java string获取某个位置的字符_你,确定了解Java的String字符串?
文章来源:https://mp.weixin.qq.com/s/avonh1I4KP_LUOvFbRU2rA
作者:阿飞的博客
本文将描述JDK6中String.intern()是如何实现的,以及在JDK7和JDK8中对字符串池化技术做了哪些改变。
String池化介绍
String池化就是把一些值相同,但是标识符不同的字符串用一个共享的String对象来表示,而不是用多个String对象。举个栗子,如下代码所示,3个变量的值完全一样,那么通过String池化处理,3个变量a,b,c事实上指向同一个String对象:

要达到这个目的,你可以自己借助Map实现,这就是传说中的重复造轮子。当然,最优雅的方式还是利用JDK提供的String.intern()方法。
在JDK6的时候,很多标准规范禁止使用String.intern(),因为如果池化控制不好的话,非常可能碰到OOM。因此,JDK7做了相当大的改变,更多细节可以参考下面给到的两个链接地址:
http://bugs.sun.com/viewbug.do?bugid=6962931
http://bugs.sun.com/viewbug.do?bugid=6962930
JDK6中的String.intern()
JDK6时代,所有通过String.intern()处理过的字符串都被保存在PermGen中,是Java堆的一个固定大小部分,主要用来存储已经加载的类信息和字符串常量池。除了显示调用String.intern()的字符串,PermGen的字符串常量池也包含了程序中所有使用过的字符串(如果一个类或者方法从来没有被加载,或者被调用,那就不是使用过的)。
JDK6中字符串常量池这样的实现最大的问题的就是它保存的地方--PermGen。PermGen的大小是固定的,不能在运行时扩容,用户可以通过JVM参数-XX:MaxPermSize=N设定PermGen的大小。这样的限制导致我们在使用String.intern()时需要非常小心,如果你想在JDK6中使用String.intern(),那么你最好不要使用在不能被控制的的地方(例如池化用户名,这绝对是灾难)。
JDK7中的String.intern()
Oracle工程师在JDK7中对字符串常量池逻辑做了非常重要的改变 -- 将字符串常量池重新移到了堆中,它不再是一块分离的固定大小的内存区域。所有字符串都被移到堆中,和其他大多数对象一样。如此一来,当你调优应用时只需要管理堆尺寸大小。如果是基于JDK7的应用,那么,这绝对是一个充分的理由让你重新考虑使用String.intern(),当然也有一些其他的理由。
池化的值能被GC
是的,JVM字符串常量池中所有的字符串都能被垃圾回收掉,前提条件是那些不再被GC Roots引用的字符串 -- 这个结论适用于我们正在讨论的JDK6,7,8三个版本。这就意味着,如果你通过String.intern()池化的字符串超过了范围,并且不再被引用,那么它们是可以被GC掉的。
字符串常量池中的字符串能够被GC,也能保留在Java堆中。这样看来,对所有字符串来说,字符串常量池似乎是一个很合适的地方,理论上是这样的 -- 没有使用的字符串会在常量池中被GC掉,使用的字符串允许你保存在内存中,这样当然取等值的字符串时就能直接从常量池中取出来。听起来似乎是一个完美的保存策略,但是在下结论之前,你需要先了解字符串常量池实现的细节。
JDK6/7/8中字符串常量池的实现
字符串常量池被实现为一个固定容量大小的HashTable,每个桶(bucket)包含所有hashcode值相同的字符串组成的List链表。默认池大小是1009,JDK6早期版本是固定常量池,JDK6u30~6u41是可以配置的,JDK7从7u02开始也是支持配置的,通过JVM参数-XX:StringTableSize=N即可指定。需要提醒的是,为了更好的性能和散列性,建议N为一个质数(prime number,例如13,17,1009这样的数)。
JDK6中StringTableSize这个参数帮助价值不大,因为还是受到PermGen固定大小的限制。所以,接下来的讨论将抛弃JDK6。
另外,需要注意的是,字符串常量池这个HashTable,当存放的数据足够多需要rehash时,其rehash的行为和Java中使用的HashMap有所不同。字符串常量池底层的HashTable在rehash时不会扩容,即rehash前后bucket数量是一样的。它的rehash过程只是通过一个新的seed重新计算一遍来尝试摊平每个bucket中LinkedList的长度(不保证rehash后的性能有很大的提升)。
Java7 (until Java7u40)
需要说明的是,这个段落只表示JDK7u40之前的JDK7版本。
JDK7中,一方面你将受到更大堆内存的限制,意味着你能设置一个更大的字符串常量池(具体多大取决于你应用需求)。通常来说,当内存数据尺寸增长几百M后,我们才会开始关心内存消耗,在这种场景下,为常量池分配8~16M用来保存百万级个entry似乎是一个很合理的权衡(注意:不要设置-XX:StringTableSize的值为1000000,而应该设置为100003,因为1000000不是质数)。
如果你真的想要使用String.intern(),强烈建议将-XX:StringTableSize设置一个比默认值1009更大的值。否则,这个方法的性能很快就会退化到取决于双向链表长度。
以下是使用默认池大小的部分应用测试日志:在已经缓存了一些字符串时存入10000个字符串花费的时间,这1w个字符串通过Integer.toString(i)生成,其中i在[0, 1000000)之间:

这个测试结果基于Core [email protected] CPU。正如你看到的结果,耗时线性增长,当JVM常量池已经有1百万个字符串时,接下来每秒钟只能池化大概5000个字符串,这时候性能衰退还是很严重的。但是,当我们设置-XX:StringTableSize=100003后,再次进行测试,结果如下。正如你看到的,这种情况下,池化字符串的耗时比较稳定(每个bucket平均有10个字符串):

接下来,我们依然设置-XX:StringTableSize=100003,但是准备池化1千万个字符串,这就意味着平均每个bucket中大概有100个字符串:

接下来,我们设置-XX:StringTableSize=10000003,并插入1千万个字符串继续进行测试。结果如下,正如你看到的,耗时是水平的而不是线性增长。由此可见,只要常量池大小足够大,即使是我这种个人电脑也能轻轻松松达到每秒百万级的插入量。

还需要重复造轮子嘛?
现在,我们比较一下JVM自带的字符串常量池和WeakHashMap
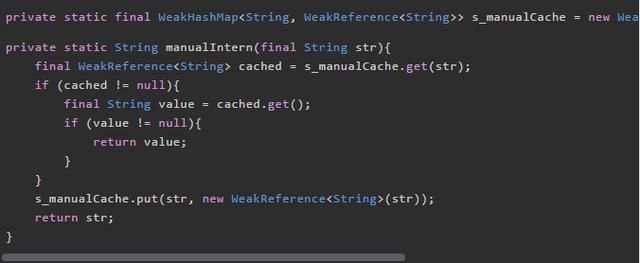
利用WeakHashMap造出的轮子测试性能如下:
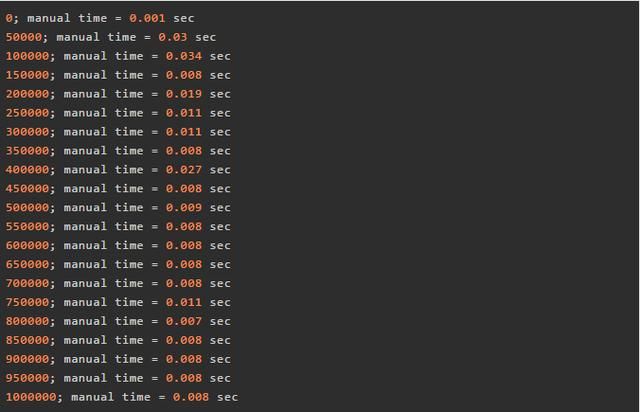
当JVM内存充足时,利用WeakHashMap造的轮子和JVM内置常量池性能相当。但是,在我缓存短字符串进行字符串缓存测试时,Xmx1280M的设置只能缓存约2.5M的strings,但是JVM常量池在保证相同性能的情况下可以缓存约12.72M的strings(5倍多)。因此我认为,我们最好在程序中避免自己实现字符串常量池。
7u40+和8中的String.intern()
7u40以后的版本字符串常量池大小被增大到60013(60013也是质数)。默认值改为60013可以让你保存大概30000个不同的字符串到常量池中而不会发生任何Hash碰撞。通常来说,这个值完全足够你保存那些真正需要池化的字符串。这个默认值你可以通过如下命令进行查看,通过结果我们可知,JDK8默认值就是60013:
afei$ java -XX:+PrintFlagsFinal -version | grep StringTableSize uintx StringTableSize = 60013 {product} java version "1.8.0201" Java(TM) SE Runtime Environment (build 1.8.0201-b09) Java HotSpot(TM) 64-Bit Server VM (build 25.201-b09, mixed mode) 接下来我尝试在JDK8环境上运行相同的测试用例,Java8依旧支持-XX:StringTableSize参数且提供了与Java7同样的性能表现。只是唯一的不同在于默认池大小增长为60013了:

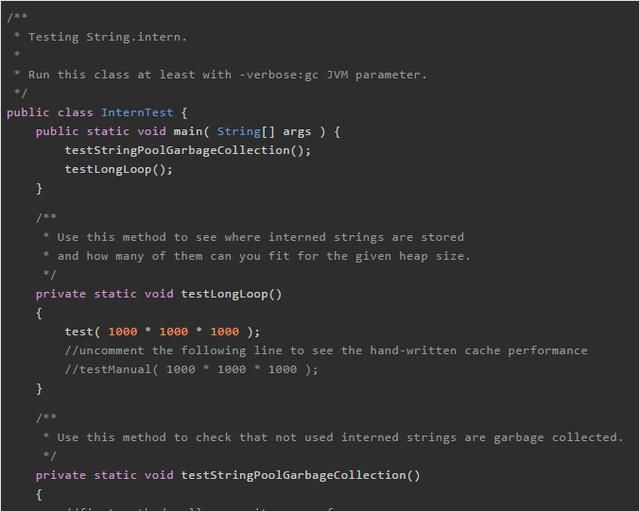
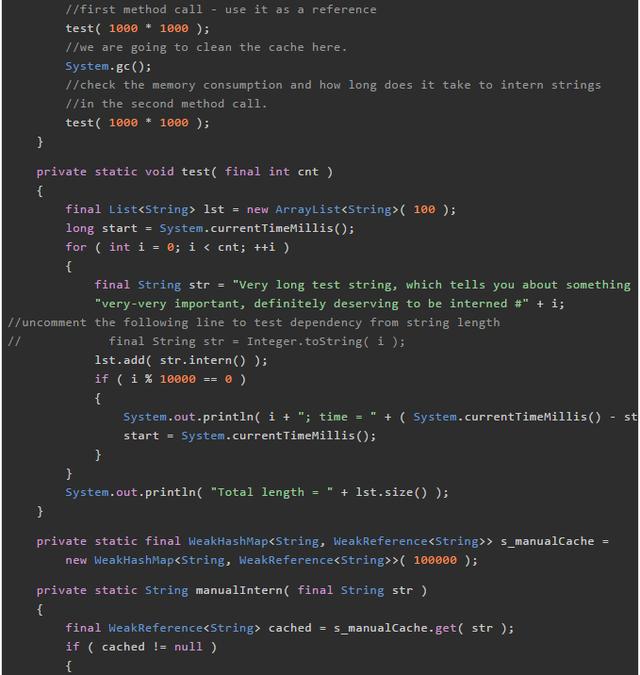
测试代码
这篇文章中使用的测试代码非常简单:在循环中不断生成和池化新的strings。我们同时计算了它池化当前10000个字符串的耗时。运行此程序时,强烈建议用-verbose:gc这个虚拟机参数,以便当发生GC时,能在控制台实时输出GC日志。你也可以使用-Xmx参数来指定最大堆空间。
这里有2个测试:testStringPoolGarbageCollection 测试将会证明JVM字符串常量池真的可以被垃圾回收 —— 查看垃圾回收日志并在随后查看缓存字符串的耗时。这个测试在Java6中默认的永久代区大小中会失败。因此要么更新大小,要么更新测试方法参数,要么使用Java7。 第二个测试将会向你展示内存中可以缓存多少字符串。请在Java6中通过两个不同的内存设定运行此测试。例如-Xmx128M和-Xmx1280M(后者是前者的10倍)。你会发现这并不会影响可在池中缓存字符串的数目,因为那块保存池化的字符串空间大小是固定的。而在Java7中,你却可以用你的字符串填满整个堆。
总结
接下来对String.intern()进行一个总结,希望对你有用:
- JDK6由于保存字符串常量池的是一块固定大小的内存区域(PermGem),所以不建议使用String.intern()。
- JDk7和8实在堆内存中实现的字符串常量池,这就意味者字符串常量池的限制和整个Java应用的内存一样大。
- JDK7和8中可以通过参数-XX:StringTableSize设定字符串常量池大小,估算一下你应用中需要池化的不同字符串的数量,建议将常量池的大小设置为这个数量的2倍的一个质数(避免可能的碰撞,假设我们需要池化5000个字符串,那么10000往后最近的质数是10007,即设定-XX:StringTableSize=10007)。这会让String.intern运行在一个常数时间内(性能很高),并且每个缓存字符串所需内存会很小(在同任务量下,显式使用Java WeakHashMap会产生4-5倍多的内存开销)。.
- JDK6到JDK7u40之间XX:StringTableSize默认值是1009,7u40以后,包括JDK8,这个默认值被提升到60013。
- 如果你不太确定你应用需要多大的字符串常量池,可以通过JVM参数-XX:+PrintStringTableStatistics,在JVM退出时可以看到字符串常量池的使用情况,从而更合理的调整StringTableSize的值。
我目前是在职Java开发,如果你现在正在了解Java技术,想要学好Java,渴望成为一名Java开发工程师,在入门学习Java的过程当中缺乏基础的入门视频教程,你可以关注并私信我:01。我这里有一套最新的Java基础JavaSE的精讲视频教程,这套视频教程是我在年初的时候,根据市场技术栈需求录制的,非常的系统完整。