Python之手把手教你用JS逆向爬取网易云40万+评论并用stylecloud炫酷词云进行情感分析
本文借鉴了@平胸小仙女的知乎回复 https://www.zhihu.com/question/36081767
写在前面:
文章有点长,操作有点复杂,需要代码的直接去文末即可。想要学习的需要有点耐心。当我理清所有逻辑后,我抑郁的(震惊的)发现,只需要改下歌曲ID就可以爬取其他任意歌曲的评论了!生成的TXT文件在程序同一目录。
有基础的可能觉得我比较啰嗦,因为我写博客一是为了记录下知识点,在遗忘的时候可以查看回顾下。二是因为我学编程的时候,搜到的很多帖子都是半残的,有些人是为了引流到自己的公众号,有些人干脆是骗流量,有的帖子质量很好,但是对小白不太友好,没有相关基础很难复现。这样就在搜索上浪费了很多时间。我写博客尽量把每一步操作都记录下来,这样别人能复现我的成果,对着一个可以运行的程序,才会有学习的欲望。先学会操作,再去弄懂原理,然后就可以写出自己的程序了!至于技术原理,网上的大牛太多了,想学的话很容易学到。我希望看到我的博客的小白,不至于在操作上浪费太多时间,能有时间用到学习技术原理上。
当然也有一部分是猎奇的,希望直接复制就能运行,这样的呢,给我点个赞就行啦!毕竟谁不是从白嫖怪一步一步成长起来的呢,好奇心是最好的老师。
可能遇到的麻烦:
ModuleNotFoundError: No module named ‘Crypto‘ 踩坑
用到的工具:
手把手教你下载安装配置Fiddler 和 Fiddler Everywhere
PyCharm中文指南2.0
词云清洗用到的stopwords.txt:
Python文本分析之常用最全停用词表(stopwords)
词云清洗的分析参见:
Python爬取你好李焕英豆瓣短评并利用stylecloud制作更酷炫的词云图
F12大法开启:
打开网易云网页版,找到一首喜爱的音乐,我选择的是柏松的《世间美好与你环环相扣》,然后开启F12大法!

现在开始作法:按F12,选中network(也可以右键–>检查–>network),然后F5刷新页面,就可以看到network的活动:
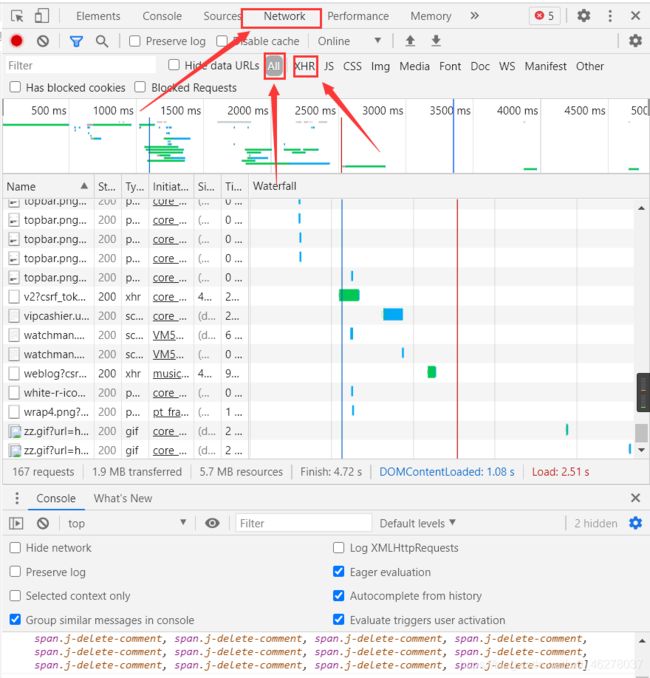
点击评论的下一页,发现只有评论会刷新成下一页的评论,网页的URL没有变,说明向服务器发送的请求是XHR(XMLHttpRequest)对象。所有现代浏览器均支持 XMLHttpRequest 对象(IE5 和 IE6 使用 ActiveXObject)。XMLHttpRequest 用于在后台与服务器交换数据。这意味着可以在不重新加载整个网页的情况下,对网页的某部分进行更新。
完全不懂的小白可以学这个入下门:
https://www.w3cschool.cn/ajax/ajax-xmlhttprequest-create.html

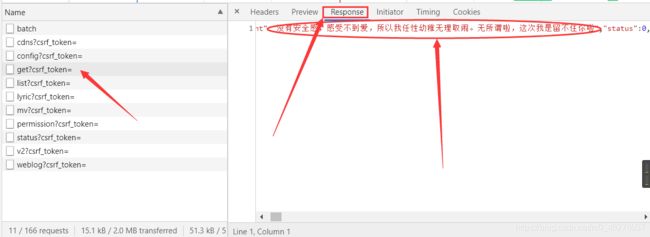
这样就缩小了排查范围,选中XHR,会发现少了很多,但是还有十多条,这就没办法了,可以自己瞎猜,我是一个一个点进去,然后选中Response,这样一个个的找到包含评论的数据包的。当然你操作的时候页面跟我的不太一样,因为这些框框都是可以拖动的,需要看哪一部分的时候可以拖动使得需要的部分变大,突出的显示出来。
对比上图,就是这个了:
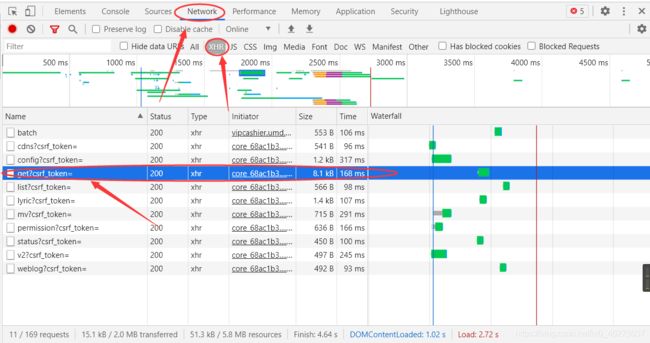
点进去,选中Headers,就可以看到Request Headers

以及两个参数params和encSecKey

在Response里可以看到当前页的所有评论,但也只是当前页的,其他页的评论如何获取呢?
点击下一页的时候只刷新评论,而不会重新加载页面。那么既然这个进程是向服务器发起获取评论的请求,我们点击下一页看看这个进程会有什么变化。
第一页:

第二页:
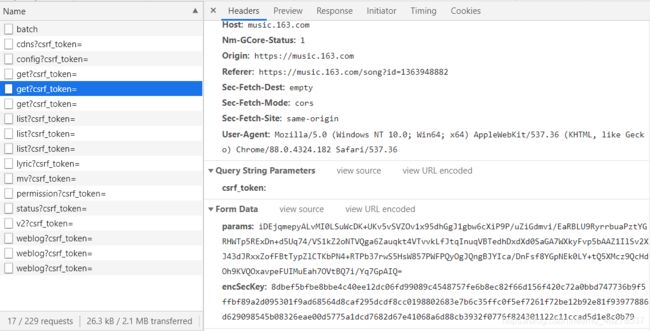
第三页:

可以发现只有这两个参数 params和encSecKey会随之改变,进而Response也刷新成了下一页的评论。由此得出结论:这是通过不同页面的params以及encSecKey参数的不同来向服务器发起获取相应评论的请求。
js线上调试:
因此,下一步就是弄清楚不同页面的params以及encSecKey参数是如何改变的,这样我们就能在爬虫程序中通过生成随页面变化的这两个参数,发送至服务器获取相应的Response。
这两个参数一看就是js加密的,而这个进程的initiator是core_68ac1b3aadf40a20caba599a0ab2365d.js

一般这样的js都是没法看的,因此就点进去并save as将core_68ac1b3aadf40a20caba599a0ab2365d.js下载到本地查看。以下简称core.js。
切记切记!!!一定要先点这个美化按钮!!!然后再保存!!!没有一个教程帖子告诉我这点,然后我就傻不拉叽的直接保存了!!!!当然你也可以不点不美化,毕竟我第一次没有美化也做出来了。
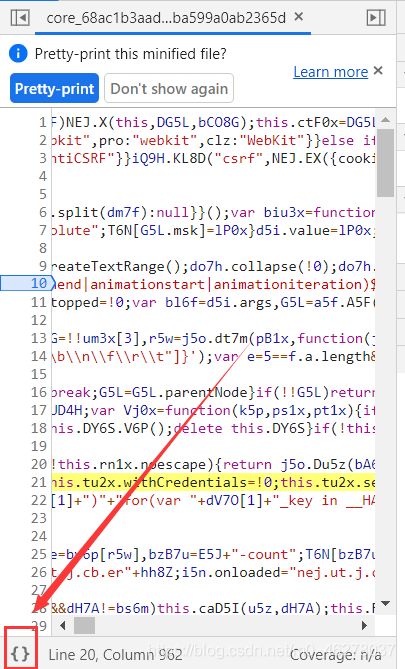
右键,Save as 就可以保存了,选个自己知道的路径,等下有用!
打开core.js,我用的是Sublime Text。
这就是你不点美化的后果!!!找不同吧!!!
这是美化后的:
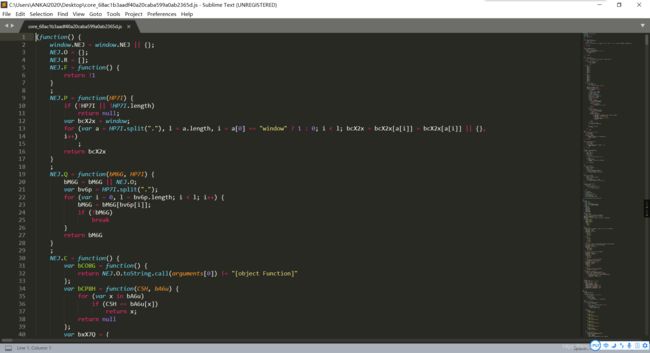
搜索params和encSecKey,查找这两个参数:

可以看到这两个参数都是bWv4z函数中的变量,(PS:细心的读者会注意到后面的截图不再是bWv4z,其他参数也有微小变化,是因为我出去吃了个饭,回来后core.js已经失效,网易云更新了这个,所以我重新下载编辑了,不影响学习。)而这个函数也就是window.asrea这个函数。暂且不管window.asrea这个函数是如何实现的,可以看到它有四个参数,先不管这四个参数是哪来的,可以先把它们输出到console看一下,这时候就需要线上调试js。首先将本地的core.js文件添加几行代码,以便使这四个参数显示出来:

把第2、3、4个参数先注释掉,因为要一个一个的获取。
接着要用到Fiddle Everywhere了,下载安置配置见本文开头链接。
点击打开AutoResponder,然后点Add New Rule
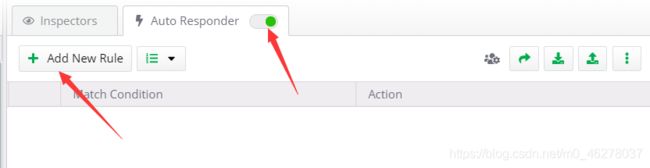
弹出
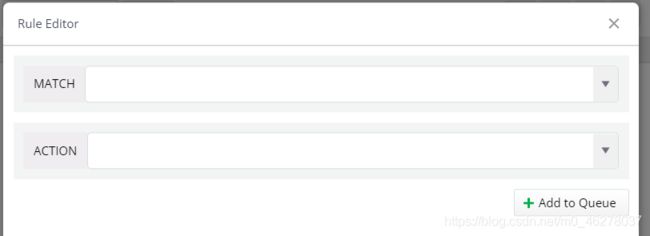
先看MATCH:
回到这里,这次点Open in new tab
在弹出的页面复制URL,注意不是美化后的,是美化前的。可以点叉把美化后的关了,再右键Open in new tab
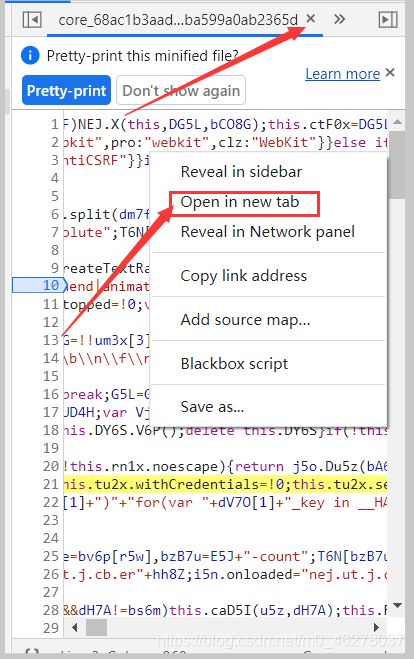
复制URL

注意不是这个:

把复制的URL粘贴到MATCH
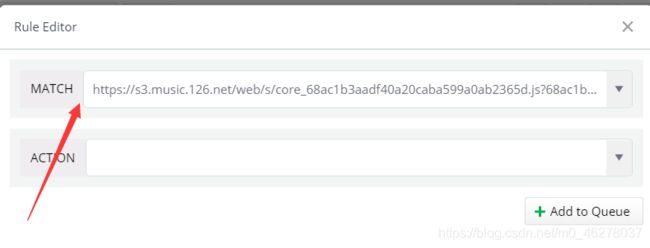
然后看ACTION

选中之前保存的core.js,就是core_68ac1b3aadf40a20caba599a0ab2365d.js
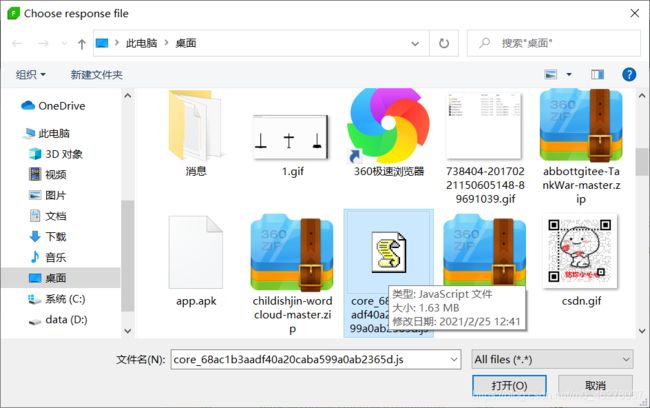
最后点Add to Queue
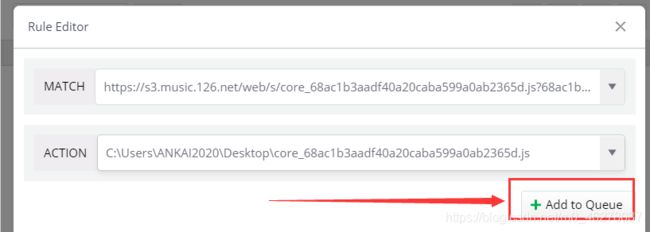
这样就完成了:
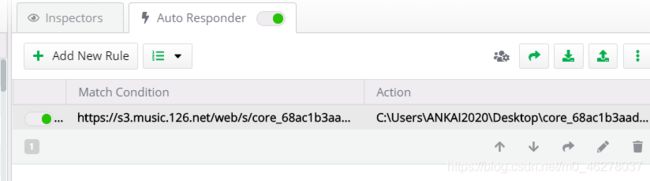
这步实际就是用本地修改过得core.js文件替换服务器的core.js对请求作出响应。
这些设置完之后,清除浏览器缓存,刷新页面,就可以在console里面看到输出的参数了。
什么?没看到?清除浏览器缓存啊,重启浏览器啊,重启Fiddle Everywhere啊,还看不到?
看不到就对了,因为在Sublime Text 中编辑完后没有保存啊!
保存下,再刷新:
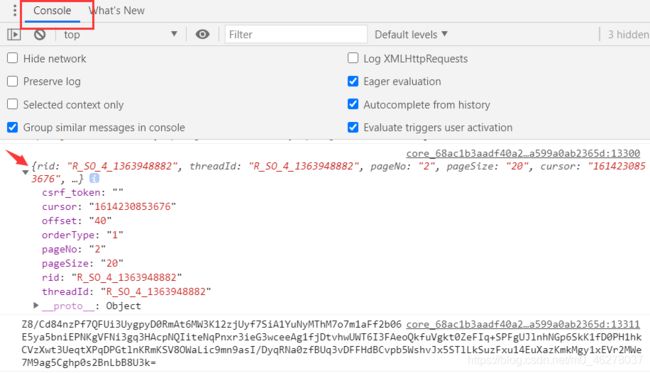
如图,分别是第一页和第二页的第一个参数值
第一页:

第二页:
在这里,我遇到了最大的难题,至今未解决。
这是我试了N久得到的一些数据,至今没有找到规律用数学公式写出来。可能是网抑云的新的反爬方法吧。有人要试的话,记得每次都要F5刷新,有时候刷新一次还不行,比如在获取2万多页后的数据时,每次显示还不一样,我又清空浏览器缓存刷新几次,数据不变了才记录下来。因为页码是不能选的,只能这么一下下点击。

数据:

都做到这了,总不能半途而废吧,我就参考了其他人的数据:

我发现网上所有的教程截图全是这样的数据,偏偏我的不一样?????应该是网易云反爬的措施吧。
这样的数据好处理:rid就是R_SO_4_加上歌曲的id,offset就是(评论页数-1) * 20,total在第一页是true,其余是false。
百思不得其解怪来了!!!后面的代码用的就是这几个以前的参数,程序竟然跑起来了!!!
不管了,继续学原理!
按这样的方式可以得到其余三个参数:
这样,别忘了保存,然后清空浏览器缓存,再刷新:
第二个参数值:

010001

第三个参数值:
00e0b509f6259df8642dbc35662901477df22677ec152b5ff68ace615bb7b725152b3ab17a876aea8a5aa76d2e417629ec4ee341f56135fccf695280104e0312ecbda92557c93870114af6c9d05c4f7f0c3685b7a46bee255932575cce10b424d813cfe4875d3e82047b97ddef52741d546b8e289dc6935b3ece0462db0a22b8e7

第四个参数值:
0CoJUm6Qyw8W8jud

再次警告:
下载到本地的core.js文件要赶快使用,我中午出去吃了个饭,回来接着写的时候发现已经失效了


你看,参数已经发生了变化,快使用!噢应该着急的是我,我应该快截图,不然前面的步骤又要再演示一次了。
分析加密函数:
可以发现,只有第一个参数随页面变化,其余三个参数都是不变的常量。至此 ,这四个参数我们都能够在程序中通过代码生成了。
那么,现在我们只要知道函数window.asrsea如何处理的就可以了,定位到这个函数:
我是在Sublime Text这么find来定位的,console中也可以,但是我用不太好,就在这find了:
![]()
这是结果:
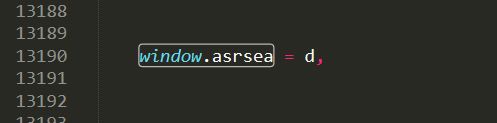
纳尼?d? 什么鬼?函数?
再find:
![]()
然后搜到了好多好多的d,比找对象还难找!这谁受得了啊!
去隔壁控制台搜下:

回车!啪!应声而出,原来是你啊!
读代码,里面还有个b函数,console一下:

不行,没办法了,find吧,还好已经知道b有两个参数了,而且还是个小写的 b :

同样的办法揪出来c函数:
好了,bcd函数都就出来的啊,开始读吧!
得,变量也是abcdef,果然网抑云啊!我抑郁了!!!
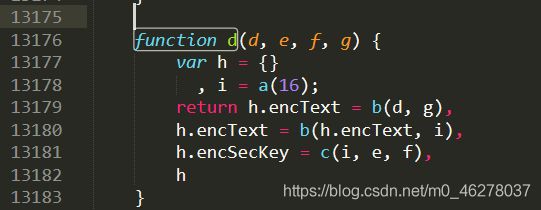
首先d函数:
function d(d, e, f, g) {
var h = {
}
, i = a(16);
return h.encText = b(d, g),
h.encText = b(h.encText, i),
h.encSecKey = c(i, e, f),
h
}
研究过后,你就会发现:i 就是一个长度为16的随机字符串,既然是随机的,就直接让他等于16个F了。这个encText明显就是params,encSecKey明显就是encSecKey。而b函数就是一个AES加密,encText的获得经过了两次加密,第一次对 d 也就是第一个参数加密,key是第四个参数,第二次对第一次加密结果进行加密,key是 i 。在b函数中我们可以看到:
- 小注解:高级加密标准(AES,Advanced Encryption
Standard)为最常见的对称加密算法(微信小程序加密传输就是用这个加密算法的)。对称加密算法也就是加密和解密用相同的密钥。
function b(a, b) {
var c = CryptoJS.enc.Utf8.parse(b)
, d = CryptoJS.enc.Utf8.parse("0102030405060708")
, e = CryptoJS.enc.Utf8.parse(a)
, f = CryptoJS.AES.encrypt(e, c, {
iv: d,
mode: CryptoJS.mode.CBC
});
return f.toString()
}
密钥偏移量iv是0102030405060708,模式是CBC,那么就不难写出对于第一个参数的加密了。
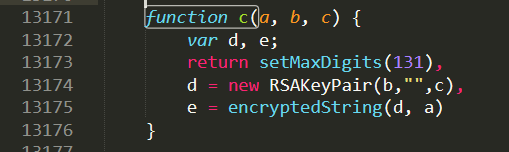
接下来是第二个参数encSecKey,你会发现c函数是一个RSA加密:
function c(a, b, c) {
var d, e;
return setMaxDigits(131),
d = new RSAKeyPair(b,"",c),
e = encryptedString(d, a)
}
- RSA加密是一种非对称加密。可以在不直接传递密钥的情况下,完成解密。这能够确保信息的安全性,避免了直接传递密钥所造成的被破解的风险。是由一对密钥来进行加解密的过程,分别称为公钥和私钥。两者之间有数学相关,该加密算法的原理就是对一极大整数做因数分解的困难性来保证安全性。通常个人保存私钥,公钥是公开的(可能同时多人持有)。
这里传入 c 的三个参数 i 是16个F,e 是第二个参数,f 是第三个参数,全部是固定的值,那么无论歌曲id或评论页数如何变化,这个encSecKey都不随之发生变化,所以这个encSecKey对我们来说就是个常量,抄一个下来就是可以使用的。
至此,我们就能在程序中通过代码获取params和encSecKey这两个参数了。
完整代码:
# -*- coding:utf-8 -*-
import urllib.request
import http.cookiejar
import urllib.parse
import json
import time
import codecs
from Crypto.Cipher import AES
import base64
import os
class music:
#初始化
def __init__(self):
#设置代理,以防止本地IP被封
self.proxyUrl = "http://202.106.16.36:3128"
#request headers,这些信息可以在ntesdoor日志request header中找到,copy过来就行
self.Headers = {
'Accept': "*/*",
'Accept-Language': "zh-CN,zh;q=0.9",
'Connection': "keep-alive",
'Host': "music.163.com",
'User-Agent':"Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.79 Safari/537.36"
}
# 使用http.cookiejar.CookieJar()创建CookieJar对象
self.cjar = http.cookiejar.CookieJar()
# 使用HTTPCookieProcessor创建cookie处理器,并以其为参数构建opener对象
self.cookie = urllib.request.HTTPCookieProcessor(self.cjar)
self.opener = urllib.request.build_opener(self.cookie)
# 将opener安装为全局
urllib.request.install_opener(self.opener)
#第二个参数
self.second_param = "010001"
#第三个参数
self.third_param = "00e0b509f6259df8642dbc35662901477df22677ec152b5ff68ace615bb7b725152b3ab17a876aea8a5aa76d2e417629ec4ee341f56135fccf695280104e0312ecbda92557c93870114af6c9d05c4f7f0c3685b7a46bee255932575cce10b424d813cfe4875d3e82047b97ddef52741d546b8e289dc6935b3ece0462db0a22b8e7"
#第四个参数
self.forth_param = "0CoJUm6Qyw8W8jud"
def get_params(self, page):
#获取encText,也就是params
iv = "0102030405060708"
first_key = self.forth_param
second_key = 'F' * 16
if page == 0:
first_param = '{rid:"", offset:"0", total:"true", limit:"20", csrf_token:""}'
else:
offset = str((page - 1) * 20)
first_param = '{rid:"", offset:"%s", total:"%s", limit:"20", csrf_token:""}' % (offset, 'false')
self.encText = self.AES_encrypt(first_param, first_key, iv)
self.encText = self.AES_encrypt(self.encText.decode('utf-8'), second_key, iv)
return self.encText
def AES_encrypt(self, text, key, iv):
#AES加密
pad = 16 - len(text) % 16
text = text + pad * chr(pad)
encryptor = AES.new(key.encode('utf-8'), AES.MODE_CBC, iv.encode('utf-8'))
encrypt_text = encryptor.encrypt(text.encode('utf-8'))
encrypt_text = base64.b64encode(encrypt_text)
return encrypt_text
def get_encSecKey(self):
#获取encSecKey
encSecKey = "257348aecb5e556c066de214e531faadd1c55d814f9be95fd06d6bff9f4c7a41f831f6394d5a3fd2e3881736d94a02ca919d952872e7d0a50ebfa1769a7a62d512f5f1ca21aec60bc3819a9c3ffca5eca9a0dba6d6f7249b06f5965ecfff3695b54e1c28f3f624750ed39e7de08fc8493242e26dbc4484a01c76f739e135637c"
return encSecKey
def get_json(self, url, params, encSecKey):
# post所包含的参数
self.post = {
'params': params,
'encSecKey': encSecKey,
}
# 对post编码转换
self.postData = urllib.parse.urlencode(self.post).encode('utf8')
try:
#发出一个请求
self.request = urllib.request.Request(url,self.postData,self.Headers)
except urllib.error.HTTPError as e:
print(e.code)
print(e.read().decode("utf8"))
#得到响应
self.response = urllib.request.urlopen(self.request)
#需要将响应中的内容用read读取出来获得网页代码,网页编码为utf-8
self.content = self.response.read().decode("utf8")
#返回获得的网页内容
return self.content
def get_hotcomments(self, url):
#获取热门评论
params = self.get_params(1)
encSecKey = self.get_encSecKey()
content = self.get_json(url, params, encSecKey)
json_dict = json.loads(content)
hot_comment = json_dict['hotComments']
f = open('HotComments.txt', 'w', encoding='utf-8')
for i in hot_comment:
#将评论输出至txt文件中
time_local = time.localtime(int(i['time'] / 1000)) # 将毫秒级时间转换为日期
dt = time.strftime("%Y-%m-%d %H:%M:%S", time_local)
f.write('用户: ' + i['user']['nickname'] + '\n')
f.write('点赞数: ' + str(i['likedCount']) + '\n')
f.write('发表时间: ' + dt + '\n')
f.write('评论: ' + i['content'] + '\n')
f.write('-' * 40 + '\n')
f.close()
def get_allcomments(self, url):
#获取全部评论
params = self.get_params(1)
encSecKey = self.get_encSecKey()
content = self.get_json(url, params, encSecKey)
json_dict = json.loads(content)
comments_num = int(json_dict['total'])
f = open('AllComments.txt', 'w', encoding='utf-8')
present_page = 0
if (comments_num % 20 == 0):
page = comments_num / 20
else:
page = int(comments_num / 20) + 1
print("共有%d页评论" % page)
print("共有%d条评论" % comments_num)
# 逐页抓取
for i in range(page):
params = self.get_params(i + 1)
encSecKey = self.get_encSecKey()
json_text = self.get_json(url, params, encSecKey)
json_dict = json.loads(json_text)
present_page = present_page + 1
for i in json_dict['comments']:
# 将评论输出至txt文件中
time_local = time.localtime(int(i['time'] / 1000))# 将毫秒级时间转换为日期
dt = time.strftime("%Y-%m-%d %H:%M:%S", time_local)
f.write('用户: ' + i['user']['nickname'] + '\n')
f.write('点赞数: ' + str(i['likedCount']) + '\n')
f.write('发表时间: ' + dt + '\n')
f.write('评论: ' + i['content'] + '\n')
f.write('-' * 40 + '\n')
print("第%d页抓取完毕" % present_page)
f.close()
mail = music()
mail.get_hotcomments("https://music.163.com/weapi/v1/resource/comments/R_SO_4_1363948882?csrf_token")
mail.get_allcomments("https://music.163.com/weapi/v1/resource/comments/R_SO_4_1363948882?csrf_token")
执行:

2万页!!!当然是我去睡觉让Python慢慢的爬啦!
早上起来看到:

打开看看:
对比下:

最后一页:
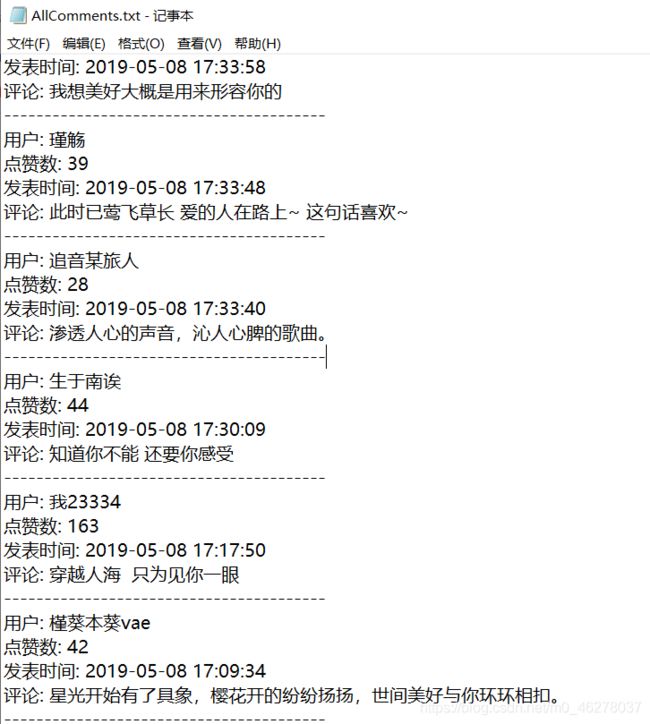
对比:
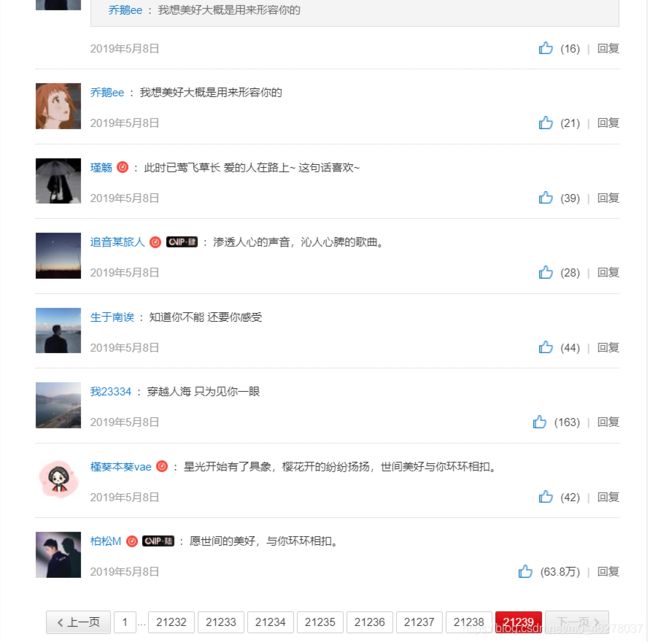
21239,哎呀,过了一夜又多了两页评论。
好了,到此结束!改下ID就可以爬其他人的啦!
情感分析:
接下来用stylecloud来进行情感分析。简单的把爬取的评论用词云展示出来不是分析,必须要经过词云清洗才行。所用的stopwords.txt是本文开头提到的,可以根据需要修改stopwords.txt。
由于评论过多的话爬取会消耗很多时间,所以情感分析另外建了个文件。
完整代码:
from stylecloud import gen_stylecloud
import jieba
def jieba_cloud(file_name, icon):
with open(file_name, 'r', encoding='utf8') as f:
word_list = jieba.cut(f.read())
result = " ".join(word_list) # 分词用 隔开
# 设置停用词
stopwords_file = open('stopwords.txt', 'r', encoding='utf-8')
stopwords = [words.strip() for words in stopwords_file.readlines()]
# 制作中文词云
icon_name = " "
if icon == "1":
icon_name = "fas fa-grin-hearts"
elif icon == "2":
icon_name = "fas fa-space-shuttle"
elif icon == "3":
icon_name = "fas fa-heartbeat"
elif icon == "4":
icon_name = "fas fa-bug"
elif icon == "5":
icon_name = "fas fa-thumbs-up"
elif icon == "6":
icon_name = "fab fa-qq"
pic = str(icon) + '.png'
if icon_name is not None and len(icon_name) > 0:
gen_stylecloud(text=result,
size=1024, # stylecloud 的大小(长度和宽度)
icon_name=icon_name,
font_path='simsun.ttc',
max_font_size=250, # stylecloud 中的最大字号
max_words=5000, # stylecloud 可包含的最大单词数
# stopwords=TRUE, # 布尔值,用于筛除常见禁用词
custom_stopwords=stopwords, # 定制停用词列表
output_name=pic)
else:
gen_stylecloud(text=result, font_path='simsun.ttc', output_name=pic)
return pic
# 主函数
if __name__ == '__main__':
jieba_cloud("AllComments.txt", "1")
jieba_cloud("AllComments.txt", "2")
jieba_cloud("AllComments.txt", "3")
jieba_cloud("AllComments.txt", "4")
jieba_cloud("AllComments.txt", "5")
jieba_cloud("AllComments.txt", "6")
效果:






