Spark: The Definitive Guide:Chapter 15. How Spark Runs on a Cluster(Spark是如何在集群上运行的)
Spark权威指南:第15章 Spark是如何在集群上运行的
Thus far in the book, we focused on Spark’s properties as a programming interface. We have discussed how the structured APIs take a logical operation, break it up into a logical plan, and convert that to a physical plan that actually consists of Resilient Distributed Dataset (RDD) operations that execute across the cluster of machines. This chapter focuses on what happens when Spark goes about executing that code. We discuss this in an implementation-agnostic way—this depends on neither the cluster manager that you’re using nor the code that you’re running. At the end of the day, all Spark code runs the same way.
到目前为止,我们关注的是Spark作为编程接口的性质。我们讨论了结构化API如何形成一个逻辑操作,分解成一系列逻辑既然,然后转换成又RDD操作组成的物理计划,并最终在及其集群上运行。这一章关注的是当Spark如何执行那些代码。我们用一种与实现无关的方式——几步依赖你使用的集群管理员也不依赖你运行的程序。说到底,所有Spark程序的运行方式都是一样的。
This chapter covers several key topics:
这一章的关键点有:
- The architecture and components of a Spark Application
Spark应用程序的架构和组件 - The life cycle of a Spark Application inside and outside of Spark
Spark应用程序在Spark内部或外部的生命周期 - Important low-level execution properties, such as pipelining
重要的低级执行特性,如pipelining - What it takes to run a Spark Application, as a segue into Chapter 16.
运行Spark应用程序需要的工作,作为第16章的提示
Let’s begin with the architecture.
让我们从构架开始。
The Architecture of a Spark Application
In Chapter 2, we discussed some of the high-level components of a Spark Application. Let’s review those again:
在第2章中,我们讨论了一些Spark应用成绩的一些高级组件。让我们再次回顾这些知识:
The Spark driver
- The driver is the process “in the driver seat” of your Spark
Application. It is the controller of the execution of a Spark
Application and maintains all of the state of the Spark cluster (the
state and tasks of the executors). It must interface with the cluster
manager in order to actually get physical resources and launch
executors. At the end of the day, this is just a process on a
physical machine that is responsible for maintaining the state of the
application running on the cluster.
driver是Spark应用程序“坐在驾驶员座位”的进程。驱动是Spark应用程序执行的控制者,并且维护Spark集群(executor的状态和任务)的所有状态。driver必须和集群管理员交互,从而实际获得物理资源并启动executor。最终,这就是一个物理机器上,负责维护在集群上运行的应用程序的状态的进程。
The Spark executors
- Spark executors are the processes that perform the tasks assigned by
the Spark driver. Executors have one core responsibility: take the
tasks assigned by the driver, run them, and report back their state
(success or failure) and results. Each Spark Application has its own
separate executor processes.
executor是运行Spark driver分配的任务的进程。executor只有一个核心职责:接受driver分配的任务,运行任务,反馈状态(成功或失败)和结果。每一个Spark应用程序都有各自独立的executor进程。
The cluster manager
- The Spark Driver and Executors do not exist in a void, and this is
where the cluster manager comes in. The cluster manager is
responsible for maintaining a cluster of machines that will run your
Spark Application(s). Somewhat confusingly, a cluster manager will
have its own “driver” (sometimes called master) and “worker”
abstractions. The core difference is that these are tied to physical
machines rather than processes (as they are in Spark). Figure 15-1
shows a basic cluster setup. The machine on the left of the
illustration is the Cluster Manager Driver Node. The circles
represent daemon processes running on and managing each of the
individual worker nodes. There is no Spark Application running as of
yet—these are just the processes from the cluster manager.
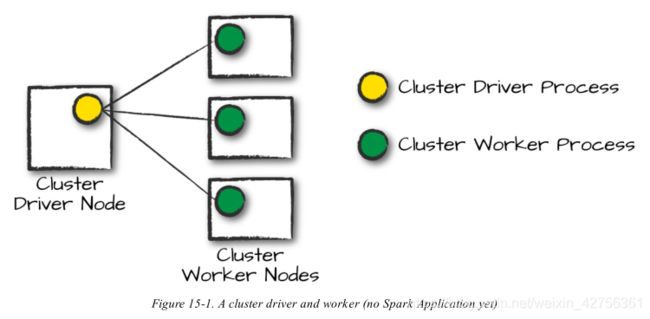
Driver和Executor不是凭空存在的,这也就是需要集群管理员的地方。集群管理员负责维护运行Spark应用程序的机器集群。多少会让人有些困惑的是,集群管理员有自己的driver(有时称之为master)和worker概念。核心差异在于这些都是绑定在物理机器上的,而不是进程(如同在Spark中)。图15-1展示了一个基础的集群。图左边的机器是集群管理员driver节点。圆圈代表正在运行管理各个worker节点的守护进程。这张图没有反映Spark应用程序的润兴——这些仅仅是集群管理员的进程。
When it comes time to actually run a Spark Application, we request resources from the cluster manager to run it. Depending on how our application is configured, this can include a place to run the Spark driver or might be just resources for the executors for our Spark Application. Over the course of Spark Application execution, the cluster manager will be responsible for managing the underlying machines that our application is running on.
当真正开始运行一个Spark应用程序,我们从集群管理员请求资源并运行它。按照应用程序是如何配置的,这可以包含一个运行Spark driver的位置,或者仅仅是我们Spark应用程序executor所需的资源。在Spark应用程序的运行期间,集群管理员会负责管理运行应用程序的下层机器。
Spark currently supports three cluster managers: a simple built-in standalone cluster manager, Apache Mesos, and Hadoop YARN. However, this list will continue to grow, so be sure to check the documentation for your favorite cluster manager.
Spark目前支持三种集群管理:简单的内置standalone集群管理员,Apache Mesos,和Hadoop YARN。然而,这个清单会持续增长,所以确保检查你最喜欢的集群管理员的文档。
Now that we’ve covered the basic components of an application, let’s walk through one of the first choices you will need to make when running your applications: choosing the execution mode.
现在我们己经讲解了应用程序的基础组件。让我们着手第一个需要做的选择,从而运行你的应用程序:选择运行模式。
Execution Modes
An execution mode gives you the power to determine where the aforementioned resources are physically located when you go to run your application. You have three modes to choose from:
Cluster mode
Client mode
Local mode
运行模式让你可以决定在运行应用程序时前文提到的资源如何在物理上分布。你有三种模式可以选择:集群模式,客户端模式,本地模式。
We will walk through each of these in detail using Figure 15-1 as a template. In the following section, rectangles with solid borders represent Spark driver process whereas those with dotted borders represent the executor processes.
以图15-1为模板,我们将详细的讨论这几种模式。在后面的部分,实线矩形代表Spark driver进程,虚线矩形代表executor进程。
Cluster mode
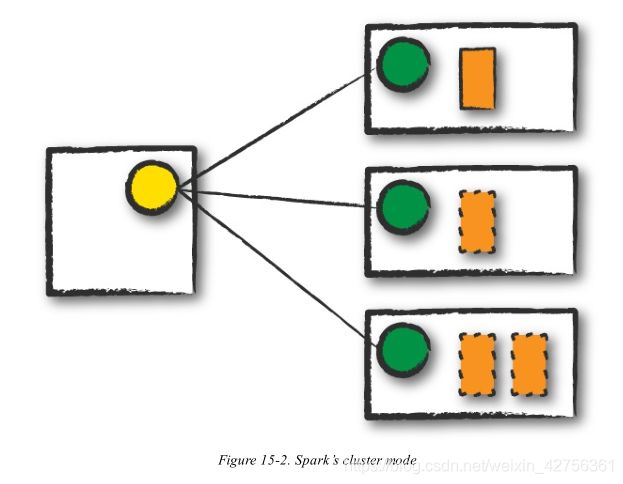
Cluster mode is probably the most common way of running Spark Applications. In cluster mode, a user submits a pre-compiled JAR, Python script, or R script to a cluster manager. The cluster manager then launches the driver process on a worker node inside the cluster, in addition to the executor processes. This means that the cluster manager is responsible for maintaining all Spark Application–related processes. Figure 15-2 shows that the cluster manager placed our driver on a worker node and the executors on other worker nodes.
集群模式可能是最常用的运行Spark应用程序的方法。使用集群模式,用户提交一个预编译的JAR包,Python脚本,或R脚本到集群管理员。集群管理员随后在集群的一个worker节点运行driver进程,除了executor进程以外。这意味着集群管理员负责维护所有Spark应用程序相关的进程。图15-2展示了集群管理员将driver放置到一个worker节点,将executor放置到其他worker节点。
Client mode
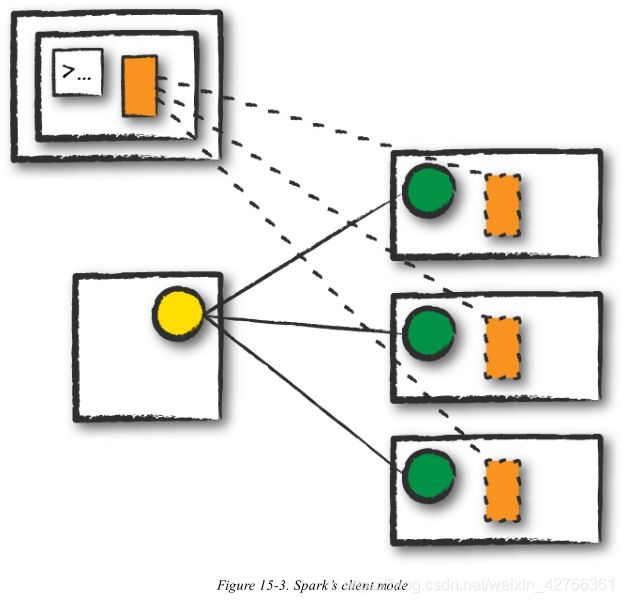
Client mode is nearly the same as cluster mode except that the Spark driver remains on the client machine that submitted the application. This means that the client machine is responsible for maintaining the Spark driver process, and the cluster manager maintains the executor processses. In Figure 15-3, we are running the Spark Application from a machine that is not colocated on the cluster. These machines are commonly referred to as gateway machines or edge nodes. In Figure 15-3, you can see that the driver is running on a machine outside of the cluster but that the workers are located on machines in the cluster.
客户端模式几乎和集群模式相同,除了Spark driver保留在提交应用程序的客户端机器上。这意味着客户机会负责维护Spark diver进程,集群管理员护卫executor进程。在图15-3中,我们从一台集群意外的机器运行Spark应用程序。这些机器通常被称为入口机器或者边缘机器。在图15-3中,你可以看到driver在集群以外的机器运行而worker位于集群的机器中。
Local mode
Local mode is a significant departure from the previous two modes: it runs the entire Spark Application on a single machine. It achieves parallelism through threads on that single machine. This is a common way to learn Spark, to test your applications, or experiment iteratively with local development. However, we do not recommend using local mode for running production applications.
本地模式和前面两种模式有巨大的差异:本地模式下整个Spark应用程序都在一台机器上运行。通过一台机器上的线程实现并行计算。这个模式通常用来学习Spark,测试程序或在本地开发模式下反复试验。然而,对于生产环境不我们不建议使用本地模式。
The Life Cycle of a Spark Application (Outside Spark)
This chapter has thus far covered the vocabulary necessary for discussing Spark Applications. It’s now time to talk about the overall life cycle of Spark Applications from “outside” the actual Spark code. We will do this with an illustrated example of an application run with spark-submit (introduced in Chapter 3). We assume that a cluster is already running with four nodes, a driver (not a Spark driver but cluster manager driver) and three worker nodes. The actual cluster manager does not matter at this point: this section uses the vocabulary from the previous section to walk through a step-by-step Spark Application life cycle from initialization to program exit.
这一章到目前为止已经涵盖了讨论Spark应用程序所必须的词汇。现在是时候讨论Spark应用程序从“外部”到实际Spark核心的生命周期。我们将通过一个Spark-submit运行的案例说明这点(在第3章有介绍)。我们假设集群已经在四个节点上运行,一个driver节点(不是Spark driver而是集群管理员driver)和三个worker节点。实际集群管理员在这个时候并不起作用:这一节使用上一节的词汇来一步步分析Spark应用程序从初始化到程序退出的生命周期。
NOTE
This section also makes use of illustrations and follows the same notation that we introduced previously. Additionally, we
now introduce lines that represent network communication. Darker arrows represent communication by Spark or Spark-
related processes, whereas dashed lines represent more general communication (like cluster management communication).
这一节也会用到图解并且遵守我们之前介绍的标志。此外,我们现在介绍代表网络通信的线条。暗色的箭头代表Spark或Spark相关进程的通信,点划线代表更广泛的通信(比如集群管理通信)
Client Request
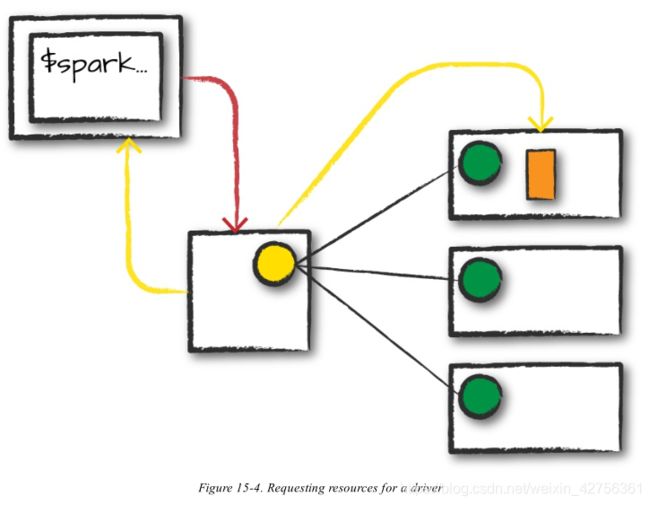
The first step is for you to submit an actual application. This will be a pre-compiled JAR or library. At this point, you are executing code on your local machine and you’re going to make a request to the cluster manager driver node (Figure 15-4). Here, we are explicitly asking for resources for the Spark driver process only. We assume that the cluster manager accepts this offer and places the driver onto a node in the cluster. The client process that submitted the original job exits and the application is off and running on the cluster.
首先你要提交一个实际的应用程序。这是一个预编译的JAR或库。这时,你在本地机器上运行代码,并且向集群管理员driver节点提出申请(15-4)。这里,我们仅仅为Spark driver请求资源。我们假设集群管理员接受了这个请求,将driver放置在集群的一个节点上。提交原始作业的进程仍存在,应用程序是关闭的并在集群上运行。
To do this, you’ll run something like the following command in your terminal:
为了完成这些工作,你需要在终端运行类似于下面的代码:
./bin/spark-submit
–class
–master
–deploy-mode cluster
–conf =
… # other options
[application-arguments]
Launch
Now that the driver process has been placed on the cluster, it begins running user code (Figure 15-5). This code must include a SparkSession that initializes a Spark cluster (e.g., driver + executors). The SparkSession will subsequently communicate with the cluster manager (the darker line), asking it to launch Spark executor processes across the cluster (the lighter lines). The number of executors and
their relevant configurations are set by the user via the command-line arguments in the original spark-submit call.
现在驱动进程已经被放置在了集群上,开始运行用户代码(图15-5)。这些代码必须包含一个SparkSession初始化一个Spark集群(driver+executors)。SparkSeesion随后会和集群管理员通信(暗色线条),要求他在集群(浅色线条)间运行executor进程。executor的数量和他们的相关配置都在原始spark-submit调用时通过命令行参数设置。
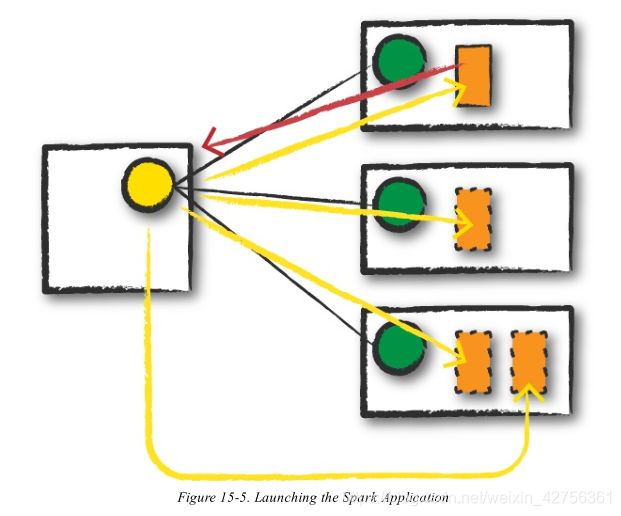
The cluster manager responds by launching the executor processes (assuming all goes well) and sends the relevant information about their locations to the driver process. After everything is hooked up correctly, we have a “Spark Cluster” as you likely think of it today.
集群管理员通过运行executor进程(假设都正常运作)向SparkSession做出响应,并且将关于位置的相关信息发送给driver进程。当一切工作都就位,我们就有一个你想象的“Spark 集群”。
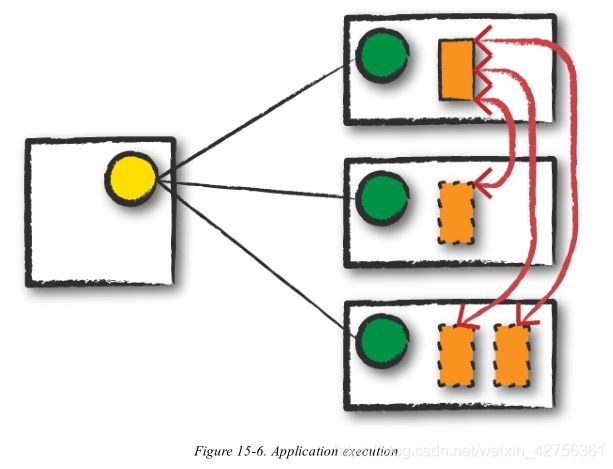
Execution
Now that we have a “Spark Cluster,” Spark goes about its merry way executing code, as shown in Figure 15-6. The driver and the workers communicate among themselves, executing code and moving data around. The driver schedules tasks onto each worker, and each worker responds with the status of those tasks and success or failure. (We cover these details shortly.)
现在我们有一个“Spark集群了”,Spark将会开始执行代码,如在图15-6中所示。driver和worker之间相互通信,执行并且相互传递数据。driver在每一个worker上计划任务,每一个worker都反馈任务的进度,成功或失败的状态。
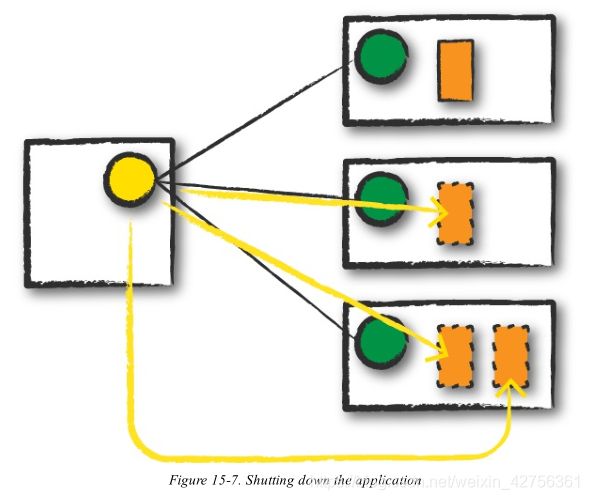
Completion
After a Spark Application completes, the driver processs exits with either success or failure (Figure 15-7). The cluster manager then shuts down the executors in that Spark cluster for the driver. At this point, you can see the success or failure of the Spark Application by asking the cluster manager for this information.
当一个Spark应用程序完成了,driver进程要么成功退出要么失败退出。集群管理员随后为driver关闭Spark进群里面的executor。最后,你可以向集群管理员查询Spark应用程序执行成功与否。
The Life Cycle of a Spark Application (Inside Spark)
We just examined the life cycle of a Spark Application outside of user code (basically the infrastructure that supports Spark), but it’s arguably more important to talk about what happens within Spark when you run an application. This is “user-code” (the actual code that you write that defines your Spark Application). Each application is made up of one or more Spark jobs. Spark jobs within an application are executed serially (unless you use threading to launch multiple actions in parallel).
我们刚刚了解了不考虑用户代码时Spark应用程序的生命周期(支持Spark的基础),但是更重要的是弄明白运行程序时,Spark内部发生了什么。这就是“用户代码”(你实际编写的代码用来定义Spark应用程序)。每一个应用程序是由一个或多个Spark作业组成。Spark作业在一个应用程序是是顺序执行的(除非你使用线程并行多个action)。
The SparkSession
The first step of any Spark Application is creating a SparkSession. In many interactive modes, this is done for you, but in an application, you must do it manually.
任何Spark应用程序的第一步都是创建一个SparkSession. 在很多交互式模式下,这一步已经为你完成了,但是在应用程序中,你必须手动完成这件事。
Some of your legacy code might use the new SparkContext pattern. This should be avoided in favor of the builder method on the SparkSession, which more robustly instantiates the Spark and SQL Contexts and ensures that there is no context conflict, given that there might be multiple libraries trying to create a session in the same Spark Appication:
// Creating a SparkSession in Scala
在Scala中创建SparkSession
import org.apache.spark.sql.SparkSession
val spark = SparkSession.builder().appName(“Databricks Spark Example”)
.config(“spark.sql.warehouse.dir”, “/user/hive/warehouse”)
.getOrCreate()
# Creating a SparkSession in Python
在Python中创建Spark中创建SparkSession
from pyspark.sql import SparkSession
spark = SparkSession.builder.master(“local”).appName(“Word Count”)
.config(“spark.some.config.option”, “some-value”)
.getOrCreate()
After you have a SparkSession, you should be able to run your Spark code. From the SparkSession, you can access all of low-level and legacy contexts and configurations accordingly, as well. Note that the SparkSession class was only added in Spark 2.X. Older code you might find would instead directly create a SparkContext and a SQLContext for the structured APIs.
当你已经具有一个SparkSession,你就可以运行你的Spark代码了。从SparkSession你可以访问低级和遗留的上下文对象已经配置文件。注意SparkSession类是从Spark 2.X开始引入的。你会发现以前的代码为了使用结构化API会直接创建一个SparkContext和SQLContext。
The SparkContext
A SparkContext object within the SparkSession represents the connection to the Spark cluster. This class is how you communicate with some of Spark’s lower-level APIs, such as RDDs. It is commonly stored as the variable sc in older examples and documentation. Through a SparkContext, you can create RDDs, accumulators, and broadcast variables, and you can run code on the cluster. For the most part, you should not need to explicitly initialize a SparkContext; you should just be able to access it through the SparkSession. If you do want to, you should create it in the most general way, through the getOrCreate method:
SparkSession中的SparkContext代表连接到了Spark集群。这个类可以让你和一些Spark低级API如RDD进行通信。SparkContext通常以变量sc存储在以前的案例和文档中。通过SparkContext你可以创建RDD,累加器,广播变量,你可以在集群上运行代码。大多数情况下,你不应该直接显示初始化一个SparkContext,你应该通过SparkSession访问它。如果你要这么做,你应该用最常用的方法创建它,使用getOrCreate方法:
// in Scala
import org.apache.spark.SparkContext
val sc = SparkContext.getOrCreate()
THE SPARKSESSION, SQLCONTEXT, AND HIVECONTEXT
In previous versions of Spark, the SQLContext and HiveContext provided the ability to work with DataFrames and Spark SQL and were commonly stored as the variable sqlContext in examples, documentation, and legacy code. As a historical point, Spark 1.X had effectively two contexts. The SparkContext and the SQLContext. These two each performed different things. The former focused on more fine-grained control of Spark’s central abstractions, whereas the latter focused on the higher-level tools like Spark SQL. In Spark 2.X, the communtiy combined the two APIs into the centralized SparkSession that we have today. However, both of these APIs still exist and you can access them via the SparkSession. It is important to note that you should never need to use the SQLContext and rarely need to use the SparkContext.
在之前的Spark的版本中,SQLContext和HiveContext提供了使DataFrame和Spark SQL的入口,通常在案例中,文档中,遗留代码中被存储为标量sqlContext。作为一个历史性的时刻,Spark 1X具有两个context。SparkContext和SQLContext。这两个Context执行不同的任务。前者关注更为细致的控制Spark的中心抽象对象,后者关注高级工具比如Spark SQL。在Spark 2.X中,社区将两个API合并到今天我我们使用的SparkSession中。然后,这些API任然存在并且可以通过SparkSession访问。值得注意的是,你应该永远不要使用SQLContext而且也很少会用到SparkContext。
After you initialize your SparkSession, it’s time to execute some code. As we know from previous chapters, all Spark code compiles down to RDDs. Therefore, in the next section, we will take some logical instructions (a DataFrame job) and walk through, step by step, what happens over time.
初始化SparkSession之后,是时候执行代码了。如我们从之前的章节了解 的,所有Spark代码会被编译到RDD级别。因此,在下一节中,我们会列举几个逻辑指令(a DataFrame job)并一步一步深入研究发生了什么。
Logical Instructions
As you saw in the beginning of the book, Spark code essentially consists of transformations and actions. How you build these is up to you—whether it’s through SQL, low-level RDD manipulation, or machine learning algorithms. Understanding how we take declarative instructions like DataFrames and convert them into physical execution plans is an important step to understanding how Spark runs on a cluster. In this section, be sure to run this in a fresh environment (a new Spark shell) to follow along with the job, stage, and task numbers.
如你在本书开头所见,Spark代码实质上由变换算子和行动算子组成。如何构建这些算子由你自己决定——既可以通过SQL,低级RDD操作,也可以是机器学习算法。理解如何使用陈述型指令如DataFrame并转换成物理执行计划,对于理解Spark在集群上是如何运行的是十分关键的步骤。在这一节中,确保开启一个新的Spark shell,在一个新的环境中运行代码,从而跟踪job,stage和任务数量。
Logical instructions to physical execution
We mentioned this in Part II, but it’s worth reiterating so that you can better understand how Spark takes your code and actually runs the commands on the cluster. We will walk through some more code, line by line, explain what’s happening behind the scenes so that you can walk away with a better understanding of your Spark Applications. In later chapters, when we discuss monitoring, we will perform a more detailed tracking of a Spark job through the Spark UI. In this current example, we’ll take a simpler approach. We are going to do a three-step job: using a simple DataFrame, we’ll repartition it, perform a value-by-value manipulation, and then aggregate some values and collect the final result.
我们在第二部分提到,但是值得在重复一边,所以你能够更好的理解Spark如何提取你的代码,并在集群上实际运行指令。我们会一行一行的说明一些代码,解释现象背后的工作,从而让你更好的理解你的Spark应用程序。在后一节中,当我们讨论监视,我们会通过Spark UI更细致的追踪Spark作业。这目前的案例中,我们会使用简单一些的方法。我们将会做三个阶段的作业:使用一个简单的DataFrame,重分区,对每一个值进行操作,聚合一些值,收集结果。
**NOTE
This code was written and runs with Spark 2.2 in Python (you’ll get the same result in Scala, so we’ve omitted it). The
number of jobs is unlikely to change drastically but there might be improvements to Spark’s underlying optimizations that
change physical execution strategies.
这段代码是使用Python语言,在Spark 2.2上编写并运行。作业的数目应该不会有较大的变化,但是可能会由于Spark低层的优化而改变物理执行策略。
**
# in Python
df1 = spark.range(2, 10000000, 2)
df2 = spark.range(2, 10000000, 4)
step1 = df1.repartition(5)
step12 = df2.repartition(6)
step2 = step1.selectExpr(“id * 5 as id”)
step3 = step2.join(step12, [“id”])
step4 = step3.selectExpr(“sum(id)”)
step4.collect() # 2500000000000*
When you run this code, we can see that your action triggers one complete Spark job. Let’s take a
look at the explain plan to ground our understanding of the physical execution plan. We can access
this information on the SQL tab (after we actually run a query) in the Spark UI, as well:
当你运行这段代码,会触发一个完整的spark job。让我们看看解释计划从而很好的理解物理执行计划。我们可以在Spark UI的SQL tab上访问这些信息:
step4.explain()

What you have when you call collect (or any action) is the execution of a Spark job that individually consist of stages and tasks. Go to localhost:4040 if you are running this on your local machine to see the Spark UI. We will follow along on the “jobs” tab eventually jumping to stages and tasks as we proceed to further levels of detail.
当你调用collect算子(或其他行动算子)会执行Spark作业,Spark作业由独立的stage和task组成。如果你在本地运行可以通过localhost:4040查看Spark UI。我们会追踪“作业” tab并随着不断研究细节的不断深入,最终进去stage和task层面。
A Spark Job
In general, there should be one Spark job for one action. Actions always return results. Each job breaks down into a series of stages, the number of which depends on how many shuffle operations need to take place.
一般来说,一个Spark 作业对应一个action。action总是会返回结果。每一个作业分解成一系列的stage,stage的数量取决于有多少shuffle操作会发生。
This job breaks down into the following stages and tasks:
作业分解成以下stage和task:
Stage 1 with 8 Tasks
Stage 2 with 8 Tasks
Stage 3 with 6 Tasks
Stage 4 with 5 Tasks
Stage 5 with 200 Tasks
Stage 6 with 1 Task
I hope you’re at least somewhat confused about how we got to these numbers so that we can take the time to better understand what is going on!
我希望你先在已经被我们如何获得这些数据搞懵逼了。这样我们就可以更好的理解发生了什么。
Stages
Stages in Spark represent groups of tasks that can be executed together to compute the same operation on multiple machines. In general, Spark will try to pack as much work as possible (i.e., as many transformations as possible inside your job) into the same stage, but the engine starts new stages after operations called shuffles. A shuffle represents a physical repartitioning of the data—for example, sorting a DataFrame, or grouping data that was loaded from a file by key (which requires sending records with the same key to the same node). This type of repartitioning requires coordinating across executors to move data around. Spark starts a new stage after each shuffle, and keeps track of what order the stages must run in to compute the final result.
Spark里面的stage是指可以再在不同电脑上,一起执行相同操作的task组。一般来说,Spark会尽可能压缩多的工作(尽量多的在job中包含变换算子),但是当操作调用shuffle时会计算引擎会启动新的stage。shuffle代表着对数据的重分区——比如,排序一个DataFrame,按key对加载的文件进行分组(需要将具有相同key的记录发送给同一个节点)。这种类型的重分区需要协调executor相互传递数据。Spark每一次shuffle都会启动新的stage,并持续追踪stage计算最终结果所必须遵守的运行顺序。
In the job we looked at earlier, the first two stages correspond to the range that you perform in order to create your DataFrames. By default when you create a DataFrame with range, it has eight partitions. The next step is the repartitioning. This changes the number of partitions by shuffling the data. These DataFrames are shuffled into six partitions and five partitions, corresponding to the number of tasks in stages 3 and 4.
在我们之前看的job中,前两个stage对应的是创建DataFrame的range方法。默认情况下,当使用range方法创建DataFrame,数据具有8个分区。下一步是重分区。这一步通过shuffle数据对数据进行重分区。这些DataFrame被shuffle进入6个分区和5个分区,对应stage3和stage4里面task的数量。
Stages 3 and 4 perform on each of those DataFrames and the end of the stage represents the join (a shuffle). Suddenly, we have 200 tasks. This is because of a Spark SQL configuration. The spark.sql.shuffle.partitions default value is 200, which means that when there is a shuffle performed during execution, it outputs 200 shuffle partitions by default. You can change this value, and the number of output partitions will change.
Stage 3和4分别在DataFrame上执行,stage的结束代表join(shuffle)操作。突然的我们有个200个task。这是因为Spark SQL的配置。spark.sql.shuffle.partition默认值为200,表明当执行一个shuffle时,会默认输出200个shuffle分区。你可以修改这个值,从而改变输出分区数量。
TIP
We cover the number of partitions in a bit more detail in Chapter 19 because it’s such an important parameter. This value
should be set according to the number of cores in your cluster to ensure efficient execution. Here’s how to set it:
提示
我们会在19章更深入的讲解分区的数量,因为这是一个极为重要的参数。这个参数应当按照集群核心数目设置从而保证高校的执行。这里是设置方法:
spark.conf.set(“spark.sql.shuffle.partitions”, 50)
A good rule of thumb is that the number of partitions should be larger than the number of executors on your cluster, potentially by multiple factors depending on the workload. If you are running code on your local machine, it would behoove you to set this value lower because your local machine is unlikely to be able to execute that number of tasks in parallel. This is more of a default for a cluster in which there might be many more executor cores to use. Regardless of the number of partitions, that entire stage is computed in parallel. The final result aggregates those partitions individually, brings them all to a single partition before finally sending the final result to the driver. We’ll see this configuration several times over the course of this part of the book.
一个好的规则是分区的数量应当比集群executor数量多,可以按照workload乘以特定的系数计算分区数目。如果你在本地运行代码,建议你减小这个值因为你的本地机器不太可能并行这么多的任务。对于由更多executor核心可用的集群,这个值应当大于默认值。不论分区的数量如何,整个stage是并行计算的。最后的结果分别聚合这些分区,把结果带到一个分区并发送最终结果给driver。我们会在本书这部分的课程中多次看到这个配置。
Tasks
Stages in Spark consist of tasks. Each task corresponds to a combination of blocks of data and a set of transformations that will run on a single executor. If there is one big partition in our dataset, we will have one task. If there are 1,000 little partitions, we will have 1,000 tasks that can be executed in parallel. A task is just a unit of computation applied to a unit of data (the partition). Partitioning your data into a greater number of partitions means that more can be executed in parallel. This is not a panacea, but it is a simple place to begin with optimization.
Spark中Stage由task组成。每一个task对应将在同一个executor运行的一组数据块和一组变换操作。如果dataset中只有一个大分区,我们只会获得一个task。如果偶1,000个小分区,我们会获得1,000个可以并行执行的task。一个task是一个作用在一个数据单元(分区)上的一个计算单元。将你的数据划分到更多的分区上以为着更多的task可以并行计算。这不是万能药,但是对于优化提供了一个较为容易方法。
Execution Details
Tasks and stages in Spark have some important properties that are worth reviewing before we close out this chapter. First, Spark automatically pipelines stages and tasks that can be done together, such as a map operation followed by another map operation. Second, for all shuffle operations, Spark writes the data to stable storage (e.g., disk), and can reuse it across multiple jobs. We’ll discuss these
concepts in turn because they will come up when you start inspecting applications through the Spark UI.
Spark中的task和stage有一些重要的性质值得我们在结束这一章前再回顾一次。首先,Spark自动pipeline可以一起执行的stage和task,比如说一个map操作紧跟着另一个map操作。第二,对于所有的shuffle操作,Spark将数据写入稳定的存储介质,并且可以在多个任务重重新使用。我们将会按顺序讨论这些概念,因为当你开始通过Spark UI查看应用程序时就会遇到这些概念。
Pipelining 输送
An important part of what makes Spark an “in-memory computation tool” is that unlike the tools that came before it (e.g., MapReduce), Spark performs as many steps as it can at one point in time before writing data to memory or disk. One of the key optimizations that Spark performs is pipelining, which occurs at and below the RDD level. With pipelining, any sequence of operations that feed data directly into each other, without needing to move it across nodes, is collapsed into a single stage of tasks that do all the operations together. For example, if you write an RDD-based program that does a map, then a filter, then another map, these will result in a single stage of tasks that immediately read each input record, pass it through the first map, pass it through the filter, and pass it through the last map function if needed. This pipelined version of the computation is much faster than writing the intermediate results to memory or disk after each step. The same kind of pipelining happens for a DataFrame or SQL computation that does a select, filter, and select.
一个关键的部分使Spark成为“基于内存的计算工具”是,不同于它之前的工具(MapReduce),Spark在写入数据到内存或者硬盘之前,尽可能执行多个步骤。Spark执行的一个重要的优化就是pipelining,在RDD层级或低于RDD层级下执行。有了pipelining,任何直接相互提供数据而不需要在节点之间传输数据,都被折叠到一个stage,一次性完成所有的操作。比如,如果你编写一个基于RDD的程序执行一个map操作,然后是过滤,然后在进行一次map,最终结果将会是单个由多个task组成的stage,立即读取每一个输入记录,传递给第一个map,传递个过滤,传递个最后一个map按照需要。这个pipelining版本的计算要远远快于每一个步骤都写入中间结果到内存或硬盘。相同类型的pipelining也应用于DataFrame或SQL计算当执行一个select,filter和select。
From a practical point of view, pipelining will be transparent to you as you write an application—the Spark runtime will automatically do it—but you will see it if you ever inspect your application through the Spark UI or through its log files, where you will see that multiple RDD or DataFrame operations were pipelined into a single stage.
从实践的角度来看,当你编写应用程序时,pipelining对你是不可见的——Spark运行环境会自动处理——但是当你通过Spark UI或log文件检查应用程序时,你会看到多个RDD或DataFrame操作被pipeline到单个stage。
Shuffle Persistence 混洗持久化
The second property you’ll sometimes see is shuffle persistence. When Spark needs to run an operation that has to move data across nodes, such as a reduce-by-key operation (where input data for each key needs to first be brought together from many nodes), the engine can’t perform pipelining anymore, and instead it performs a cross-network shuffle. Spark always executes shuffles by first having the “source” tasks (those sending data) write shuffle files to their local disks during their execution stage. Then, the stage that does the grouping and reduction launches and runs tasks that fetch their corresponding records from each shuffle file and performs that computation (e.g., fetches and processes the data for a specific range of keys). Saving the shuffle files to disk lets Spark run this
stage later in time than the source stage (e.g., if there are not enough executors to run both at the same time), and also lets the engine re-launch reduce tasks on failure without rerunning all the input tasks.
第二个你有时会看到的性质是shuffle persistence。当Spark执行的操作需要将数据在节点之间相互传输,比如reduce-by-key操作(每一个key的输入数据需要首先从不同的节点收集到一起),计算引擎就无法再执行pipeline,取而代之的是,执行跨节点shuffle。Spark执行shuffle时,总是先将“源”task(发送数据的那些)在执行stage期间写入shuffle文件到本地磁盘。然后在执行group和reduce的stage启动并运行task,这些task从每一个shuffle文件抓取他们对应的记录,执行计算(抓取和处理指定范围的key对应的数据)。保存shuffle文件到磁盘使得Spark可以在source stage完成后及时运行这一stage(如果没有足够的executor同时运行这个两个stage),而且如果发生失败,可以是引擎再次启动reduce task而不需要再次运行输入task。
One side effect you’ll see for shuffle persistence is that running a new job over data that’s already been shuffled does not rerun the “source” side of the shuffle. Because the shuffle files were already written to disk earlier, Spark knows that it can use them to run the later stages of the job, and it need not redo the earlier ones. In the Spark UI and logs, you will see the pre-shuffle stages marked as “skipped”. This automatic optimization can save time in a workload that runs multiple jobs over the same data, but of course, for even better performance you can perform your own caching with the DataFrame or RDD cache method, which lets you control exactly which data is saved and where. You’ll quickly grow accustomed to this behavior after you run some Spark actions on aggregated data and inspect them in the UI.
你将会看到shuffle持久化的一个副作用是,当在一个已经shuffle的数据上运行新的作业,不会再次运行“source”。因为shuffle文件已经被写入到磁盘上,Spark知道可以使用这些数据来运行后续作业的stage,而不需要重做之前的stage。在Spark UI和log文件中,你会看到shuffle前stage被标记为“跳过”。这个自动优化当运行多个作业在相同的数据上时,可以借阅时间,但是,为了更好的表现,你可以自行对DataFrame或RDD执行缓冲方法,这可以让你准确的控制那些数据被保存以及保存到哪里。你很快就会适应这一做法,当你有一定在已经聚合的数据上执行Spark行动算子并在UI中检查作业的经验。
Conclusion
In this chapter, we discussed what happens to Spark Applications when we go to execute them on a
cluster. This means how the cluster will actually go about running that code as well as what happens
within Spark Applications during the process. At this point, you should feel quite comfortable
understanding what happens within and outside of a Spark Application. This will give you a starting
point for debugging your applications. Chapter 16 will discuss writing Spark Applications and the
things you should consider when doing so.