Pandas处理缺失数据
处理缺失数据
- 判断是否/NA值
-
- pandas.isnull()方法
- pandas.notnull()方法
- 过滤缺失数据
-
- 对Series对象过滤
- 对DataFrame对象过滤
- 填充缺失数据
判断是否/NA值
Pandas使用浮点值Nan(Not a number)表示浮点和非浮点数组中的确实数据.
NA处理的方法主要有isnull()方法和notnull()方法.
首先我们导入库
import pandas as pd
import numpy as np
from numpy import nan as NA
然后我们准备一个实验数据
data=pd.Series([1,NA,5.3,NA,7])
data
0 1.0
1 NaN
2 5.3
3 NaN
4 7.0
dtype: float64
pandas.isnull()方法
判断哪些是/NA值,是/NA值返回True,否则返回Flase,返回值为布尔类型
data.isnull()#判断哪些是/NA值,是/NA值返回True,否则返回Flase
0 False
1 True
2 False
3 True
4 False
dtype: bool
pandas.notnull()方法
判断哪些是/NA值,是/NA值返回Flase,否则返回True,返回值为布尔类型
data.notnull()#判断哪些是/NA值,是/NA值返回Flase,否则返回True
0 True
1 False
2 True
3 False
4 True
dtype: bool
过滤缺失数据
对Series对象过滤
对于Series对象,Dropna返回一个仅含有非空数据和索引值的Series.
data.dropna()
通过notnull()方法也可以达到对Series对象的过滤目的
data[data.notnull()]
两个代码出来的几个都是一样的,输出结果如下.
0 1.0
2 5.3
4 7.0
dtype: float64
对DataFrame对象过滤
Series对象是一个一维的数据,不需要去考虑是按照行还是按照列去过滤,也不需要去看是按照全部舍弃还是部分舍弃NA.
首先 先上实验数据
data1=pd.DataFrame([[1.,6.5,3.],[1.,NA,NA],[NA,NA,NA],[NA,6.5,3.]])
data1
输出结果:

drop()方法默认丢弃任何含有缺失值的行.
data1.dropna()#默认行删除,保留每行完全没有NaN的数据
输出结果:

由输出结果可以看出,dropna()方法将所有包含了NaN的的行都删除了,那么我们怎么将不是全部都是NaN的行保留呢?这个就需要引入dropna()方法的how参数.
data1.dropna(how='all')
输出结果:

由输出结果看出,加了how="all"参数后,整行不全是NaN的数据都被保留了.
dropna()方法是默认按照行删除,那么我们怎么按照列删除呢,这个就需要用到参数axis.
当axis=0时候,按照行删除;
当axis=1时候,按照列删除.
实验数据原来没用全部是NaN的列,那么我们先给实验数据添加一列全是NaN的数据,然后再将全部包含NaN的列删除.
data1[10]=NA
data1
输出结果:
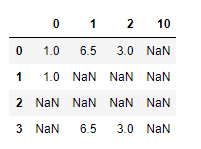
data1.dropna(axis=1,how="all")#只删除全部是NaN的列
输出结果:

data1.dropna(axis=1)#按列过滤所有含有NaN的列
输出结果

在涉及到时间序列数据,想保留一部分数据,可以使用thresh参数来实现
thresh参数表示如果一行(列)除去NA值,剩余数据的数量大于等于n,便显示这一行(列)。
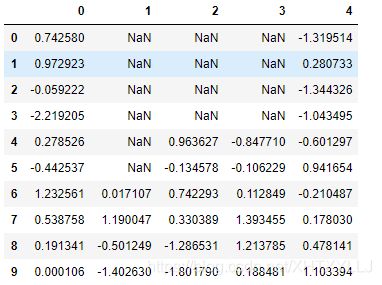
df=pd.DataFrame(np.random.randn(10,5))
df.iloc[:6,1]=NA
df.iloc[:4,2:4]=NA
df
输出结果:
df.dropna(thresh=3) #按照行,将
输出结果:

df.dropna(axis=1,thresh=5)#按照列过滤
输出结果:

在数据分析时,缺失数据比例高于30%,则可以选择直接删除数据,如果低于30%时,我们就可以使用特定的数据来对缺失值的填充替换,这些特定数据可以是0,也可以是均值,中位数,众数等.
填充缺失数据
使用fillna()方法就是实现填充缺失数据的重要方法.
fillna()方法有五个参数
| 参数 | 描述 |
|---|---|
| values | 用于填充缺失值的值或者字典对象 |
| method | 填充方式,默认"ffill",取上值填充 |
| axis | 填充方向,axis=0表示,axis=1表示 |
| inplace | 直接在被填充的数据对象上修改 |
| limit | 连续填充的最大数量 |
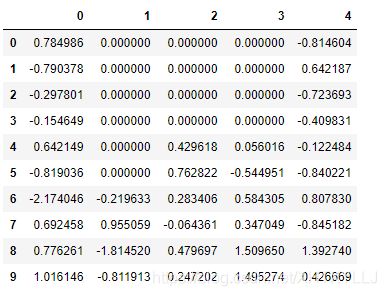
使用值填充缺失值
df.fillna(0)#使用指定值0替换NaN值
输出结果:
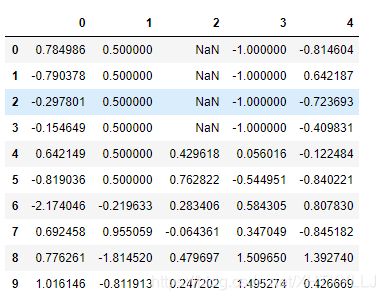
使用字典填充缺失值:
df.fillna({
1:0.5,3:-1})#通过字典调用fillna实现对不同列的填充不同的值
输出结果:
fillna()方法默认返回的是副本对象,如要对被调用的数据进行就地修改,而不是修改副本,那么需要设置参数inplace=True就可以实现.
df.fillna(0,inplace=True)
df
输出结果:

reindex重置索引的差值方法都可以用到fillna()方法上.
df=pd.DataFrame(np.random.randn(8,4))
df.iloc[2:7,1]=NA
df.iloc[4:7,2]=NA
df.iloc[5:7,3]=NA
df
输出结果:
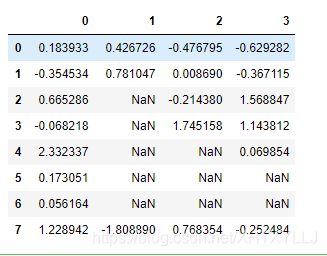
df.fillna(method="ffill")#向下填充或者向前填充
输出结果:
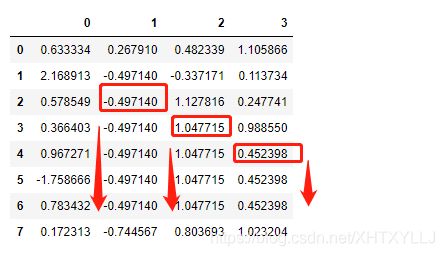
df.fillna(method="bfill")#向上填充或者向后填充
输出结果:

参数method可以决定差值的当时,默认是ffill或者pad(向下填充亦称向前填充),bfill或者backfill(向上填充亦称向后填充)
使用fillna()方法有很多的功能都可以实现,例如
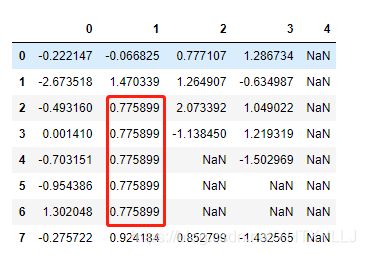
df.fillna({
1:df[1].mean()})#直接将第2列缺失值使用该列已有值的均值去填充替换NaN
输出结果
好了 今天就到这来.