python 读取excel表数据_5分钟学会用Python 读取Excel
5分钟学会用Python
读取Excel
日常办公使用频率最高的软件非Excel莫属了,如果我们遇到需要导入别人的Excel进行后续数据分析、读取内容等操作,我们该怎么办呢?
测试开发哥哥说:莫要慌,人生苦短,我用Python!
本文目录
--环境配置
--主要使用方法
--打开文件
--获取sheet表
--获取行列数
--获取单元格值
--遍历表格
--读取指定行、指定列
--样例
--原始需求
--打开并获取sheet表
--读取表头
--读取内容
![]()
![]()
Python的基础环境配置相信大家都很熟悉了,此处不再赘述,如需详细文档,可以善用搜索引擎。
Python读取Excel的外部库的方法参考上次的文章(5分钟学习用Python写测试报告—openpyxl应用),本次继续使用好用的openpyxl库进行Excel的读取
安装很简单,直接用pip命令即可安装成功:
pip install openpyxl

.py文件中导入openpyxl即可使用
import openpyxl或者from openpyxl import Workbook
![]()
![]()
1.打开文件
from openpyxl import load_workbook
excel=load_workbook('/test.xlsx')
2.获取sheet表
获得每一个子表的名称
excel.sheetnames
通过表名获取当前表对象,方便后续进行遍历操作
table = excel.get_sheet_by_name('Sheet1')
3.获取行数和列数:
rows=table.max_row #获取行数
cols=table.max_column #获取列数
4.获取单元格值:
值得说明的是,openpyxl的行列数是按照Excel中的行列数从1开始的,而不是一般程序从0开始,此处使用的时候需要特别注意。
Data=table.cell(row=row,column=col).value
#第一行第一列从1开始的获取表格内容
5.遍历表格
遍历从某行到某列的方法是使用iter_rows('开始:结束') ,此处的入参和Excel保持一致,如:从A1单元格到D4单元格为 A1:D4
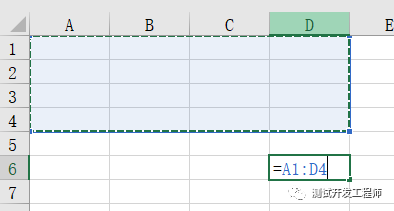
遍历的内容使用value方法获得
取值时要用value,例如:
for row in ws.iter_rows('A1:D4'):
for cell in row:
print(cell.value)
6.读指定行、指定列:
row=ws.rows
返回值row是可迭代的,是当前表格所有的行
columns=ws.columns
返回值column是可迭代的,是当前表格所有的列
打印第n行数据
print(rows[n])
![]()
![]()
1.原始需求
假设我们有如下表格,第2行为表头,获取当前表头和表格的所有的内容,返回结果和list形式

2.打开并获取sheet表
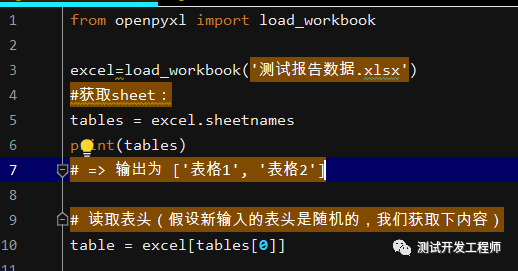
获取表格1sheet对象
table = excel[tables[0]]
3.读取表头

逻辑为:
1.首先获得总列数
table.max_colum
2.然后遍历第二行每一列
for i in range(1, columns + 1)
+1是因为openpyxl是从1开始计数,python的range为左闭右开区间
TIPS:
因为在计算机硬件中迭代器对比较大小的运算很麻烦,有些时候两个地址都无法比较大小。但是比较是否相等就会简单的多,比如我要 range(5) 这时候只需判断从0开始每次加一,直到等于5的时候结束循环。
3.拿到单元格的值,存储到数组中。
row_data.append(cell_value)
4.拿到每一个表头的具体index
# 以下基于我们已知表头内容,但不知道位于第几个结果_index = row_data.index('结果')
测试项_index = row_data.index('测试项')
备注_index = row_data.index('备注')
4.读取全部内容
有了上面的学习,读取全部内容就轻而易举了
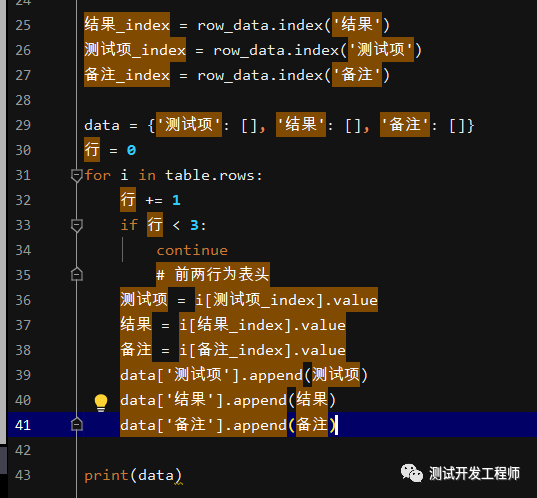
输出为:
{'测试项': ['通过率', '识别率', '召回率'], '结果': [0.9, 0.68, 0.78], '备注': ['通过', '识别', '召']}

相信聪明的读者看到这里,已经知道如何使用openpyxl进行表格的读取了,如果有更多的使用,可以参考openpyxl的官方文档:
https://openpyxl.readthedocs.io/en/stable/

作
业
万万没想到我看个公众号还有作业??

没关系,这里只是介绍下应用场景:
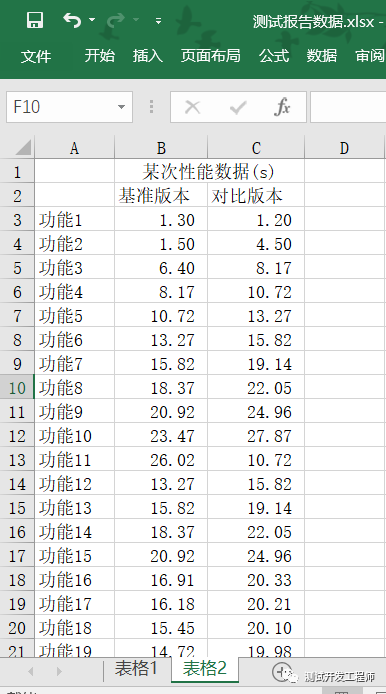
如下面的表格是某次性能测试的数据,请快速用python存入数据库并计算差异大于10%且大于4秒的数据,想必聪明的你这5分钟已经学会了。