-
- 2011年,
JDK7发布,1.7u4中,开始启用新的垃圾回收器G1(但是不是默认)。
- 2011年,
-
- 2017年,发布
JDK9,G1成为默认GC,代替CMS。(一般公司使用jdk8的时候,会通过参数,指定GC为G1)
- 2017年,发布
-
- 2018年,发布
JDK11,带来了革命性ZGC,性能比较强。
- 2018年,发布
虚拟机介绍
虚拟机,就是虚拟的计算机,可以执行一系列虚拟计算机指令,大体上可以分为系统虚拟机和程序虚拟机。它们运行时,都会受到虚拟机提供的资源的限制。
- 系统虚拟机:仿真模拟系统的,比如
Visual Box,VMware。 - 程序虚拟机:为执行单个计算机程序设计的,比如
Java虚拟机。
JAVA虚拟机
Java虚拟机是一台执行字节码的虚拟机计算机,但是字节码不一定是由Java语言编译而成。但是只要使用这一套虚拟机规则的语言,就可以享受到跨平台,垃圾收集以及可靠的即时编译器。JVM和硬件之间没有直接的交互。
- 一次编译,到处运行。
- 自动内存管理
- 自动垃圾回收
下面是ava平台文档中Java概念图的描述,可以看出javac命令在JDK中,也就是将.java文件编译成为.class文件,这个就是前端编译器,将源文件编译成为字节码。这个编译器不在JRE中,也说明了JRE不包括编译环境。
JRE和JDK都包括了JVM虚拟机。JRE是运行时环境,而JDK包含了开发环境。
JDK7 中java家族的结构组成 : https://docs.oracle.com/javas...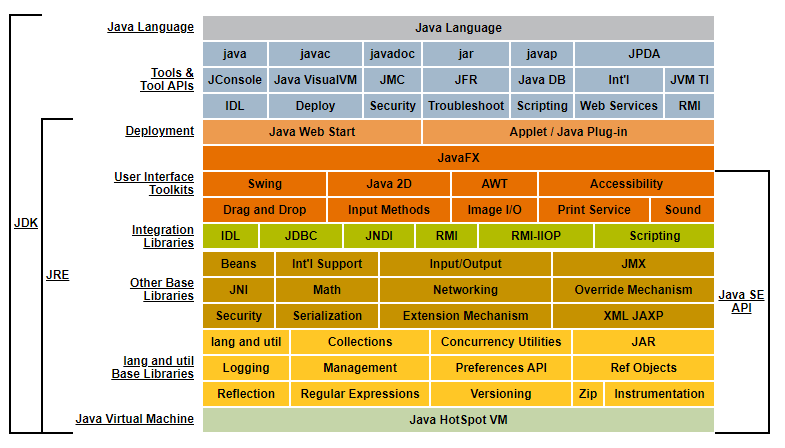
JDK7 中java家族的结构组成 : https://docs.oracle.com/javas...
JVM结构

上面的图主要包括三部分:类加载器,运行时数据区,执行引擎。
类加载器,主要是将Class文件(已经经过前端编译器编译后的字节码文件),加载到运行时数据区,生成Class对象,这个过程会设计加载,链接,初始化等过程。
运行时区域主要分为:
线程私有(每个线程有一份):
- 程序计数器:
Program Count Register,线程私有,没有垃圾回收 - 虚拟机栈:
VM Stack,线程私有,没有垃圾回收 - 本地方法栈:
Native Method Stack,线程私有,没有垃圾回收
- 程序计数器:
线程共享:
- 方法区:
Method Area,以HotSpot为例,JDK1.8后元空间取代方法区,有垃圾回收。 - 堆:
Heap,垃圾回收最重要的地方。
- 方法区:
执行引擎主要包括解释器和即时编译器(热点代码提前编译好,这是后端编译器),垃圾回收器。字节码文件不能直接被机器识别,所以需要执行引擎来做转换。
Java代码执行流程
Java代码变成字节码文件的过程中,其实包含了词法分析,语法分析,语法树,语义分析等一系列操作。

在执行引擎中,有JIT编译器,也就是第二次编译的过程会发生在这里,会将热点代码编译成为机器指令,是按照方法的维度,缓存起来(放在方法区),也称之为CodeCache。
JVM架构模型
Java编译器主要是基于栈的指令集架构,个人觉得主要原因是可移植性决定的,JVM需要跨平台。指令集架构主要有两种:
- 基于栈的指令集架构:一个方法相当于一个入栈的操作,执行完相当于出栈操作。
- 基于寄存器的指令集架构
基于栈的指令集架构的特点
主要特点:
- 设计实现简单,适用于资源受限的系统,比如机顶盒,小玩具上。
- 避开寄存器分配难题:使用零地址指令方式分配。
- 指令流中大部分都是零地址指令,执行过程依赖操作栈,指令集更小(零地址),编译器容易实现。
- 不需要硬件支持,可移植性强,容易实现跨平台。
基于寄存器架构的特点
- 典型应用是x86的二进制指令集
- 依赖于硬件,可移植性差
- 性能好,执行效率高
- 更少指令执行一项操作
- 大部分情况下,寄存器的架构,一,二,三地址指令为主,而基于栈的指令集却是以零地址指令为主。
说明:什么叫零地址指令,一地址指令,二地址指令?
零地址指令只有操作码,没有操作数。这种指令有两种情况:一是无需操作数,另一种是操作数为默认的(隐含的),默认为操作数在寄存器中,指令可直接访问寄存器。
- 三地址指令:一般地址域中A1、A2分别确定第一、第二操作数地址,A3确定结果地址。下一条指令的地址通常由程序计数器按顺序给出。
- 二地址指令:地址域中A1确定第一操作数地址,A2同时确定第二操作数地址和结果地址。
- 单地址指令:地址域中A 确定第一操作数地址。固定使用某个寄存器存放第二操作数和操作结果。因而在指令中隐含了它们的地址。
- 零地址指令:在堆栈型计算机中,操作数一般存放在下推堆栈顶的两个单元中,结果又放入栈顶,地址均被隐含,因而大多数指令只有操作码而没有地址域。
栈数据结构,一般只有入栈和出栈,所以操作的地方只有栈顶元素,所以位置是确定的,不需要地址。
例子
执行2+3的操作,如果是基于栈的计算流程:
iconst_2 // 常量2入栈
istore_1
iconst_3 // 常量3入栈
istore_2
iload_1
iload_2
iadd // 常量2,3出栈,执行相加
istore_0 // 结果5入栈基于寄存器的计算流程:
mov eax,2 //将eax寄存器的值设置为2
add eax,3 // 将eax寄存器的值加3从上面的例子可以看出来,基于栈的寄存器的指令更小,但是基于寄存器的指令更少。
我们可以通过一个简单程序看一下:
public class StackStructTest {
public static void main(String[] args) {
int i = 2 + 3;
}
}编译后,切换到class目录下,使用命令反编译:
java -v StackStructTest.class
看到字节码的模块,可以看到前面有iconst_5,其实5就是2+3的结果,也就是编译期间就会直接把2+3变成5,不会在运行的时候才去计算,这个是因为2和3都是常量。
这个现象称之为编译期的常量折叠。
但是如果我们把代码成下面这种情况呢?
int i = 2;
int j = 3;
int k = i + j;反编译出来的指令:
const意思是constant(常量),store是storeage寄存器。
stack=2, locals=4, args_size=1
0: iconst_2 // 2是个常量
1: istore_1 // 2加载到1号操作数栈
2: iconst_3 // 3是一个产量
3: istore_2 // 3加载到2号操作数栈
4: iload_1 // 将1号操作数栈取出,加载进来
5: iload_2 // 将2号操作数栈取出,加载进来
6: iadd // 两者相加
7: istore_3 // 结果存储到索引为3号操作数栈中
8: return也就是栈架构的JVM,需要 8 条指令才能完成上面的变量相加计算。
栈架构总结
由于跨平台特性,Java指令基于栈来设计,因为不同的CPU架构不同,优点是跨平台,指令集小,编译器容易实现。缺点是性能下降,实现同样功能需要更多指令。
【作者简介】:
秦怀,公众号【秦怀杂货店】作者,技术之路不在一时,山高水长,纵使缓慢,驰而不息。个人写作方向:Java源码解析,JDBC,Mybatis,Spring,redis,分布式,剑指Offer,LeetCode等,认真写好每一篇文章,不喜欢标题党,不喜欢花里胡哨,大多写系列文章,不能保证我写的都完全正确,但是我保证所写的均经过实践或者查找资料。遗漏或者错误之处,还望指正。
平日时间宝贵,只能使用晚上以及周末时间学习写作,关注我,我们一起成长吧~