本文来自网易云社区
作者:汪建伟
前言
前一段时间参与哨兵流式监控功能设计,调研了两个可以做流式计算的框架:storm和spark streaming,我负责storm的调研工作。断断续续花了一周的时间看了官网上的doc和网络上的一些资料。我把所学到的总结成一个文档,发出来给对storm感兴趣的同事做入门引导。
storm背景
随着互联网的更进一步发展,从Portal信息浏览型到Search信息搜索型到SNS关系交互传递型,以及电子商务、互联网旅游生活产品等将生活中的流通环节在线化。对效率的要求让大家对于实时性的要求进一步提升,而信息的交互和沟通正在从点对点往信息链甚至信息网的方向发展,这样必然带来数据在各个维度的交叉关联,数据爆炸已不可避免。因此流式处理加NoSQL产品应运而生,分别解决实时框架和数据大规模存储计算的问题。
2011年twitter对Storm开源。以前互联网的开发人员在做一个实时应用的时候,除了要关注应用逻辑计算处理本身,还要为了数据的实时流转、交互、分布大伤脑筋。现在开发人员可以快速的搭建一套健壮、易用的实时流处理框架,配合SQL产品或者NoSQL产品或者MapReduce计算平台,就可以低成本的做出很多以前很难想象的实时产品:比如一淘数据部的量子恒道品牌旗下的多个产品就是构建在实时流处理平台上的。
strom语言
Storm的主要开发语言是clojure,完成核心功能逻辑,辅助开发语言还有Python和java
strom的特点
1. 编程模型简单
Storm同hadoop一样,为大数据的实时计算提供了一些简单优美的原语,这大大降低了开发并行实时处理的任务的复杂性,帮助你快速、高效的开发应用。
2. 可扩展
在Storm集群中真正运行topology的主要有三个实体:工作进程、线程和任务。Storm集群中的每台机器上都可以运行多个工作进程,每个工作进程又可创建多个线程,每个线程可以执行多个任务,任务是真正进行数据处理的实体,我们开发的spout、bolt就是作为一个或者多个任务的方式执行的。 因此,计算任务在多个线程、进程和服务器之间并行进行,支持灵活的水平扩展。
3. 高可靠
Storm可以保证spout发出的每条消息都能被“完全处理”。 spout发出的消息后续可能会触发产生成千上万条消息,可以形象的理解为一棵消息树,其中spout发出的消息为树根,Storm会跟踪这棵消息树的处理情况,只有当这棵消息树中的所有消息都被处理了,Storm才会认为spout发出的这个消息已经被“完全处理”。如果这棵消息树中的任何一个消息处理失败了,或者整棵消息树在限定的时间内没有“完全处理”,那么spout发出的消息就会重发。 考虑到尽可能减少对内存的消耗,Storm并不会跟踪消息树中的每个消息,而是采用了一些特殊的策略,它把消息树当作一个整体来跟踪,对消息树中所有消息的唯一id进行异或计算,通过是否为零来判定spout发出的消息是否被“完全处理”,这极大的节约了内存和简化了判定逻辑,后面会在下文对这种机制进行详细介绍。
这种模式,每发送一个消息,都会同步发送一个ack/fail,对于网络的带宽会有一定的消耗,如果对于可靠性要求不高,可通过使用不同的emit接口关闭该模式。
上面所说的,Storm保证了每个消息至少被处理一次,但是对于有些计算场合,会严格要求每个消息只被处理一次,Storm的0.7.0引入了事务性拓扑,解决了这个问题。
4. 高容错
如果在消息处理过程中出了一些异常,Storm会重新安排这个出问题的处理单元。Storm保证一个处理单元永远运行(除非你显式杀掉这个处理单元)。当然,如果处理单元中存储了中间状态,那么当处理单元重新被Storm启动的时候,需要应用自己处理中间状态的恢复。
5. 快速
这里的快主要是指的时延。storm的网络直传、内存计算,其时延必然比hadoop的通过hdfs传输低得多;当计算模型比较适合流式时,storm的流式处理,省去了批处理的收集数据的时间;因为storm是服务型的作业,也省去了作业调度的时延。所以从时延上来看,storm要快于hadoop。
说一个典型的场景,几千个日志生产方产生日志文件,需要进行一些ETL操作存入一个数据库。
假设利用hadoop,则需要先存入hdfs,按每一分钟切一个文件的粒度来算(这个粒度已经极端的细了,再小的话hdfs上会一堆小文件),hadoop开始计算时,1分钟已经过去了,然后再开始调度任务又花了一分钟,然后作业运行起来,假设机器特别多,几钞钟就算完了,然后写数据库假设也花了很少的时间,这样,从数据产生到最后可以使用已经过去了至少两分多钟。
而流式计算则是数据产生时,则有一个程序去一直监控日志的产生,产生一行就通过一个传输系统发给流式计算系统,然后流式计算系统直接处理,处理完之后直接写入数据库,每条数据从产生到写入数据库,在资源充足时可以在毫秒级别完成。
6. 支持多种编程语言
除了用java实现spout和bolt,你还可以使用任何你熟悉的编程语言来完成这项工作,这一切得益于Storm所谓的多语言协议。多语言协议是Storm内部的一种特殊协议,允许spout或者bolt使用标准输入和标准输出来进行消息传递,传递的消息为单行文本或者是json编码的多行。
7. 支持本地模式
Storm有一种“本地模式”,也就是在进程中模拟一个Storm集群的所有功能,以本地模式运行topology跟在集群上运行topology类似,这对于我们开发和测试来说非常有用。
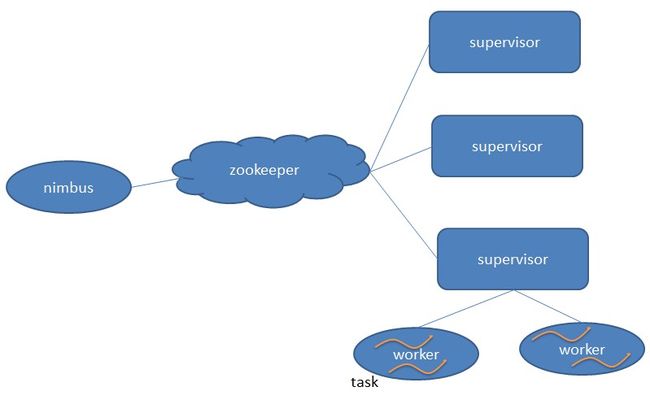
storm的组成
在Storm的集群里面有两种节点: 控制节点(master node)和工作节点(worker node)。控制节点上面运行一个叫Nimbus后台程序,它的作用类似Hadoop里面的JobTracker。Nimbus负责在集群里面分发代码,分配计算任务给机器, 并且监控状态。
每一个工作节点上面运行一个叫做Supervisor的节点。Supervisor会监听分配给它那台机器的工作,根据需要启动/关闭工作进程。每一个工作进程执行一个topology的一个子集;一个运行的topology由运行在很多机器上的很多工作进程组成。
Nimbus和Supervisor之间的所有协调工作都是通过Zookeeper集群完成。另外,Nimbus进程和Supervisor进程都是快速失败(fail-fast)和无状态的。所有的状态要么在zookeeper里面, 要么在本地磁盘上。这也就意味着你可以用kill -9来杀死Nimbus和Supervisor进程, 然后再重启它们,就好像什么都没有发生过。这个设计使得Storm异常的稳定。
接下来我们再来具体看一下这些概念。
Nimbus:负责资源分配和任务调度。
Supervisor:负责接受nimbus分配的任务,启动和停止属于自己管理的worker进程。
Worker:运行具体处理组件逻辑的进程。
Task:worker中每一个spout/bolt的线程称为一个task. 在storm0.8之后,task不再与物理线程对应,同一个spout/bolt的task可能会共享一个物理线程,该线程称为executor。
下面这个图描述了以上几个角色之间的关系。
Topology基本原理
Storm集群和Hadoop集群表面上看很类似。但是Hadoop上运行的是MapReduce jobs,而在Storm上运行的是拓扑(topology),这两者之间是非常不一样的。一个关键的区别是: 一个MapReduce job最终会结束, 而一个topology永远会运行(除非你手动kill掉)。
1 拓扑(Topologies)
一个topology是spouts和bolts组成的图, 通过stream groupings将图中的spouts和bolts连接起来,如下图:

一个topology会一直运行直到你手动kill掉,Storm自动重新分配执行失败的任务, 并且Storm可以保证你不会有数据丢失(如果开启了高可靠性的话)。如果一些机器意外停机它上面的所有任务会被转移到其他机器上。
2 流(Streams)
数据流(Streams)是 Storm 中最核心的抽象概念。一个数据流指的是在分布式环境中并行创建、处理的一组元组(tuple)的无界序列。数据流可以由一种能够表述数据流中元组的域(fields)的模式来定义。在默认情况下,元组(tuple)包含有整型(Integer)数字、长整型(Long)数字、短整型(Short)数字、字节(Byte)、双精度浮点数(Double)、单精度浮点数(Float)、布尔值以及字节数组等基本类型对象。当然,你也可以通过定义可序列化的对象来实现自定义的元组类型。
3 数据源(Spouts)
数据源(Spout)是拓扑中数据流的来源。一般 Spout 会从一个外部的数据源读取元组然后将他们发送到拓扑中。根据需求的不同,Spout 既可以定义为可靠的数据源,也可以定义为不可靠的数据源。一个可靠的 Spout 能够在它发送的元组处理失败时重新发送该元组,以确保所有的元组都能得到正确的处理;相对应的,不可靠的 Spout 就不会在元组发送之后对元组进行任何其他的处理。
一个 Spout 可以发送多个数据流。为了实现这个功能,可以先通过 OutputFieldsDeclarer 的 declareStream 方法来声明定义不同的数据流,然后在发送数据时在 SpoutOutputCollector 的 emit 方法中将数据流 id 作为参数来实现数据发送的功能。
Spout 中的关键方法是 nextTuple。顾名思义,nextTuple 要么会向拓扑中发送一个新的元组,要么会在没有可发送的元组时直接返回。需要特别注意的是,由于 Storm 是在同一个线程中调用所有的 Spout 方法,nextTuple 不能被 Spout 的任何其他功能方法所阻塞,否则会直接导致数据流的中断。
Spout 中另外两个关键方法是 ack 和 fail,他们分别用于在 Storm 检测到一个发送过的元组已经被成功处理或处理失败后的进一步处理。注意,ack 和 fail 方法仅仅对上述“可靠的” Spout 有效。
4 数据流处理组件(Bolts)
拓扑中所有的数据处理均是由 Bolt 完成的。通过数据过滤(filtering)、函数处理(functions)、聚合(aggregations)、联结(joins)、数据库交互等功能,Bolt 几乎能够完成任何一种数据处理需求
一个 Bolt 可以实现简单的数据流转换,而更复杂的数据流变换通常需要使用多个 Bolt 并通过多个步骤完成。例如,将一个微博数据流转换成一个趋势图像的数据流至少包含两个步骤:其中一个 Bolt 用于对每个图片的微博转发进行滚动计数,另一个或多个 Bolt 将数据流输出为“转发最多的图片”结果(相对于使用2个Bolt,如果使用3个 Bolt 你可以让这种转换具有更好的可扩展性)。
与 Spout 相同,Bolt 也可以输出多个数据流。为了实现这个功能,可以先通过 OutputFieldsDeclarer 的 declareStream 方法来声明定义不同的数据流,然后在发送数据时在 OutputCollector 的 emit 方法中将数据流 id 作为参数来实现数据发送的功能。
在定义 Bolt 的输入数据流时,你需要从其他的 Storm 组件中订阅指定的数据流。如果你需要从其他所有的组件中订阅数据流,你就必须要在定义 Bolt 时分别注册每一个组件。对于声明为默认 id(即上文中提到的“default”——译者注)的数据流,InputDeclarer支持订阅此类数据流的语法糖。也就是说,如果需要订阅来自组件“1”的数据流,declarer.shuffleGrouping("1") 与 declarer.shuffleGrouping("1", DEFAULT_STREAM_ID) 两种声明方式是等价的。
Bolt 的关键方法是 execute 方法。execute 方法负责接收一个元组作为输入,并且使用 OutputCollector 对象发送新的元组。如果有消息可靠性保障的需求,Bolt 必须为它所处理的每个元组调用 OutputCollector 的 ack 方法,以便 Storm 能够了解元组是否处理完成(并且最终决定是否可以响应最初的 Spout 输出元组树)。一般情况下,对于每个输入元组,在处理之后可以根据需要选择不发送还是发送多个新元组,然后再响应(ack)输入元组。IBasicBolt 接口能够实现元组的自动应答。
5 数据流分组(Stream groupings)
为拓扑中的每个 Bolt 的确定输入数据流是定义一个拓扑的重要环节。数据流分组定义了在 Bolt 的不同任务(tasks)中划分数据流的方式。
在 Storm 中有八种内置的数据流分组方式,而且你还可以通过CustomStreamGrouping 接口实现自定义的数据流分组模型。这八种分组分时分别为:
1. 随机分组(Shuffle grouping):这种方式下元组会被尽可能随机地分配到 Bolt 的不同任务(tasks)中,使得每个任务所处理元组数量能够能够保持基本一致,以确保集群的负载均衡。
2. 域分组(Fields grouping):这种方式下数据流根据定义的“域”来进行分组。例如,如果某个数据流是基于一个名为“user-id”的域进行分组的,那么所有包含相同的“user-id”的元组都会被分配到同一个任务中,这样就可以确保消息处理的一致性。
3. 部分关键字分组(Partial Key grouping):这种方式与域分组很相似,根据定义的域来对数据流进行分组,不同的是,这种方式会考虑下游 Bolt 数据处理的均衡性问题,在输入数据源关键字不平衡时会有更好的性能1。感兴趣的读者可以参考这篇论文,其中详细解释了这种分组方式的工作原理以及它的优点。
4. 完全分组(All grouping):这种方式下数据流会被同时发送到 Bolt 的所有任务中(也就是说同一个元组会被复制多份然后被所有的任务处理),使用这种分组方式要特别小心。
5. 全局分组(Global grouping):这种方式下所有的数据流都会被发送到 Bolt 的同一个任务中,也就是 id 最小的那个任务。
6. 非分组(None grouping):使用这种方式说明你不关心数据流如何分组。目前这种方式的结果与随机分组完全等效,不过未来 Storm 社区可能会考虑通过非分组方式来让 Bolt 和它所订阅的 Spout 或 Bolt 在同一个线程中执行。
7. 直接分组(Direct grouping):这是一种特殊的分组方式。使用这种方式意味着元组的发送者可以指定下游的哪个任务可以接收这个元组。只有在数据流被声明为直接数据流时才能够使用直接分组方式。使用直接数据流发送元组需要使用 OutputCollector 的其中一个 emitDirect 方法。Bolt 可以通过 TopologyContext 来获取它的下游消费者的任务 id,也可以通过跟踪 OutputCollector 的 emit 方法(该方法会返回它所发送元组的目标任务的 id)的数据来获取任务 id。
8. 本地或随机分组(Local or shuffle grouping):如果在源组件的 worker 进程里目标 Bolt 有一个或更多的任务线程,元组会被随机分配到那些同进程的任务中。换句话说,这与随机分组的方式具有相似的效果。
6 任务(Tasks)
在 Storm 集群中每个 Spout 和 Bolt 都由若干个任务(tasks)来执行。每个任务都与一个执行线程相对应。数据流分组可以决定如何由一组任务向另一组任务发送元组。你可以在 TopologyBuilder 的 setSpout 方法和 setBolt 方法中设置 Spout/Bolt 的并行度。
7 工作进程(Workers)
拓扑是在一个或多个工作进程(worker processes)中运行的。每个工作进程都是一个实际的 JVM 进程,并且执行拓扑的一个子集。例如,如果拓扑的并行度定义为300,工作进程数定义为50,那么每个工作进程就会执行6个任务(进程内部的线程)。Storm 会在所有的 worker 中分散任务,以便实现集群的负载均衡。
相关阅读: 流式处理框架storm浅析(下篇)
网易云免费体验馆,0成本体验20+款云产品!
更多网易研发、产品、运营经验分享请访问网易云社区。
相关文章:
【推荐】 全局脚手架了解一下【fle-cli】