读完 DALL-E 论文,我们发现大型数据集也有平替版
内容提要: OpenAI 团队的新模型 DALL-E 刷屏,这一新型神经网络,使用 120 亿参数,经过「特训」,任意描述性文字输入后,都可以生成相应图像。如今,团队将这一项目的论文和部分模块代码开源,让我们得以了解这一神器背后的原理。
原创:HyperAI超神经
关键词:DALL-E 论文公开 神经网络 图文对数据集
年初,OpenAI 发布的图像 生成模型 DALL-E,彻底打破自然语言与图像之间的次元壁。
无论怎样夸张、不切实际的文字描述,一旦输入给 DALL-E,都可以生成对应的图像,效果惊艳了整个技术圈。
大力出奇迹:炼丹界的成本天花板
算力:1024 块 V 100
当时模型一出,开发者们纷纷猜测模型背后的实现过程,并期待官方论文。近日,DALL-E 的论文与部分实现代码终于公开:

论文地址:https://arxiv.org/abs/2102.12092
果然和此前一些开发者猜测相符,大厂 OpenAI 又一次展现了其强大的「钞能力」,论文中透露,它们在整个训练中,共使用了 1024 块 16GB 的 NVIDIA V100 GPU。
代码部分,官方目前只开放了用于图像重建部分的 dVAE 模块,该模块的目的是,减少在文本-图像生成任务中所训练的 Transformer 的内存占用。而 Transformer 代码部分还没有公开,只能期待后续更新。不过,即使有了代码,这个 GPU 用量也不是人人都有能力去复现的。
上线不到一周,项目已获 star 1.6k,项目地址:https://github.com/openai/DALL-E
数据集:2.5 亿个图像文本对 + 120 亿参数
在论文中,OpenAI 团队介绍道,利用机器学习合成方法,实现从文本到图像转换的相关研究,从 2015 年就开始了。
不过,尽管此前这些研究中提出的模型,已经能够执行文本到图像的生成,但其生成结果仍存在很多问题,比如物体变形、不合理的物体放置,或前景和背景元素的不自然混合。
经过研究,团队发现,此前的研究通常都是在较小的数据集(例如 MS-COCO 和 CUB-200)上进行评估。据此,团队提出设想:数据集大小和模型大小是否有可能成为限制当前方法发展的因素呢?
于是,团队以此为突破口,从网上收集了一个**包含 2.5 亿个图像文本对的数据集,**在这一数据集上训练一个包含 120 亿个参数的自回归 Transformer。
另外,论文中介绍道,dVAE 模型的训练,共用了 **64 块 16GB 的 NVIDIA V100 GPU,**判别模型 CLIP 则共使用 256 块 GPU 训练了 14 天。
经过大力训(shao)练(qian)之后,团队最终得到了可通过自然语言控制的、灵活且真实度高的图像生成模型 DALL-E。
团队对 DALL-E 模型和其它模型生成的结果进行了对比与评估,结果是,在 90% 的情况下,DALL-E 的生成结果,比之前的研究结果更受欢迎。
图文对数据集平替款,真香
DALL-E 这一模型的成功,也用事实验证了,大规模训练数据对于一个模型的重要性。
平民炼丹师想要 DALL-E 的同款数据集,恐怕是难以获得了,但是大牌都有平替版(平价替代版)。
虽然 OpenAI 表示,他们的训练数据集尚不会公开,但他们透露,数据集中包括 Google 发表的 Conceptual Captions 数据集。
大型图文对数据集 mini 替代版
Conceptual Captions 数据集,由谷歌在 ACL 2018 发表的论文《Conceptual Captions: A Cleaned, Hypernymed, Image Alt-text Dataset For Automatic Image Captioning》中提出。

《Conceptual Captions:一个用于自动生成图像标题的图文对数据集》
该论文对数据和建模分类两方面都做出了贡献。首先,团队提出了一个新的图像标题注释数据集——Conceptual Captions,它包含的图像比 MS-COCO 数据集多一个数量级,共包括约 330 万图像和描述对。
Conceptual Captions(概念性标题)数据集详情
数据来源:Google AI
发布时间:2018 年
包含数量:330 万对图像-文字对
数据格式:.tsv 数据大小:1.7 GB
下载地址:https://hyper.ai/datasets/14682
用 ResNet+RNN+Transformer 打造逆向 DALL-E
在建模方面,基于先前的研究结果,团队使用 Inception-ResNet-v2 进行图像特征提取,然后使用基于 RNN 和 Transformer 的模型,生成图像的说明文字(DALL-E 由文字描述生成图片,Conceptual Captions 由图像生成文字注释)。
为了生成这个数据集,团队从一个 Flume pipepline 开始,该 pipeline 并行处理了约 10 亿个互联网网页,从这些网页中提取、过滤和处理候选图像和标题对,并保留那些通过几个过滤器的图像和标题对。
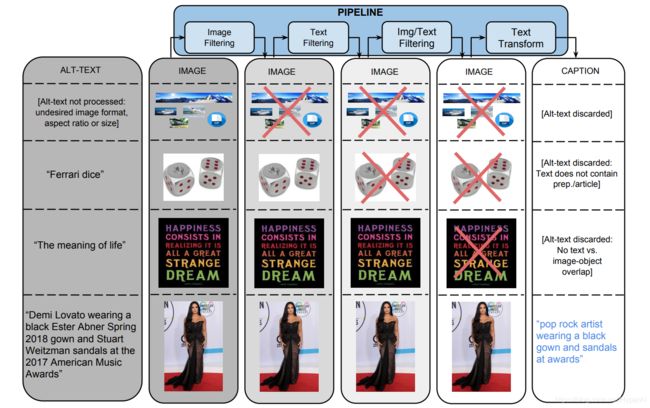
一:基于图像的过滤
算法 会根据编码格式、大小、纵横比和令人反感的内容过滤图像。它只保存两个维度都大于 400 像素的 JPEG 图像,并且大小维度的比例不超过 2。它排除了触发色情或亵渎检测的图像。最终,这些过滤器过滤掉了超过 65% 的候选数据。
二:基于文本的过滤
算法从 HTML 网页中获取描述文本(Alt-text),删除带有非描述性文本的标题 (如 SEO 标签或 hashtag),并根据预设的指标比如包含色情、脏话、亵渎、个人资料照片等注释的,均会被过滤。最终,只有 3% 的候选文本通过筛选。
除了基于图像和文本内容的单独过滤之外,还过滤掉那些文本标记都无法映射到图像内容的数据。
使用通过 Google Cloud Vision APIs 提供的 分类器 为图像分配类标签。
三:文本转换与超词化
数据集收集过程中,要处理来自约 10 亿个英文网页的 50 多亿张图片。在高精度过滤标准下,只有 0.2% 的图像、标题对通过了筛选,其余的标题往往是因为包含了专有名词(人物、地点、位置等)而被排除。
作者在非超同步化的 Alt-text 数据上训练了一个基于 RNN 的字幕模型,并在下图中给出了一个输出示例。

对于上图,原始描述:Jimmy Barnes 在悉尼娱乐中心表演;
模型输出描述:歌手贾斯汀·比伯在米高梅的 Billboard 音乐颁奖典礼上表演
团队使用谷歌云自然语言 API,获得了命名实体和语法依赖注释。然后,使用谷歌知识图谱 (KG) 搜索 API 来匹配命名实体和 KG 条目,并利用相关的 hypernym 术语。
例如,「Harrison Ford」和「Calista Flockhart」都标识为命名实体,因此将它们与相应的 KG 条目进行匹配。这些 KG 条目以「actor」作为它们的连词,然后用这个连词替换原来的表面标记。
结果评估
团队从数据集的测试集中,随机提取了 4000 个示例样本,对其进行了人工评估。在 3 个标注中,超过 90% 的标注获得了大多数的良好评价。
团队对比了 COCO 训练的模型和 Conceptual 训练的模型之间的区别。
其中,第一个区别是:基于 Conceptual 的训练结果比 COCO 依托自然界图片的训练结果,更具有社会性。
比如:下图最左边的图像,COCO-trained 模型使用「group of men」指代图像中的人物;而 Conceptual-trained 模型使用了更合适和更大信息量的术语「毕业生」。

第二个区别是:COCO-trained 模型似乎经常会「自行联想」,凭空「捏造」出一些描述。比如,其对第一张图片产生了「在楼房前」(in front of a building)的幻觉;对第二张图片产生了「时钟和两扇门」(a clock and two doors)的幻觉;对第三张图片产生了「生日蛋糕」(a birthday cake)的幻觉。相比之下 ,该团队的模型并未发现这种问题。
第三个区别是:适用的图像类型有所不同。由于 COCO 只包含自然图像,因此像上图中第四个这样的卡通图像,会给 COCO-trained 模型带来「联想」的干扰,如「毛绒玩具」、「鱼」、「车的一侧」之类的并不存在的事物。相比之下,Conceptual-trained 模型则可以轻松地处理这些图像。
DALL-E 模型的推出,也让很多该领域研究者感叹:数据真的是 AI 的基石。你也想尝试大力出奇迹吗?不如先从 Conceptual Captions 数据集开始吧!
访问 https://hyper.ai/datasets 或点击阅读原文,还可获取更多数据集哦!