python 利用百度AI实现文字识别(cv2 + aip module)
python 利用百度AI实现文字识别(cv2 + aip module)
(该案例将利用cv2,aip等模块,详细的安装以及使用的方法将在后文进行简单的介绍。)
一、KNN算法的简介(机器学习算法之一)
通俗的含义:近朱者赤,近墨者黑
核心的思想:如果一个样本在特征空间中的K个最相邻的样本中的大多数属于某一个类别,则该样本也属于这个类别,并具有这个类别上样本的特性。
应用举例:通过AI识别手写的数字(文字的识别也是类似的):
1、通过拍照得到手写内容;
2、识别图片后与原来已经录入的图形形状进行对比;
3、与哪一个数字的图形的形状最接近,则返回那个数字。
优点:
1、理论比较成熟;
2、容易理解, 简单而好用.
缺点:
1、可能会存在一定的错误;
2、计算复杂性较高,空间复杂性较高;
3、存在样本的不平衡问题.
二、百度AI平台简单介绍即使用方法
(1)简单介绍
百度公司开发的人工智能开放平台,目前已经在各方面有所突破,并且有较为广泛的应用。
具体的链接如下所示:(百度AI 开放平台的链接)
https://ai.baidu.com/
(2)使用方法
1、首先登录平台
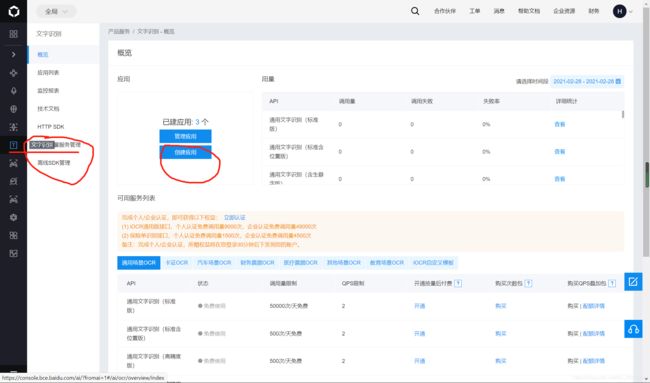
2、然后创建自己的应用
(此处勾选所需要的功能即可,另外该平台可以选择免费的使用。)
(文字识别是系统勾选好的,如果想要其他功能可以自行勾选。)
3、重要信息
在百度AI平台中的设备主要有三个重要的信息:
1、AppID;
2、API Key;
3、Secret Key。
(这三个信息在写程序时会用到,即利用这三个信息调用相应的设备。)

三、安装所需要的python库
(我已经安装好了,所以下图会显示:Requirement already satisfied)
1、使用cv2, 需要安装opencv-python
命令:pip install opencv-python
![]()
2、使用aip, 需要安装baidu-aip
命令:pip install baidu-aip

四、代码实现(有详细注释的解释)
需要输入你自己的设备的appid, apikey, secretkey。
(此处定义函数是为了使功能的实现分成不同的区域块,从而便于理解,当然不定义函数也是可以实现相应的功能的。)
# using the baidu aip and python to identify the characters
# 文字识别
# import
import cv2
from aip import AipOcr
# 导入 cv2 和 aip 中的 AipOcr
# define config
"""
输入你自己的设备的appId, apiKey, secretKey。
"""
config = \
{
# 字典
'appId': '********', # appId
'apiKey': '************************', # apiKey
'secretKey': '*********************************' # secretKey
} # 字典的形式
# 构造调用百度aip的请求头
# 类似于headers
client = AipOcr(**config)
# 利用config来进行访问以及调用相应的设备
# 定义获取图像的函数
def get_file_content(file):
"""
获取图像
:param file: 文件的名称
:return: 返回读取的内容
"""
with open(file, 'rb') as f:
# 获取保存下来的图像
# 采用读和写的模式('rb')
# return f.read()
return f.read()
# 读取图像中的文字信息并识别文字
def img_to_string(image_path):
"""
识别图像中的文字
:param image_path: 文件的名称
:return: 返回识别的结果(识别所得到的文字)
"""
image_0 = get_file_content(image_path)
# 调用上一个函数来得到图像
# 调用get_file_content(file)来得到图像
# 获得读取的结果
result_0 = client.handwriting(image_0)
# result_1 = client.basicGeneral(image_0)
# 识别手写字用 ; result_0 = client.handwriting(image_0)
# 识别印刷文字要用 ;result_1 = client.basicGeneral(image_0)
# 此处以手写为例 !!
# print(result_0)
# 返回识别的结果
if 'words_result' in result_0:
return '\n'.join([w['words'] for w in result_0['words_result']])
if __name__ == '__main__':
"""
main函数实现功能
"""
# 创建窗口
cv2.namedWindow('Camera', 1)
# Camera-->命名窗口
# 调用系统自带的摄像头
# 这是电脑自带的摄像头,当然也可以用代理IP摄像头
capture = cv2.VideoCapture(0)
while True: # 循环执行
# 获取信息
success, image = capture.read()
cv2.imshow('Camera', image)
# 设置按键
# 要让摄像头等待按键,而不是直接拍照 !!
key = cv2.waitKey(10)
# 根据按键来处理获取的图片以及操控程序
if key == 27:
# Esc 按键
break
else:
if key == 32:
# 空格按键
filename = 'picture.jpg'
# 将所获取的图像保存至文件中
cv2.imwrite(filename=filename, img=image)
# 调用函数实现文字识别的功能
s = img_to_string(filename)
# 打印信息
print(s)
五、运行结果展示
运行上述代码后的结果展示:(手写文字+程序打印内容)


六、内容总结
总之,该程序实现了调用百度人工智能平台中的文字识别功能,来进行识别手写或机器打印的文字(英语,汉语都可以哦),具体思路在这里进行一下总结:
1、首先拍摄照片;
2、构造请求头向百度AI平台中的设备发送请求以及请求的内容(图片);
3、获取得到请求的结果;
4、显示请求得到的结果。
另外,百度AI平台实际上采用的是机器的深度学习算法,这种算法由于KNN算法,精确度更高,识别结果更可信。
七、P.S.(改良后的代码)
在上述的基础之上,可以将代码进行一定的优化与改良,具体的改良版本如下所示,这就简洁了不少(此处不再写注释,具体的改良方法可以自己总结来实现):
(这里的改良代码仅供参考啦~~)
# 改良了的版本,这里省去了一些不必要的函数,使代码变得更加简洁
import cv2
from aip import AipOcr
if __name__ == '__main__':
config = {
'appId': '********', # appId
'apiKey': '************************', # apiKey
'secretKey': '*********************************' # secretKey
}
client = AipOcr(**config)
cv2.namedWindow('Word recognition has been improved', 1)
capture = cv2.VideoCapture(0)
# 电脑自带的摄像头,也可以用代理IP摄像头
while True:
success, image = capture.read()
cv2.imshow('Word recognition has been improved', image)
key = cv2.waitKey(10)
if key == 27: # 当然用其他的按键来控制也是可以的啊
break
elif key == 32: # 当然用其他的按键来控制也是可以的啊
filename = 'A_image_of_test.jpg'
cv2.imwrite(filename=filename, img=image)
with open(filename, 'rb') as a_file:
result = client.handwriting(a_file.read())
if 'words_result' in result:
print('\n'.join(w['words'] for w in result['words_result']))