python 整数转16进制bytes_【Python技术进阶10】Python数据类型bytes、bytearray详细指南...
为此,Python为我们提供了2个数据类型bytes、bytearray,专门用来存储以字节为单位的字节数据。并提供了一系列的方法将其它Python数据类型转为bytes或bytearray类型。
今天飞哥就给小伙伴分享bytes和bytearray的相关知识。有了这些知识,在进行二进制文件的读写操作了,就会更容易理解和掌握。
01 字节(byte)字节是计算机中数据存储的单位,1个字节由8个二进制的比特位组成,每个位的值要么是0要么是1,位是最小的存储单位。

由上面字节的描述,1个字节有8个位组成,每个位是1或0。因此,8个位全是0时最小,全是1时最大。所以,每个字节的表示范围为:0x00到0xFF。
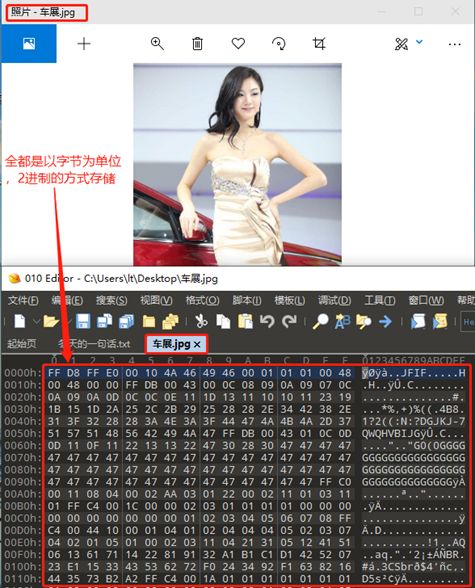
所有的文件,不管是文本文件还是二进制文件,在计算机中都是以字节为单位,2进制的形式进行存储。任何一个文件,查看大小属性时,都会显示这个文件占用多少个字节。
示例1,文本文件的内部存储,如下图所示:

示例2,二进制文件的内部存储,如下图所示:
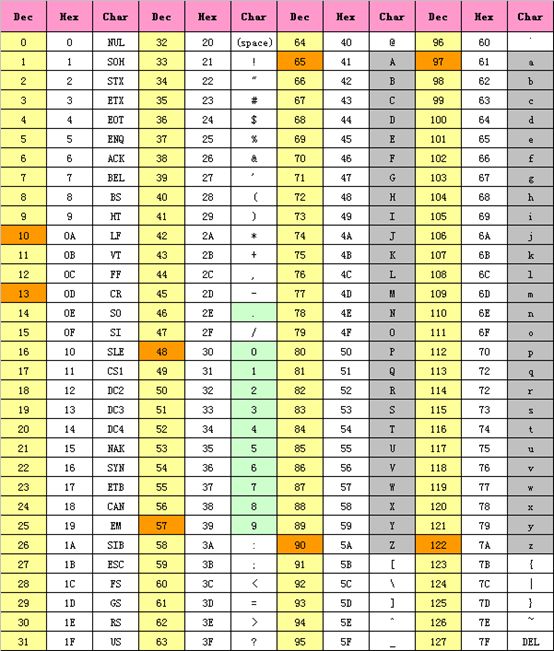
ASCII(American Standard Code for InformationInterchange,美国信息交换标准代码)是基于拉丁字母的一套字符编码系统,主要用于显示现代英语和其他西欧语言。它等同于国际标准 ISO/IEC 646。ASCII编码第一次以规范标准的形式发表是在1967年,最后一次更新是在1986年,到目前为止共定义了 128 个字符,分别用0到127的整数值对应,在计算机中用一个字节就可以存储。
标准ASCII编码,使用7 位二进制数(剩下的1位二进制为0)来表示所有的大写和小写字母,数字0 到9、标点符号,以及在美式英语中使用的特殊控制字符。其中,33个是控制字符或通信专用字符(无法显示的字符),其余95个可显示字符。
具体的ASCII 编码对照关系如下图所示:
前面曾说过,不管是文本文件还是二进制文件,都是以二进制形式存储的。文本文件和二进制文件,只是逻辑上的划分,2者的区别主要体现在数据的编码和解码上。
在讲解打开文件的open函数时,有一个encoding参数,这个参数指定编码方式,默认为utf-8,还可以指定为gb2312等等。这个参数只对文本文件有效,如果是操作二进制文件时,不需要指定这个参数,这个参数对二进制文件没有用。
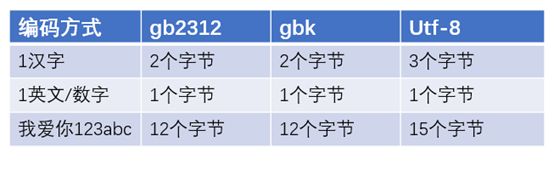
对于文本文件来说,读/写的都是以字符为单位,但存储的是二进制的字节。当进行写入的时候,要进行编码,把一个字符转换为1个或多个字节。进行读取的时候,要进行解码,需要把文件中存储的1个或多个字节转换为对应的字符。那么问题来了,1个字符转换为几个字节?几个字节转换为1个字符?这是由encoding这个参数决定的,这个参数指定的编码,规定了如何进行字符和字节之间的相互转换。不同的编码,这种转换规则是不一样的。所以,对于读取和写入操作,在打开文件时,要保持编码相同。建议使用utf-8编码,有时候还会遇到gbk编码(gb2312的超集),gb2312编码(有些汉字没被包含进去,所以就不能用gb2312,只能用gbk或utf-8)。下面列举了这3种编码下的汉字/英文/数字字符占用字节情况:

对于二进制文件来说,读/写的都是以字节(byte)为单位,在文件中存储的也是二进制的字节。传入的是字节流,文件中存储的也是字节流,读取的也是字节流,不做任何转换,都是以字节为单位。所以,不需要指定编码。
04 bytes1. 定义
bytes是python3新增加的类型,用于表示一连串的字节,以字节为单位。它和字符串非常类似,只不过字符串是以字符为单位。除了数据单元不一样外,所支持的函数都一样(但含义略有不同),比如len,find,index,切片操作,使用索引进行随机访问等等。此外,都是不可变序列。
表现形式上,bytes数据是以b开头加一对单引号,字节数据放在单引号内。
# 空的bytes数据b''# ASCII字符直接加前缀bb'python'b'https://www.baidu.com'# 一连串的字节数据+ASCII字符b'\xe6\x88\x91\xe7\x88\xb1\xe4\xbd\xa0123abc'因此,bytes是由0个或多个字节(byte)组成的不可变序列。简单点说,bytes就是由字母b开头的⼀对单引号' 括起来的一串字节。
2. 生成bytes数据
1) 如果字符串的所有字符都是ASCII字符,直接添加b前缀。
这是因为每个ASCII字符都是1个字节就能表示。
# 空的bytes数据b''# ASCII字符直接加前缀bb'python'b'https://www.baidu.com'2) 字符串转bytes
如果字符串里面包含了汉字等字符,就需要进行编码转换,因为不同的编码,每个汉字至少占用2个字节的存储空间。
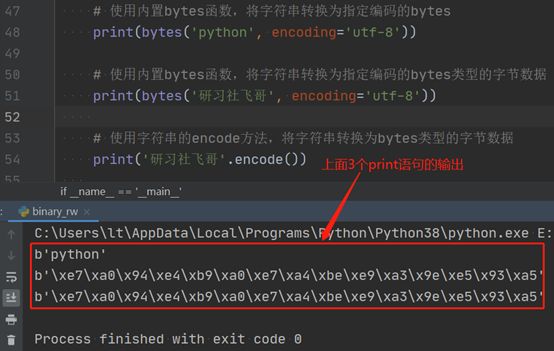
# 使用内置bytes函数,将字符串转换为指定编码的bytesprint(bytes('python', encoding='utf-8'))# 使用内置bytes函数,将字符串转换为指定编码的bytes类型的字节数据print(bytes('研习社飞哥', encoding='utf-8'))# 使用字符串的encode方法,将字符串转换为bytes类型的字节数据print('研习社飞哥'.encode())--------------代码输出如下-----------------
使用bytes类的decode() 方法,可以将 bytes类型的字节数据转换为字符串。如下所示:
# bytes类型的字节数据转换为字符串str1 = b'\xe7\xa0\x94\xe4\xb9\xa0\xe7\xa4\xbe\xe9\xa3\x9e\xe5\x93\xa5'.decode(encoding='utf-8')print(str1) # 输出:研习社飞哥还可以使用str(bytes, 编码)函数,将 bytes类型的字节数据转换为字符串。如下所示:
str1 = str(b'\xe7\xa0\x94\xe4\xb9\xa0\xe7\xa4\xbe\xe9\xa3\x9e\xe5\x93\xa5','utf-8')print(str1) # 输出:研习社飞哥3) int转bytes
num = 168'''整数转换为bytes length: --指定整数的字节长度,如果整数值超过字节长度能表示的最大整数值,则会报错。 byteorder: --指定数据在内存中的大小端存储,一般使用little就可以了。 signed: --指定整数有符号还是无符号整数,如果是无符号则整数值不能是负数。'''data = num.to_bytes(length=2, byteorder='little', signed=True)print(data, len(data)) #输出:b'\xa8\x00' 2# bytes转换为整数num = int.from_bytes(data, byteorder='little', signed=True)print(num) # 输出:1684) bytes(iterable_of_ints) -> bytes
参数iterable_of_ints表示可迭代的int对象。函数把每个int对象转换为一个字节,然后按顺序拼在一起,生成一个bytes对象。
注意:由于每个字节范围只能是0x00到0xFF,所以iterable_of_ints中的每个整数值,只能在0到255范围。
>>> bytes([0x61,0x62]) #每一个可显示为ASCII字符的,在bytes中直接显示字符b'ab'>>> bytes([49,50,51])b'123'>>> bytes([21,22,255]) #不能显示为ASCII字符的,以\x开头显示16进制值b'\x15\x16\xff'>>> bytes([21,22,50]) #第2个整数不能显示为ASCII字符,所以显示\x16,第3个整数表示数字2,所以直接显示2b'\x15\x162'>>> bytes([0x15,0x16,50])b'\x15\x162'>>> 5) bytes.fromhex (string) -> bytes
参数string是一个特殊的字符串,字符串的每1字符将被视为一个16进制的字符,每2个字符组成一个\x开头的16进制表示的字节,最后把这些字节拼接在一起,形成一个bytes对象。参数string的每个字符只能是0到9以及a到f范围的任一个字符。
>>> bytes.fromhex('e4bda0') #每2个字符转为一个字节b'\xe4\xbd\xa0'>>> bytes.fromhex('e4 bda0') #空格会被作为字节之间的分割b'\xe4\xbd\xa0'>>> bytes.fromhex('e 4 bda0') #被空格分割的字符必须是成对出现,因为每个字节由2个16进制的字符组成Traceback (most recent call last): File "", line 1, in bytes.fromhex('e 4 bda0')ValueError: non-hexadecimal number found in fromhex() arg at position 1>>> >>> bytes.fromhex('313233') #每一个可显示为ASCII字符的,在bytes中直接显示字符b'123' 还可以将bytes转为十六进制的字符串,也就是上面过程的逆过程:
>>> b'\xe4\xbd\xa0'.hex() # 每一个字节转为2个16进制的字符'e4bda0'>>> b'123'.hex()'313233'>>> b'\x15\x162'.hex()'151632'>>> 6) struct模块
到目前为止,字符串、整数,都可以和bytes相互转换,但是另外2种数字类型float,bool还没办法相互转换。这时候,struct模块就能派上用场了。
struct模块有2个函数,可以实现各种数据类型和bytes之间的相互转换:
pack(fmt, *args)
按照给定的转换格式(fmt),把数据转换为bytes类型的字节数据。
unpack(fmt, bytes)
按照给定的格式(fmt)解析bytes类型的字节数据,将解析后的数据以元组的形式返回。
示例代码如下:
num = 168# 整数转换为bytes# 第1个参数(转换格式)指定byteorder=little,要转换的数据是2字节的有符号整数# 第2个参数要转换的整数值data1 = struct.pack('print(data1) # 输出:b'\xa8\x00'# bytes转换为整数,# 第1参数要和编码时的转换格式一致# 第2个参数bytes数据num = struct.unpack('print(num) # 输出:(168,)num2 = 168.888# 浮点数转换为bytesdata2 = struct.pack('print(data2) # 输出:b'#\xdb\xf9~j\x1ce@'# bytes转换为浮点数num2 = struct.unpack('print(num2) # 输出:(168.888,)# 可以一次性将多个整数转换为bytes# 此时每个数据的格式都要在第一个参数中指定data3 = struct.pack('print(data3) # 输出:b'2\x00d\x00d\x00'# bytes中包含的多个整数解析出来num = struct.unpack('print(num) # 输出:(50, 100, 100)转换格式字符串中的有效格式如下图所示:

转换格式字符串中的字节顺序(byteorder)的可以为下图第一列中的字符之一,如下图所示:

3. 其它操作
# 3个字节的bytes对象>>> b = b'\x15\x162'# 索引访问,索引处的字节转为对应的十进制整数>>> b[1] 22>>> type(b[1])# 切片访问,返回的还是切片>>> b[:2] b'\x15\x16'# 通过bytes对象生成另一个bytes对象>>> b2 = bytes(b) >>> b2b'\x15\x162'>>> id(b) # 变量b和b2指向同一个bytes对象2032332404560>>> id(b2)2032332404560# bytes对象赋值>>> b3 = b >>> b3b'\x15\x162'>>> id(b3) # 赋值后,变量b和b3也是指向同一个bytes对象2032332404560>>> id(b)2032332404560>>> b3 is bTrue>>> b2 is bTrue# bytes数据的查找操作>>> b.find(b'2') 2>>> bytearray是一个可变的字节数组,可以添加,修改,删除字节元素。bytearray的大部分方法和bytes的方法一样,如索引、切片、find、fromhex、hex等等。
1. 生成bytearray对象
# 生成空的字节数组>>> bytearray()bytearray(b'')# 生成指定字节元素个数的字节数组# 每个元素值为0x00>>> bytearray(5)bytearray(b'\x00\x00\x00\x00\x00')# 通过bytes对象生成bytearray对象>>> bytearray(b'123456')bytearray(b'123456')#通过字符串和指定字符编码生成bytearray对象>>> bytearray('研习社飞哥', 'utf-8')bytearray(b'\xe7\xa0\x94\xe4\xb9\xa0\xe7\xa4\xbe\xe9\xa3\x9e\xe5\x93\xa5')>>> # 通过可迭代int对象生成bytearray对象# 用法和限制和bytes的一样>>> bytearray([0x31, 0x32, 0x33])bytearray(b'123')>>> byte_ar1 = bytearray([49, 50, 51])>>> byte_ar1bytearray(b'123')# bytearray对象转为列表>>> [i for i in byte_ar1][49, 50, 51]>>> # bytearray的fromhex方法、hex方法# 用法和限制和bytes的一样>>> bytearray.fromhex('e4bda0')bytearray(b'\xe4\xbd\xa0')>>> bytearray.fromhex('313233')bytearray(b'123')>>> bytearray(b'123').hex()'313233'>>> bytearray(b'\xe4\xbd\xa0').hex()'e4bda0'>>> 2. 修改bytearray对象
# 创建空的字节数组>>> b1 = bytearray()>>> b1bytearray(b'')# 添加一个字节元素>>> b1.append(49)>>> b1bytearray(b'1')# 将bytes对象或者bytearray对象的所有字节元素添加到字节数组(b1)的末尾>>> b1.extend(b'456')>>> b1bytearray(b'1456')# 删除字节数组的末尾元素>>> b1.pop()54>>> b1bytearray(b'145')# 查找字节数据>>> b1.find(b'5')2# 反转字节数组的所有元素>>> b1.reverse()>>> b1bytearray(b'541')# 修改字节数组的元素>>> b1[0]=97>>> b1bytearray(b'a41')>>># 清空字节数组>>> b1.clear()>>> b1bytearray(b'')>>> 好了,今天的内容就分享到这里了,小伙伴可以动手多练练,这些知识很容易就掌握了。如有不清楚的或疑问,可以私信飞哥交流。
Python新手入门、进阶问题,欢迎私信交流,看到就回复。
END 专业提供 定制学习计划和职业规划服务 公众号:Python编程研习社
专业提供 定制学习计划和职业规划服务 公众号:Python编程研习社