python bytes转int_Python 内置函数总结(1/4)
小编这个周末双休,当然是先熬夜玩耍 - 瘫了12小时,然后开始更新,还算敬业?

今天我们开始来总结一下python的内置函数,问我为什么写,是渐渐觉得很多东西可以直接调用,不需要引入package,那给我的感觉是:内置的应该是要掌握的基础,会有很强大的功能建立在你掌握了基础之上。
主题:今天涉及的主要是计算机编码转换涉及的函数,跳着来是为了把能比较的放一起
优势: 每一个function 除了解释, 例子, 还有有些话题的衍生梳理!
/目录/
abs() & all() & any() (顺着附带前三个function)
bit, byte, 字符, 编码方式, 二进制概念梳理
ascii() & repr(), ord() & chr()
bin() & int()
bool()
bytearray() & bytes()
leetcode 用bytearray来解决问题
字符类型和进制转换梳理
![]()
tips: 进入今天话题之前,先把一个小总结放上,也可以混乱的时候回放一下
bit: 位,计算机数据储存最小单位;二进制里的0或1就是一个位
byte: 一个字节 = 8 位即8个二进制位
字符: 字母,汉字,符号等都是字符,
计算机有不同的编码方式,不同编码方式下,字符的占用字节也不一样
ASCII中,一个英文占1字节,一个汉字占2字节
UTF-8中,一个英文占1字节,一个中文占3字节
unicode中,一个英文占2字节,一个中文占2字节
编码:对字符串按不同编码encode成字节序列bytes
解码:对字节序列bytes按不同解码decode成字符串
为什么要编码转变呢? 因为计算机是处理数字的思路来运行的,如果要是处理文本,我们通常会要把文本转换成数字,然后再处理,这自然就有了文本和数字的对应编码。(计算机内部都是一个二进制的值,比如A对应的是数字65,在计算机内部对应的二进制是01000001)
![]()
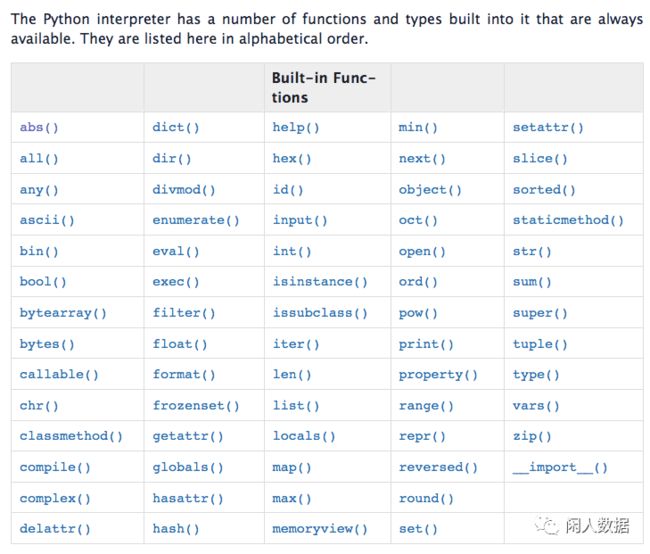
上图 - 内置函数
![]()
咱先把前三个function顺一下
abs() : 返回绝对值
abs(-1)想到了math里的求绝对值:fabs
import math math.fabs(-1)All() & Any():
All
Return True: 所有的元素都是true, 或者empty
Return False: 只要有一个元素是false
Any
Retrun True: 有一个元素是true
Return False:全是false
def all(iterable): for element in iterable: if not element: return False return True def any(iterable): for element in iterable: if element: return True return False all([1,2,3])all([1,0,3]) all([1,False,3])all([1,'',3]) all([])Return: True, False, False,False,True
所以这个传入的iterable一定是可循环?
yes,什么类型可循环呢?想到了常见的 list, tuple, dict, etc.哈哈感觉是另一个话题了
应用一下?
比如查一个数据集里是否有null value?
data = pd.read_csv('xxxxxxx.csv') data.isnull().any() data.isnull().all()当你笔试总是碰到矩阵题处理的时候? 经常要用np.any 和 np.all?比如查看某一个矩阵的前5行是否有0,用any 操作一下?
df = np.arange(24).reshape(4,2,3) # 创建矩阵if np.any(df[:5,:]==0): print('yes')
Return :Yes
![]()
编码问答
ASCII是编码形式,为了方便理解,我们先回答问题。
ASCII对应的是什么呢?
ASCII 编码美国制定的字符编码,对应了英语字符和二进制(0,1)之间的关系,ASCII一共规定了128字符的编码。
见过乱码问题?
当然,比如,你用ascii格式去识别其他编码的文件。
只有ASCII么?
当然不是,128字符编码英语够用,那别的语言呢,再想想汉字,这就要说到我们常见的unicode,小编觉得uni有一点universe或者unique的感觉哈哈,理解为一统天下哈哈,它为每种语言中的每个字符设定了统一并且唯一的二进制编码。它的优缺点可以自己查找哈。还有utf-8, utf-16, etc.
通俗的来说,就是这些编码都有自己的方式去转换。
![]()
ascii() & repr() , ord() & chr()
ascii() 返回表示对象的字符串,如果非ASCII编码里就用\x,\u或\U等字符来表示
repr() 返回表示对象的字符串,repr并不会对非ASCII编码用以上的方式表示
ord() 返回字符的编码表示 - 传入长度为1的string
chr() 返回编码对应的字符 即 chr() ord () 反着来
试一试
我们试一下货币符号$,€(感觉欧元不在ASCII英语的编码里),所以非编码产生了\u字符



![]()
bin() & int()
小编不是刚刚说计算机都是二进制的方式么?那我们怎么获取,转变呢?
bin() - 传入参数int,返回二进制字符串,binary
int() - 第一位传入参数字符串,第二位传入进制转化方式

咋有个0b?当然0b后面才是二进制的编码哦,如果要是我不想用编码转化成原本的数字时,加上0b呢?我能直接输入二进制数字进行转换么,能,看看int()

哈哈不要忘了,我们原本是用10进制表示的哦
![]()
bool()
联想一下好像是boolean - T or F
常见会被判定为F 的情形: None,False,0,empty,
应用:某一个数值有没有被输入?
我第二个没有输入数字,那bool(y.strip()) 返回了False
![]()
bytearray() & bytes()
bytearray是可变的字节序列,称做字节数组
bytes是不可变的字节序列 (混乱就返回刚开始的总结tips哦)
操作一下:创建字节和字节数组
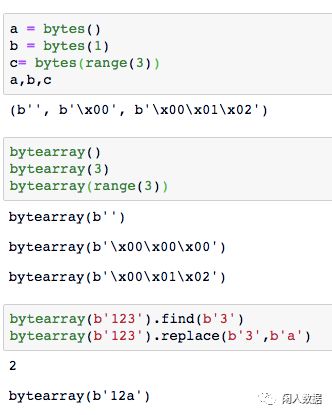
ps: find 功能是找到对应的索引,replace是替换,看下面题解锁
![]()
byte 解锁 Leetcode 题
我们用bytearray来解锁一个leetcode 里的题
Max Consecutive Ones:
Given a binary array, find the maximum number of consecutive 1s in this array. Input:
[1,1,0,1,1,1] Output: 3 翻译过来是在一个二进制的数组里,找最大的连续1?
联想一下: 二进制?01在字节中表示不一样?或许可以字节的表示用来截断?

oh 神奇
![]()
转化类型总结
类型转换
int(x) 转换成一个整数,long(x)转换成一个长整数,float(x) 转换成浮点,str(x)变成字符串,repr(x) 转换成表达字符串,tuple(x) 转换成元组,list(x) 转成列表,chr(x) 整数转成字符,ord(x)字符变成对应整数。
进制转换
bin(x) 转换成2进制
oct(x) 转换成8进制
int(x,base=10) 转换成10进制
hex(x)转换成16进制
说白了,我们就是得让计算知道我们传入了什么,出于不同考虑,他有不同的编码方式,这些函数功能帮助你类型转化,进制转化,也有对应的函数给你转回来/
别走开,之后我们继续内置函数玩耍
大家晚安
END
