Spark the definitive guide Chapter12实验报告
【实验名称】Chapter12 弹性分布数据集(RDDs)
-
-
-
- **什么是底层api**
- **如何使用底层api**
- **关于RDD的定义及特点**
- **创建RDD**
- 转换(Transformations)
- **action操作**
- 保存结果数据到文件
- caching
- Checkpointing
- Pipe RDDs to System Commands(将RDD传递到系统命令)
- glom
-
-
什么是底层api
有两组底层api:一组用于操作分布式数据(RDDs),另一组用于分发个操作分布式共享变量
如何使用底层api
SparkContext是低级api功能的入口点,可以通过以下调用访问SparkContext:
spark.sparkContext # 或者直接调用 sc
关于RDD的定义及特点
RDD表示一个不可变的、分区的记录集合,可以并行操作。
具体定义可以参考课本31-33页
创建RDD
DataFrame、dataset和RDD之间的互操作
获取RDDs的最简单方法之一就是从DataFrame或datasets转换而来,只需要在这些数据类型上使用 rdd() 方法即可。如果从Dataset[T]转换到RDD,可将获得适当的原生类型T(但仅适用于scala和java)。
由于python只有Dataframe,故得到的是Row类型的RDD:
spark.range(10).rdd
要操作这个数据,需将这个Row对象转换为正确的数据类型或从中提取值。
如下示例,这是一个Row类型的RDD:
spark.range(10).toDF('id').rdd.map(lambda row : row[0])
也可从RDD中创建Dataframe,在RDD上调用toDF方法:
spark.range(10).rdd.toDF()
从本地集合创建RDD
要从集合中创建一个RDD,需要使用SparkContext(在SparkSession中)上的parallelize方法。使得单节点集合变为并行集合。在创建这个并行集合时,还可以显式的声明要分配该数组的分区数。
示例创建2个分区:
// in Scala
val myCollection = "Spark The Definitive Guide : Big Data Processing Made Simple"
.split(" ")
val words = spark.sparkContext.parallelize(myCollection, 2)
# in Python
myCollection = "Spark The Definitive Guide : Big Data Processing Made Simple"\
.split(" ")
words = spark.sparkContext.parallelize(myCollection, 2)
另一个特性是,可以根据给定的名称在SparkUI中显示这个RDD:
// in Scala
words.setName("myWords")
words.name // myWords
# in Python
words.setName("myWords")
words.name() # myWords
从数据源中创建RDD
使用SparkContext读取数据作为RDDs,示例读取一个文本文件:
# 读取当前路径下的文件,如果没有首先得创建此文件
spark.sparkContext.textFile("./withTextFiles")
这将创建一个RDD,其中RDD的每个记录表示该文本文件的每一行。
或者,可以读取每个文本文件成为单个记录的数据。这里的用例每个文件都是一个文件,它由一个大的json对象或者一些个人操作的文档组成:
spark.sparkContext.wholeTextFiles("./withTextFiles")
在这个RDD中,文件的名称是第一个对象,文本文件的值是第二个字符串对象
转换(Transformations)
distinct方法
在RDD上调用distinct方法,删除重复数据:
words.distinct().count() #9
filter方法:
filter() 操作相当于创建一个类似SQL的where子句,该函数只需要返回一个布尔类型即可用作过滤器函数。 输入应为您给定的行。
在下一个示例中,我们对RDD进行过滤,以仅保留以字母“ S”开头的单词:
// in Scala
def startsWithS(individual:String) = {
individual.startsWith("S")
}
# in Python
def startsWithS(individual):
return individual.startswith("S")
现在我们定义了函数,让我们过滤数据。
words.filter(lambda word: startsWithS(word)).collect()
得到两个以字母“S”开头的单词
[‘Spark’, ‘Simple’]
map方法
map将函数作用到数据集的每一个元素上,生成一个新的分布式的数据集(RDD)返回。
在此示例中,我们将当前单词映射到该单词,验证其起始字母以及该单词是否以“ S”开头。
// in Scala
val words2 = words.map(word => (word, word(0), word.startsWith("S")))
# in Python
words2 = words.map(lambda word: (word, word[0], word.startswith("S")))
随后,您可以通过在新函数中选择相关的布尔值来对此进行过滤:
// in Scala
words2.filter(record => record._3).take(5)
# in Python
words2.filter(lambda record: record[2]).take(5)
返回结果
[(‘Spark’, ‘S’, True), (‘Simple’, ‘S’, True)]
flatMap方法
flatMap会先执行map的操作,再将所有对象合并为一个对象,返回值是一个Sequence。flatMap提供了我们刚刚看过的map函数的简单扩展。 有时,每个当前行应该返回多行结果。
例如,在单词计数程序中,处理每一行语句的时候,需要返回一个单词集合。因为一句话就包含多个单词,所以需要flatMap函数处理。还记得我们第一个实验wordcount实例吗?在读取文件后,对每一行进行扁平化处理就是用的flatMap方法。
// in Scala
words.flatMap(word => word.toSeq).take(5)
# in Python
words.flatMap(lambda word: list(word)).take(5)
[‘S’, ‘p’, ‘a’, ‘r’, ‘k’]
【不同点】:map操作是对RDD中每个元素进行操作的,操作的结果是一对一的,flatMap操作也是对RDD中每个元素进行操作的,但是它的操作结果是一对一或者是一对多的。
sortBy方法
要对RDD进行排序,必须使用sortBy方法,就像其他任何RDD操作一样,您可以通过指定一个函数来从RDD中的对象中提取值,然后基于该函数进行排序。
例如,以下示例按单词长度从最长到最短排序:
// in Scala
words.sortBy(word => word.length() * -1).take(2)
# in Python
words.sortBy(lambda word: len(word) * -1).take(2)
随机分割(random splits)
书上没有太多介绍这个方法,仅是说明randomSplit方法是将RDD随机分为RDD数组。该方法接受weight和seed两个参数,这里详细介绍下weight参数,seed基本可以忽略。
weights: 权重值,是一个数组,它们的和不能超过1
根据weight将一个RDD划分成多个RDD,权重越高划分得到的元素较多的几率就越大。
先创建一个数字集合的RDD:
rdd = spark.sparkContext.parallelize(range(10))
rdd.collect()
// [0,1,2,3,4,5,6,7,8,9]
数组的长度即为划分成RDD的数量,如
// in Scala
val fiftyFiftySplit = rdd.randomSplit(Array[Double](0.5, 0.5))
# in Python
fiftyFiftySplit = rdd.randomSplit([0.5, 0.5])
数组[0.5,0.5] 的作用是把原本的RDD按权重值尽可能的划分成2个相同大小的RDD。
接下来测试一下randomsplit方法
fiftyFiftySplit[0].collect()
fiftyFiftySplit[1].collect()
action操作
action操作触发了transformation操作的真正执行。Action操作要么向driver程序手机数据,要么向外部数据源写入数据
reduce
可以使用reduce方法,为其指定一个函数,然后其会将RDD中数据任意个数的数据值合并为一个值。
例如示例为一个数字集合的RDD,使用reduce方法将这些数字相加,得到总的结果210。
// in Scala
spark.sparkContext.parallelize(1 to 20).reduce(_ + _) // 210
# in Python
spark.sparkContext.parallelize(range(1, 21)).reduce(lambda x, y: x + y) # 210
也可以使用它来获得类似我们刚才定义的单词集中最长的单词。 关键是要定义正确的函数:
// in Scala
def wordLengthReducer(leftWord:String, rightWord:String): String = {
if (leftWord.length > rightWord.length)
return leftWord
else
return rightWord
}
words.reduce(wordLengthReducer)
# in Python
def wordLengthReducer(leftWord, rightWord):
if len(leftWord) > len(rightWord):
return leftWord
else:
return rightWord
words.reduce(wordLengthReducer)
count
使用它计算RDD中的行数
words.count() #9
countApprox (count的近似)
即使此类型的返回签名有些奇怪,也相当复杂。 这是我们刚刚看过的count方法的近似值,但是它必须在超时内执行(如果超过超时,则可能返回不完整的结果)。
置信度是结果的误差范围包含真实值的概率。 也就是说,如果以0.9的置信度重复调用countApprox,则我们期望结果的90%
//in scala
val confidence = 0.95
val timeoutMilliseconds = 400
words.countApprox(timeoutMilliseconds, confidence)
# in python
confidence = 0.95
timeoutMilliseconds = 400
words.countApprox(timeoutMilliseconds, confidence)
countByValue
此方法计算给定RDD中值的数量。 但是,它是通过将结果集最终加载到驱动程序的内存中来实现的。 仅在预期生成的map较小的情况下才应使用此方法,因为整个地图都已加载到驱动程序的内存中。 因此,此方法仅在行总数少或不同项目数少的情况下才有意义:
words.countByValue()
first
返回结果集的第一个值
words.first()
max and min
分别返回结果中最大、最小值
sc.parallelize(range(1, 20)).max()
sc.parallelize(range(1, 20)).min()
take
take及其派生方法(takeOrdered,takeSample和top)从RDD中获取许多值。 通过首先扫描一个分区,然后使用该分区的结果来估计满足该限制所需的其他分区的数量,可以进行此操作。可以使用takeSample从RDD中指定一个固定大小的随机样本。 您可以使用withReplacement,来指定值的数量以及随机种子是否应该这样做。
top是实际上与takeOrdered相反,它根据隐式顺序选择顶部的值:
// in scala
words.take(5)
words.takeOrdered(5)
words.top(5)
val withReplacement = true
val numberToTake = 6
val randomSeed = 100L
words.takeSample(withReplacement, numberToTake, randomSeed)
# in python
words.take(5)
words.takeOrdered(5)
words.top(5)
withReplacement = true
numberToTake = 6
randomSeed = 100
words.takeSample(withReplacement, numberToTake, randomSeed)
保存结果数据到文件
saveAsTextFile
要保存到文本文件,只需指定路径和压缩编解码器即可:
words.saveAsTextFile(“file:/tmp/bookTitle”)
要设置压缩编解码器,我们必须从Hadoop导入正确的编解码器。 可以在org.apache.hadoop.io.compress库中找到这些:
// in Scala
import org.apache.hadoop.io.compress.BZip2Codec
words.saveAsTextFile("file:/tmp/bookTitleCompressed", classOf[BZip2Codec])
sequenceFile
sequenceFile是一个平面文件,由二进制键值对组成。
words.saveAsObjectFile("/tmp/my/sequenceFilePath")
caching
缓存RDD的原理与DataFrame和Dataset的原理相同。 您可以缓存或持久RDD。 默认情况下,缓存和持久性仅处理内存中的数据。 如果使用本章前面引用的setName函数,则可以命名它。
words.cache()
查询它的存储级别:
// in Scala
words.getStorageLevel
#in Python
words.getStorageLevel()
Checkpointing
DataFrame API中不可用的一项功能是检查点的概念。 检查点是将RDD保存到磁盘的行为,以便将来对此RDD的引用指向磁盘上的那些中间分区,而不是从其原始源重新计算RDD。
这类似于缓存,除了不存储在内存中,仅存储在磁盘上。 这在执行迭代计算时可能会有所帮助,类似于缓存的用例:
spark.sparkContext.setCheckpointDir("./checkpointing")
words.checkpoint()
Pipe RDDs to System Commands(将RDD传递到系统命令)
我们可以使用一个简单的示例,并将每个分区通过管道传递给命令wc。
每行将作为新行传递,因此,如果执行行计数,我们将获得行数,每个分区一个:
words.pipe(“wc -l”).collect()
这里每个分区得到了5行
mapPartitions
上一条命令显示,Spark在实际执行代码时会按分区运行。
您可能之前也已经注意到map函数的返回签名在RDD上实际上是MapPartitionsRDD。 这是因为map只是mapPartitions的行别名,这使您可以映射单个分区(表示为迭代器)。 这是因为从物理上讲,我们在群集上分别对每个分区(而不是特定的行)进行操作。
一个简单的示例为数据中的每个分区创建值“ 1”,以下表达式的总和将计算我们拥有的分区数:
// in Scala
words.mapPartitions(part => Iterator[Int](1)).sum() // 2
# in Python
words.mapPartitions(lambda part: [1]).sum() # 2
其他类似于mapPartitions的功能包括mapPartitionsWithIndex。
这样,您可以指定一个函数(该函数可以接受索引)(在分区内)和一个迭代器,该迭代器可以遍历分区内的所有项目。
分区索引是RDD中的分区号,它标识数据集中每个记录的位置(并可能允许您调试)。
可以使用它来测试您的map函数是否行为正确:
// in Scala
def indexedFunc(partitionIndex:Int, withinPartIterator: Iterator[String]) = {
withinPartIterator.toList.map(
value => s"Partition: $partitionIndex => $value").iterator
}
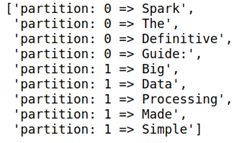
words.mapPartitionsWithIndex(indexedFunc).collect()
# in Python
def indexedFunc(partitionIndex, withinPartIterator):
return ["partition: {} => {}".format(partitionIndex,
x) for x in withinPartIterator]
words.mapPartitionsWithIndex(indexedFunc).collect()
返回了如下结果:
glom
glom它获取数据集中的每个分区并将其转换为数组。
如果您要将数据收集到驱动程序,并希望每个分区都有一个数组,这将很有用。 但是,这可能会导致严重的稳定性问题,因为如果分区较大或大量的分区,很容易使驱动程序崩溃。 在下面的示例中,您可以看到我们得到了两个分区,每个单词都属于一个分区:
// in Scala
spark.sparkContext.parallelize(Seq("Hello", "World"), 2).glom().collect()
// Array(Array(Hello), Array(World))
# in Python
spark.sparkContext.parallelize(["Hello", "World"], 2).glom().collect()
# [['Hello'], ['World']]