为其一个线程对象,第三个name参数则是指定线程的名字,args则是传入调用函数或类所需要的参数(要以元组或数组的形式传入),而kwargs也就是传入字典参数啥的(一般不用),最后的daemon参数是用来设置是否为守护线程(因为当主线程退出时,其他子线程也随之退出,所以当我们需要进程一定要在所有线程处理完毕后退出,我们就不能将线程设置成守护线程,若设置为守护线程,则进程准备退出时不会管线程的死活)。
笔者友情提示:以上概念看不懂没关系,经过下面几个例子后回过头再来看就会恍然大悟了。
线程创建的方法(关键中的关键)
Thread类的关键就是target参数,因为其决定创建线程的功能。 target既可以给他赋一个函数 ,例如:
# -*- coding: UTF-8 -*-
import threading
import time
def say_hello():
time.sleep(5)
print("Hello world!"+time.strftime("%a, %d %b %Y %H:%M:%S +0000\n", time.localtime()),end = '')
def _main():
print("Begin at:"+time.strftime("%a, %d %b %Y %H:%M:%S +0000\n", time.localtime()),end = '')
threads = []
for i in range(5):
thread = threading.Thread(target = say_hello)
threads.append(thread)
threads[i].start()
for i in range(5):
threads[i].join()
if __name__ == '__main__':
_main()
运行结果为:

现在我们来对这个小程序做一个比较详细的讲解:
- 首先,由于我们需要用到多线程,所以需要导入threading模块
- 接着,我们直接来看主函数(
_main)中的内容,它先打印当前的时间 - 然后,它通过一个for循环创建了5个Thread类,也就是创建了5个线程,它这里target参数指向
sy_hello()函数,也就是说每个线程所需要做的工作就是执行say_hello()函数中的内容,因为这个函数不需要参数,所以无需为Thread类传入args参数。注意,线程创建好后,我们需要调用它的start()方法使它运行起来。 - 再接着,我们来看一下
say_hello()函数中的内容,它无非是先休息5s,然后打印一句Hello world再加上当前的时间。 - 我们看到我们还调用了Thread类的join方法,
join方法就是等待线程结束,只要线程不结束,那么主线程就不会结束。 - 最后,我们看到结果中各子线程打印出来的时间居然是一样的,这就说明,这些线程是在同步运行,也就是说明,本来如果用串行的方法打印
say_hello()5次的话需要 5 × 5 = 25 s 5\times 5=25s 5×5=25s的时间,而现在仅需5s,至此,我们也可以体会到多线程的强大之处。
当然还可以通过对Target参数赋一个类来创建线程,再来举个栗子:
# -*- coding: UTF-8 -*-
import threading
import time
class say_hello(threading.Thread):
def __init__(self):
threading.Thread.__init__(self)
def run(self):
time.sleep(5)
print("Hello world!"+time.strftime("%a, %d %b %Y %H:%M:%S +0000\n", time.localtime()),end = '')
##def say_hello():
## time.sleep(5)
## print("Hello world!"+time.strftime("%a, %d %b %Y %H:%M:%S +0000\n", time.localtime()),end = '')
def _main():
print("Begin at:"+time.strftime("%a, %d %b %Y %H:%M:%S +0000\n", time.localtime()),end = '')
threads = []
for i in range(5):
thread = say_hello()
threads.append(thread)
threads[i].start()
for i in range(5):
threads[i].join()
if __name__ == '__main__':
_main()
运行结果为:

同样,我们来对这段简短的代码剖析一下。可以看到,这段代码和上段代码基本无异,只是把say_hello()函数变成了一个类。我们通过自定义一个类,这个类继承于threading.Thread类,帮助文档中提到,我们需要重写__init__()方法和run()方法。__init__()方法中又调用threading.Thread类中的__init__()方法进行初始化,我们当然还可以进行其他的初始化,只不过这里我们没别的参数。然后在run()中,我们需要定义让线程做的事,这里需要做的事和之前哪个程序的一样,都是打印Hello world再加上当前时间。最后,我们在主函数(_main())中调用这个类,定义这个自定义的类就是创建线程的过程,同样,我们需要调用其的start()方法来使线程跑起来,用join()方法等待线程运行结束。可以看到,这里的运行结果和之前哪个程序的完全相同。
(可选跳过阅读–>)其实,创建线程还有第三种方法,这种方法显得不伦不类,它居于上述讲的两种创建方法的中间态,也就是定义一个类,但无需继承自threading.Thread类,而只需定义其__call__()方法(重定义这个魔法方法就是把类变成了个函数,我们之后在讲py的魔法方法中会提及),所以这个方法更像第一种创建线程的方法。
# -*- coding: UTF-8 -*-
import threading
import time
##class say_hello(threading.Thread):
## def __init__(self):
## threading.Thread.__init__(self)
## def run(self):
## time.sleep(5)
## print("Hello world!"+time.strftime("%a, %d %b %Y %H:%M:%S +0000\n", time.localtime()),end = '')
##def say_hello():
## time.sleep(5)
## print("Hello world!"+time.strftime("%a, %d %b %Y %H:%M:%S +0000\n", time.localtime()),end = '')
class say_hello():
def __call__(self):
time.sleep(5)
print("Hello world!"+time.strftime("%a, %d %b %Y %H:%M:%S +0000\n", time.localtime()),end = '')
def _main():
print("Begin at:"+time.strftime("%a, %d %b %Y %H:%M:%S +0000\n", time.localtime()),end = '')
threads = []
for i in range(5):
thread = threading.Thread(target=say_hello())
threads.append(thread)
threads[i].start()
for i in range(5):
threads[i].join()
if __name__ == '__main__':
_main()
运行结果为:

经过上述几段程序的“洗礼”,我想大家对多线程的创建有了个初步的印象,然而细心的同学可能会注意到上述的几个线程创建都是没传入参数的,如果我们需要为创建的线程出传入参数呢,这时,我们就需要应用threding.Thread类中的args参数了。我们来对上述几个程序稍加修改就行。
使用函数创建线程的:
# -*- coding: UTF-8 -*-
import threading
import time
def say_hello(hello):
time.sleep(5)
print("%s"%hello+time.strftime("%a, %d %b %Y %H:%M:%S +0000\n", time.localtime()),end = '')
def _main():
print("Begin at:"+time.strftime("%a, %d %b %Y %H:%M:%S +0000\n", time.localtime()),end = '')
threads = []
for i in range(5):
thread = threading.Thread(target=say_hello,args = ("Hello world from _main()!",))
threads.append(thread)
threads[i].start()
for i in range(5):
threads[i].join()
if __name__ == '__main__':
_main()
运行结果:

可以看到,这时线程中打印的语句是主函数中传入的,我们在创建Thread类时给args赋予参数,注意,这里一定要给args赋以元组或数组,仔细看上面的程序,"Hello world from _main()!"后有个,号,就是为了把参数打包成元组(小小提示一下,逗号是元组的特征)。
使用类创建线程的:
# -*- coding: UTF-8 -*-
import threading
import time
class say_hello(threading.Thread):
def __init__(self,hello):
threading.Thread.__init__(self)
self.hello = hello
def run(self):
time.sleep(5)
print("%s"%self.hello+time.strftime("%a, %d %b %Y %H:%M:%S +0000\n", time.localtime()),end = '')
def _main():
print("Begin at:"+time.strftime("%a, %d %b %Y %H:%M:%S +0000\n", time.localtime()),end = '')
threads = []
for i in range(5):
thread = say_hello("Hello world from _main()!")
threads.append(thread)
threads[i].start()
for i in range(5):
threads[i].join()
if __name__ == '__main__':
_main()

用类创建需传入参数线程的方法更加易懂,我想聪明的你看一眼便知道了,这里我们不再赘述了 。(可以与之前的程序比较着看便很明显了)
看到这里的同学恭喜你,你现在已掌握60%的基本功力,给自己一点掌声,休息一下,接下来我们来加深一下你的功力。

同步原语
我们先来看一段有趣代码:
# -*- coding: UTF-8 -*-
#工人上厕所问题
import threading
import time
toilets = ['1','2','3','4','5'] #厕所名
def go_to_toilet(worker_name):
global toilets
toilet_name = toilets[0]
print('%s goes to toilet%s.\n'%(worker_name,toilet_name),end = '')
del toilets[0]
def _main():
workers = ['A','B','C','D','E'] #工人名
threads = []
for i in range(len(workers)):
thread = threading.Thread(target = go_to_toilet,args = (workers[i],))
threads.append(thread)
threads[i].start()
for i in range(len(workers)):
threads[i].join()
if __name__ == '__main__':
_main()
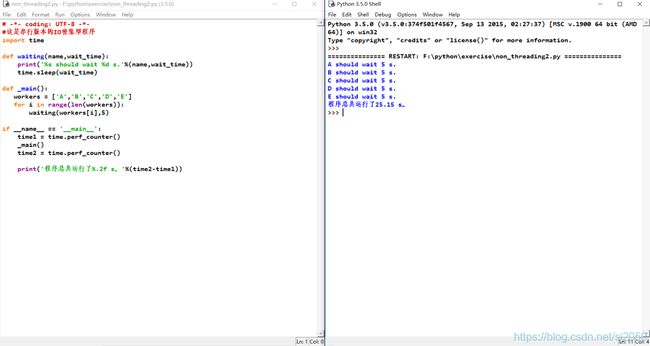
我们简单地对上面这段程序做个分析。现在我们有5个厕所,5名工人,这5名工人都要上厕所,理想的情况就是每个工人占用一个厕所(重口味的事我们不干,?),这里我们用线程来模拟工人,即一个线程代表一个工人,我们假设每个工人就是直接挑当前厕所名单中的第一个,即一个工人选定厕所名单中的第一个后,我们将这个厕所认为已被占用,即把它从当前厕所名单中删去,这时下一个工人选的厕所就是初始厕所名单中的第二个厕所,接着,再把这个厕所从厕所名单中删去,以此类推,这样,每个工人都可以独占一个厕所。
然而,运行结果好像有点不太对。。。

所有的工人都去了第一个厕所那,这画面不敢想象?

为啥子会这样呢,难道是del方法出错了吗,然而现实又无情打脸。
![]()
真相只有一个,线程运行不是我们想的那样,不是说先创建并使其运行的线程就会真的先运行,仔细看看上面那个程序的输出结果,工人并没有照着顺序输出。因为程序运行太快了,各个线程之间的差距很小很小,后创建运行的线程可能超上前创建运行的线程。同理,前一个工人到达第一个厕所后,他还没来得及将这个厕所从厕所名单中删除,第二个工人看厕所名单,以为第一个厕所还没人霸占,所以也去了第一个厕所,第三个,第四个,第五个也同样接踵而至,于是便出现了上述的结果。
于是我们需要引入同步原语了,也就是临界区的代码在给定时刻只有指定的时刻只有一个线程通过。(官方用语)
锁
锁可以让只有任意时刻只能有一个工人能看厕所名单,在选定厕所后就把其划掉,然后这个名单才能给下一个人看,这样,后来的工人再来看这个名单时便知道第一个厕所选不了,他就会选下一个,以此类推,完美解决了众人涌向同一个厕所的尴尬情形。
# -*- coding: UTF-8 -*-
import threading
import time
toilets = ['1','2','3','4','5']
lock = threading.Lock()
def go_to_toilet(worker_name):
global toilets
lock.acquire()
toilet_name = toilets[0]
print('%s goes to toilet%s.\n'%(worker_name,toilet_name),end = '')
del toilets[0]
lock.release()
def _main():
workers = ['A','B','C','D','E']
threads = []
for i in range(len(workers)):
thread = threading.Thread(target = go_to_toilet,args = (workers[i],))
threads.append(thread)
threads[i].start()
for i in range(len(workers)):
threads[i].join()
if __name__ == '__main__':
_main()
运行结果:

我们看到,程序运行正常了,每个工人都独享一个厕所。这里我们就引入了锁对象,也就是,我们先创建一个锁对象,即lock = threading.Lock(),然后在要锁起来的地方调用lock对象的acquire()方法,在要释放锁的地方调用lock对象的方法release(),没错,就这么简单,我们便可以实现锁的功能了,也就是保证了toilets数组在给定的一个时刻只能被一个线程访问,其他线程都得等待这个线程处理完释放锁后才能访问这个数组。
信号量
有时,我们又希望某个资源不能超过某个最大的数值,譬如我们来看下面这个工人洗澡问题。我们假设现在我们只有2个单人浴室,但有5个工人,这5个工人都要洗澡,但由于浴室数量有限,所以我们规定先到者先霸占,我们来看一下代码实现:
# -*- coding: UTF-8 -*-
#工人洗澡问题
import threading
import time
import random
MAX_SIZE = 2
bathroom = threading.BoundedSemaphore(value = MAX_SIZE) #大浴室,每间浴室最多能容纳三个人
for i in range(MAX_SIZE):
#将信号池内的信号量先耗光
bathroom.acquire(False)
def go_to_bathroom(worker_name,need_time):
print('%s goes to bathroom.\n'%worker_name,end = '')
while 1:
try:
bathroom.release()
print('%s grabes one place.\n'%worker_name,end = '')
break
except ValueError:
pass
print('%s is taking a shower.It lasts %d s.\n'%(worker_name,need_time),end = '')
time.sleep(need_time)
print('%s end the bath and go back.\n'%worker_name,end = '')
bathroom.acquire(False)
def _main():
workers = []
for i in range(5):
workers.append(chr(65+i))
threads = []
for i in range(len(workers)):
thread = threading.Thread(target = go_to_bathroom,args = (workers[i],random.randint(2,5)))
threads.append(thread)
threads[i].start()
for i in range(len(workers)):
threads[i].join()
if __name__ == '__main__':
time1 = time.perf_counter()
_main()
time2 = time.perf_counter()
print('All costs %d s.'%(time2-time1))
运行结果:

这个程序中,我们假设每个工人挑的浴室是任意的,每个人洗澡的时间也是任意的。从上面的输出结果中我们可以看到,任意时刻,只会有2个人能洗澡。这里我们用到了信号量的对象,跟锁对象一样,我们先来创建一个信号量对象,bathroom = threading.BoundedSemaphore(value = MAX_SIZE),这里设置value参数用来指定最多能有多少资源,这里,我们最多只能有两个人能同时洗澡,然后调用信号量对象的release()能使信号池中的资源数加1,如果超过我们之前设置的最大值的话,则会抛出ValueError(注意上述程序中对ValueError的错误处理)。调用信号量对象的acquire(False)(设置False可以使减1这个过程立马执行,若信号池中的资源已全部消耗完就报错,若不设置的话,则如果信号池中已没资源了,它会等待直至信号池中有资源为止,然后再执行减1操作)方法来使信号池中的资源数减1。这样我们就很好的模拟了工人洗澡问题。
条件变量2
上面的程序中,我们看到,这些工人开始是同时冲往浴室的,但不幸的是,最终只有两个人能抢到浴室,其他人只能干等,有没有办法先让两个人先去浴室,其他人在寝室中舒舒服服地等,当有人洗完后,通知下一个人去洗,这样不就能解决干等的问题了吗,于是,条件变量就上场了,先来看一下我们模拟的代码:
import threading
import time
import random
#这里我们假设只有两个浴室
waiting_workers = [] #待洗澡的名单
class Worker(threading.Thread):
def __init__(self,name,need_time,cond):
threading.Thread.__init__(self)
self.name = name #工人名字
self.need_time = need_time #洗澡所需时间
self.cond = cond #条件变量的加入
def run(self):
global waiting_workers
self.cond.acquire() #上锁
self.cond.wait() #暂时上交锁,线程挂起
print("%s 开始洗澡,需要%d s时间。。。\n"%(self.name,self.need_time),end='')
time.sleep(self.need_time) #洗澡时间
if len(waiting_workers)>0:
self.cond.notify() #通知下一个工人来洗澡
self.cond.release() #洗澡完毕,释放锁
print("%s 洗澡结束!\n"%self.name,end='')
waiting_workers.remove(self.name) #从待洗澡的名单中移除
if __name__ == '__main__':
all_time = 0
time1 = time.perf_counter()
conds = []
threads = []
for i in range(2):
conds.append(threading.Condition()) #创建两个条件变量,不同的条件变量对应不同的浴室
for i in range(5):
waiting_workers.append(str(i))
random_time = random.randint(1,5)
threads.append(Worker(str(i),random_time,conds[i%2])) #每个工人获得不同浴室的钥匙
all_time+=random_time
for i in range(5):
threads[i].start() #开始
for i in range(2):
#一开始浴室是空的,先通知2人去洗澡
with conds[i]:
conds[i].notify()
for i in range(5):
threads[i].join()
time2 = time.perf_counter()
print("程序原本需要执行%d s时间。\n"%all_time)
print("程序实际一共执行了%d s时间!\n"%(time2-time1))
运行结果:

同样我们来说明一下,在主函数中,我们先创建了2个条件变量类(conds.append(threading.Condition()),其对应两个单人浴室,接着我们需着重看一下Worker类,它继承自threading.Thread类,我们重写了__init__()和run()方法,在run()方法中,我们先让线程获得锁(self.cond.acquire()),接着让线程进入等待区,即线程挂起(self.cond.wait()),当线程挂起时它会暂时交上锁,后面轮到该线程运行时它又会被还回当初的那把锁,当线程中的内容执行结束后就释放锁(self.cond.release()),但在释放锁前,我们还需做一件事,如果还有人没洗澡过的话,就通知下一个来洗澡,即唤醒等待的线程(self.cond.notify()括号内可赋以参数表示要唤醒几个线程,默认为1)。然后,在主程序会先唤醒2个人先去洗澡。我们来概括一下这个过程,就是先创建了5个线程,然后使它们都休眠,接着唤醒其中两个,每个执行好后又会唤醒下一个线程来执行。其实,我们看条件变量这一名字就可以知道,事件发生是需要条件的,所以条件变量类还有一个方法(wait_for(predicate, timeout=None,这里的第一个参数代表某个事件是否发生,即是否为True,若是,则该线程开始执行)。
小技巧:上述几个同步原语都可结合with语句使用,例如:
with some_lock:
# do something...
等价于
some_lock.acquire()
try:
# do something...
finally:
some_lock.release()
现在,python 90%的多线程的知识就介绍完毕了,而这些知识在实际应用中已完全足够了,帮助文档中还有如何判断主线程,判断线程是否存活等的一些方法,但比较简单,所以本文未展开,如需了解,可查看官方文档,不难。有人问,多线程在实际编程中有什么用,我们会在笔者未来要开的网络爬虫栏目中一睹精彩。感谢你的耐心阅读,在后面我们还准备了关于python的拓展知识。

python多线程拓展知识:
1. 我们开始就说到,线程是共享进程的资源的,同时,上面我们也详细介绍了如何避免资源访问的冲突,这样我们就能让多线程共同处理同一件事,我们推荐使用py内置的Queue模块来创建一个队列(无非只有入队,出队,判断是否为空或满的操作罢了)来储存需要共同访问的资源(因为Queue模块是线程安全的)。
2. 由于GIL锁的存在,其实在任意时刻,cpu只会处理py程序中的一个线程,那它是怎么模拟出多线程的效果来的呢,cpu在不同的线程之间不断地切换,就是这个线程执行一会,那个线程执行一会地执行,由于cpu的切换速度极快,看起来就像多个线程同时再跑,但py的多线程更适合IO密集型程序,也就是一个线程在等待输入的时候(用户输入,网络响应),这时cpu可以先执行另一个线程,这样就很好的避免cpu的闲置,想要知道GIL锁的更多知识,这里有场不错的讨论:为什么有人说 Python 的多线程是鸡肋呢?
参考资料34
《多CPU,多核,多进程,多线程》 ↩︎
《python笔记11-多线程之Condition(条件变量)》 ↩︎
《python核心编程(第三版)》 ↩︎
《python3.5.0官方文档》 ↩︎