Java开发Spark程序
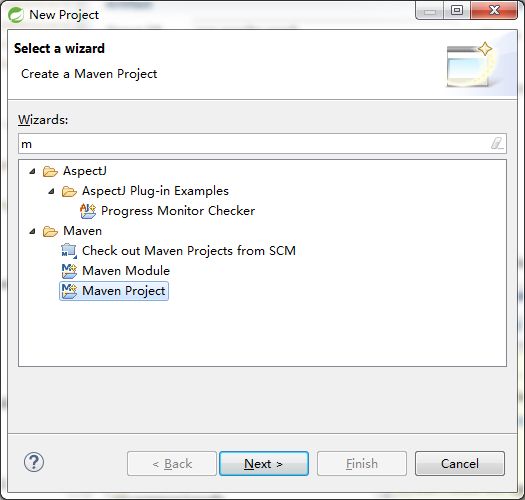

pom.xml
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0modelVersion>
<groupId>com.dt.sparkgroupId>
<artifactId>SparkAppsartifactId>
<version>0.0.1-SNAPSHOTversion>
<packaging>jarpackaging>
<name>SparkAppsname>
<url>http://maven.apache.orgurl>
<properties>
<project.build.sourceEncoding>UTF-8project.build.sourceEncoding>
properties>
<dependencies>
<dependency>
<groupId>junitgroupId>
<artifactId>junitartifactId>
<version>3.8.1version>
<scope>testscope>
dependency>
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-core_2.10artifactId>
<version>1.6.0version>
dependency>
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-sql_2.10artifactId>
<version>1.6.0version>
dependency>
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-hive_2.10artifactId>
<version>1.6.0version>
dependency>
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-streaming_2.10artifactId>
<version>1.6.0version>
dependency>
<dependency>
<groupId>org.apache.hadoopgroupId>
<artifactId>hadoop-clientartifactId>
<version>2.6.0version>
dependency>
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-streaming-kafka_2.10artifactId>
<version>1.6.0version>
dependency>
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-graphx_2.10artifactId>
<version>1.6.0version>
dependency>
dependencies>
<build>
<sourceDirectory>src/main/javasourceDirectory>
<testSourceDirectory>src/main/testtestSourceDirectory>
<plugins>
<plugin>
<artifactId>maven-assembly-pluginartifactId>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependenciesdescriptorRef>
descriptorRefs>
<archive>
<manifest>
<mainClass>mainClass>
manifest>
archive>
configuration>
<executions>
<execution>
<id>make-assemblyid>
<phase>packagephase>
<goals>
<goal>singlegoal>
goals>
execution>
executions>
plugin>
<plugin>
<groupId>org.codehaus.mojogroupId>
<artifactId>exec-maven-pluginartifactId>
<version>1.2.1version>
<executions>
<execution>
<goals>
<goal>execgoal>
goals>
execution>
executions>
<configuration>
<executable>javaexecutable>
<includeProjectDependencies>trueincludeProjectDependencies>
<includePluginDependencies>falseincludePluginDependencies>
<classpathScope>compileclasspathScope>
<mainClass>com.dt.spark.AppmainClass>
configuration>
plugin>
<plugin>
<groupId>org.apache.maven.pluginsgroupId>
<artifactId>maven-compiler-pluginartifactId>
<configuration>
<source>1.6source>
<target>1.6target>
configuration>
plugin>
plugins>
build>
project>
本地模式
/**
* 文件名:WordCount.java
*
* 创建人:Sundujing - [email protected]
*
* 创建时间:2016年5月9日 上午9:53:28
*
* 版权所有:Sundujing
*/
package com.dt.spark.SparkApps.cores;
import java.util.Arrays;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.FlatMapFunction;
import org.apache.spark.api.java.function.Function2;
import org.apache.spark.api.java.function.PairFunction;
import org.apache.spark.api.java.function.VoidFunction;
import scala.Tuple2;
/**
* [描述信息:说明类的基本功能]
*
* @author Sundujing - [email protected]
* @version 1.0 Created on 2016年5月9日 上午9:53:28
*/
public class WordCount {
public static void main(String[] args)
{
/**
* 第一步,创建Spark的配置对象SparkConf,设置Spark程序的运行时的配置信息,
* 例如说通过setMaster来设置程序要链接的Spark集群的Master的URL,
* 如果设置为local,则代表Spark程序在本地运行,特别适合于机器配置较差的情况
*/
SparkConf conf=new SparkConf().setAppName("Spark workcount written by Java").setMaster("local");
/**
* 第二步,创建SparkContext对象
* SparkContext是Spark程序所有功能的唯一入口,无论是采用Scala,java,python,R等都
* 必须有一个SparkContext(不同语言具体类名称不同,如果是Java的话,则为JavaSparkContext)
* 同时还会负责Spark程序在Master注册程序等
* SparkContext是整个Spark应用程序至关重要的一个对象
*/
JavaSparkContext sc =new JavaSparkContext(conf);//其底层实际上是Scala的SparkContext
/**
* 第三步,根据具体的数据来源(HDFS,HBase,Local,FS,DB,S3等),通过JavaSparkContext来创建JavaRDD
* JavaRDD的创建方式有三种:根据外部数据来源(例如HDFS),
* 根据Scala集合,由其他的RDD操作数据会将RDD划分成一系列Partition,
* 分配到每个Partition的数据属于一个Task处理范畴
*/
JavaRDD lines = sc.textFile("D://spark-1.6.1-bin-hadoop2.6//README.md");
JavaRDD words = lines.flatMap(new FlatMapFunction() {
//如果是Scala,由于SAM转化,所以可以写成val words=lines.flatMap{line =>line.split(" ")}
public Iterable call(String line) throws Exception {
return Arrays.asList(line.split(" "));
}
});
/**
* 第4步:对初始的JavaRDD进行Transformation级别的处理,例如map,filter等高阶函数等的编程,来进行具体的数据计算
* 第4.1步:在单词拆分的基础上对每个单词实例进行计数为1,也就是word =>(word,1)
*/
JavaPairRDD pairs=words.mapToPair(new PairFunction()
{
public Tuple2 call(String word) throws Exception{
return new Tuple2(word,1);
}
});
/**
* 统计总次数
*/
JavaPairRDD wordCount=pairs.reduceByKey(new Function2()
{
public Integer call(Integer v1,Integer v2)throws Exception
{
return v1+v2;
}
});
wordCount.foreach(new VoidFunction>(){
public void call(Tuple2 pairs) throws Exception {
System.out.println(pairs._1()+":"+pairs._2());
}
});
sc.close();
}
}
运行结果:

集群模式
代码如下:
/**
* 文件名:WordCount_Cluster.java
*
* 创建人:Sundujing - [email protected]
*
* 创建时间:2016年5月9日 下午12:40:24
*
* 版权所有:Sundujing
*/
package com.dt.spark.SparkApps.cores;
/**
* [描述信息:说明类的基本功能]
*
* @author Sundujing - [email protected]
* @version 1.0 Created on 2016年5月9日 下午12:40:24
*/
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.FlatMapFunction;
import org.apache.spark.api.java.function.Function2;
import org.apache.spark.api.java.function.PairFunction;
import org.apache.spark.api.java.function.VoidFunction;
import scala.Tuple2;
import java.util.Arrays;
import java.util.List;
public class WordCount_Cluster {
public static void main(String[] args)
{
SparkConf conf = new SparkConf();
//SparkConf conf = new SparkConf().setMaster("spark://yarn-client:7077").setAppName("WordCount by java");
//SparkConf conf = new SparkConf().setMaster("spark://172.171.51.131:7077").setAppName("WordCount by java");
//SparkConf conf = new SparkConf().set("spark.driver.host", "node1") .set("spark.driver.port", "60959").setAppName("WordCount by java");
JavaSparkContext sc = new JavaSparkContext(conf);
JavaRDD lines = sc.textFile("hdfs://node1:8020/tmp/harryport.txt");
//JavaRDD lines = sc.textFile("D://spark-1.6.1-bin-hadoop2.6//README.md");
JavaRDD words = lines.flatMap(new FlatMapFunction() {
public Iterable call(String line) throws Exception {
return Arrays.asList(line.split(" "));
}
});
JavaPairRDD paris = words.mapToPair(new PairFunction() {
public Tuple2 call(String word) throws Exception {
return new Tuple2(word, 1);
}
});
JavaPairRDD wordCount = paris.reduceByKey(new Function2() {
public Integer call(Integer v1, Integer v2) throws Exception {
return v1 + v2;
}
});
List> list = wordCount.collect();
for(Tuple2 pari :list)
{
System.out.println(pari._1() + ":" + pari._2());
}
sc.close();
}
} 读取hdfs://node1:8020/tmp/harryport.txt中的内容,并分词统计
1.打包
Export-》jar file
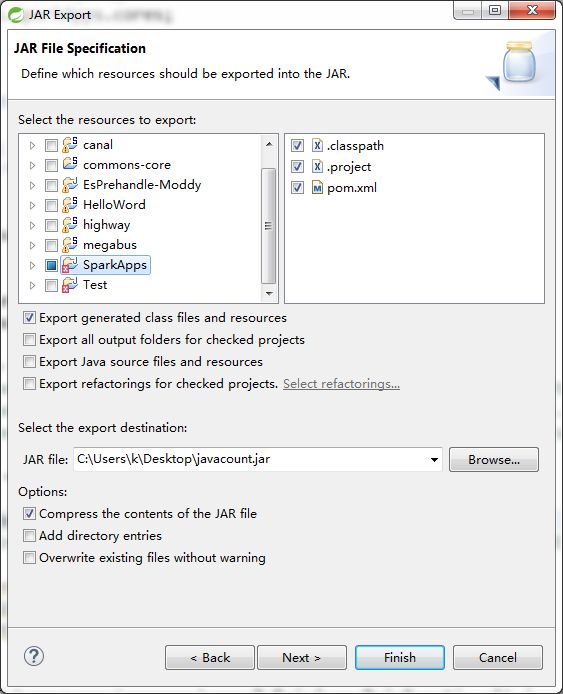
jar名javacount.jar
2.写运行脚本javacount.sh
./spark-submit --class com.dt.spark.SparkApps.cores.WordCount_Cluster /root/javacount.jar3.传入集群

4.进入spark/bin目录下
![]()
5.执行脚本
sh /root/javacount.sh6.运行结果
