神经网络压缩基础系列之量化(聚类量化)
目录
1、神经网络量化
2、聚类量化
2.1、KMeans
2.2、可量化卷积和可量化全连接层
2.3、构建网络
3、训练
4、结果
1、神经网络量化
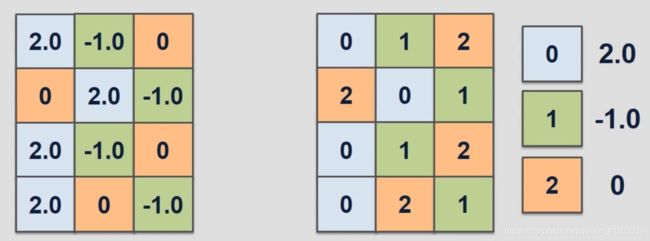
神经网络量化是深度学习模型的压缩方法之一,目的是在尽量保证原模型特性和精度同时加速网络推理速度,减少模型存储大小和便于部署在边缘计算设备。狭义上的量化是将连续的信号离散化,深度神经网络模型的量化是权重由float32量化为int8、int4等,减少模型的可表示空间大小。如下图所示,将左图用右图的方式进行表示。基础的量化方法可分为聚类量化和线形量化。
2、聚类量化
2.1、KMeans
聚类量化是利用K-means方法得到权重的聚类中心和标签。同时根据聚类中心和标签又可以回推到weight,当然过程中有损失。K-means方法的有效性最重要的就是K值,也就是聚类中心个数的选择至关重要。
#Author: Chao
import torch
from sklearn.cluster import KMeans
import pdb
def cluster_weight_cpu(weight,
cluster_K,
init_method="k-means++",
max_iter=30):
'''
Args:
wieght: Tensor
cluster_K: The number of cluster center
init_method: use in KMeans init, default k-means++
max_iter: use in KMeans to limit max iteration
Return:
cluster center values
cluster labels
'''
ori_shape = weight.shape
weight = weight.view(-1, 1)
kmeans = KMeans(n_clusters=cluster_K, init=init_method, max_iter=max_iter)
kmeans.fit(weight)
cluster_centers = kmeans.cluster_centers_
labels = kmeans.labels_
labels = labels.reshape(ori_shape)
return torch.as_tensor(cluster_centers).view(-1, 1), torch.as_tensor(labels, dtype=torch.int8)
def reconstruct_weight_from_cluster_result(cluster_centers, labels):
'''
Args:
cluster_centers: cluster_centers from KMeans cluster
labels: labels from KMeans cluster
Return:
reconstruct_weight
'''
weight = torch.zeros_like(labels).float()
for i, c in enumerate(cluster_centers):
weight[labels==i] = c.item()
return weight
if __name__ == "__main__":
test_weight = torch.randn(3,4)
cluster_centers, labels = cluster_weight_cpu(weight=test_weight, cluster_K=3)
reconstruct_weight = reconstruct_weight_from_cluster_result(cluster_centers, labels)
pdb.set_trace()
#############################################
(Pdb) test_weight
tensor([[ 0.4763, -0.0085, 0.8790, 1.0555],
[ 0.0971, 0.1236, -0.0253, 0.1355],
[ 0.6366, 1.1935, 0.4453, -0.2140]])
(Pdb) cluster_centers
tensor([[0.5194],
[0.0181],
[1.0427]], dtype=torch.float64)
(Pdb) labels
tensor([[0, 1, 2, 2],
[1, 1, 1, 1],
[0, 2, 0, 1]], dtype=torch.int8)
(Pdb) reconstruct_weight
tensor([[0.5194, 0.0181, 1.0427, 1.0427],
[0.0181, 0.0181, 0.0181, 0.0181],
[0.5194, 1.0427, 0.5194, 0.0181]])
#############################################2.2、可量化卷积和可量化全连接层
class QuantLinear(nn.Linear):
'''
Use KMeans cluster to quant Linear layers' weight & bias
'''
def __init__(self, in_features, out_features, bias=True):
super(QuantLinear, self).__init__(in_features=in_features,
out_features=out_features,
bias=bias)
self.quant_weight = False
self.quant_bias = False
self.weight_labels = None
self.weight_center = None
self.bias_labels = None
self.bias_cneter = None
self.num_centers = None
def kmeans_quant(self, quant_bias=False, quant_bit=2):
self.num_centers = 2**quant_bit
self.quant_weight = True
weight = self.weight.data
self.weight_centers, self.weight_labels = cluster_weight_cpu(weight, self.num_centers)
w_q = reconstruct_weight_from_cluster_result(self.weight_centers, self.weight_labels)
self.weight.data = w_q.float()
if quant_bias:
self.quant_bias = True
bias = self.bias.data
self.bias_centers, self.bias_labels = cluster_weight_cpu(bias, self.num_centers)
b_q = reconstruct_weight_from_cluster_result(self.bias_centers, self.bias_labels)
self.bias.data = b_q.float()
class QuantConv2d(nn.Conv2d):
'''
Use KMeans cluster to quant Conv2d layers' weight & bias
'''
def __init__(self, in_channels,
out_channels, kernel_size, stride=1,
padding=1, dilation=1, groups=1, bias=True):
super(QuantConv2d, self).__init__(in_channels=in_channels,
out_channels=out_channels, kernel_size=kernel_size, stride=stride,
padding=padding, dilation=dilation, groups=groups, bias=bias)
self.quant_weight = False
self.quant_bias = False
self.weight_labels = None
self.weight_center = None
self.bias_labels = None
self.bias_cneter = None
self.num_centers = None
def kmeans_quant(self, quant_bias=False, quant_bit=2):
self.num_centers = 2**quant_bit
self.quant_weight = True
weight = self.weight.data
self.weight_centers, self.weight_labels = cluster_weight_cpu(weight, self.num_centers)
w_q = reconstruct_weight_from_cluster_result(self.weight_centers, self.weight_labels)
self.weight.data = w_q.float()
if quant_bias:
self.quant_bias = True
bias = self.bias.data
self.bias_centers, self.bias_labels = cluster_weight_cpu(bias, self.num_centers)
b_q = reconstruct_weight_from_cluster_result(self.bias_centers, self.bias_labels)
self.bias.data = b_q.float()
2.3、构建网络
我使用的是peleenet的mini版本,只到8倍下采样。
3、训练
训练采用mnist数据集
#Author: Chao
import os
import torch
import math
from torch import nn
import torch.nn.functional as F
from torchvision import datasets, transforms
import torch.utils.data
import numpy as np
from copy import deepcopy
from models.peleenet_small import Peleenet32_Small
from configs import cfgs
import pdb
def train(model, device, train_loader, optimizer, epoch):
model.train()
total = 0
for batch_idx, (img, target) in enumerate(train_loader):
img, target = img.to(device), target.to(device)
optimizer.zero_grad()
output = model(img)
loss = F.cross_entropy(output, target)
loss.backward()
optimizer.step()
total += len(img)
print("Epoch:%d "%epoch,"Progress:%d/%d"%(total,len(train_loader.dataset))," Train Loss:%s"%str(round(loss.item(),4)))
def test(model, device, test_loader):
model.eval()
test_loss = 0
correct = 0
with torch.no_grad():
for batch_idx, (img, target) in enumerate(test_loader):
img, target = img.to(device), target.to(device)
output = model(img)
test_loss += F.cross_entropy(output, target, reduction="sum").item()
predict = output.argmax(dim=1, keepdim=True)
correct += predict.eq(target.view_as(predict)).sum().item()
test_loss /= len(test_loader.dataset)
acc = correct/len(test_loader.dataset)
print("Test Loss:%d"%round(test_loss, 4), "Correct:%f"%acc)
return acc
def main():
epochs = cfgs["train"]["epochs"]
train_batch_size = cfgs["train"]["train_batch_size"]
test_batch_size = cfgs["test_batch_size"]
num_classes=cfgs["train"]["num_classes"]
quant_bit = cfgs["quant_bit"]
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
train_loader = torch.utils.data.DataLoader(datasets.MNIST("./data/MNIST",
train=True,
download=True,
transform=transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.1307,),(0.3081,))
])),
batch_size = train_batch_size,
shuffle = True)
test_loader = torch.utils.data.DataLoader(datasets.MNIST("./data/MNIST",
train=False,
download=True,
transform=transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.1307,),(0.3081,))
])),
batch_size = test_batch_size,
shuffle = False)
model = Peleenet32_Small(num_classes=num_classes)
optimizer = torch.optim.Adadelta(model.parameters())
for epoch in range(1, epochs+1):
train(model, device, train_loader, optimizer, epoch)
acc = test(model, device, test_loader)
print("Origin model acc:%f"%acc)
print("*.*"*10)
print("quant %d bit model"%quant_bit)
quant_model = deepcopy(model)
quant_model.use_kmquant(quant_bias=False, quant_bit=quant_bit)
quant_acc = test(quant_model, device, test_loader)
return model, quant_model
if __name__ == "__main__":
os.makedirs("save_models", exist_ok=True)
model, quant_model = main()
state = {'net':model.state_dict()}
quant_state = {'net':quant_model.state_dict()}
torch.save(state,"./save_models/mnist_origin_model.pth")
torch.save(quant_state,"./save_models/mnist_quant_model.pth")这里是训练的配参,聚类中心设为4,也就是4bit量化
#Author: Chao
cfgs = {
"small_peleenet":{
'num_init_features':32,
'growthRate':32,
'nDenseBlocks':[3,3],
'bottleneck_width':[1,2],
},
"train":{
'epochs':2,
'train_batch_size':64,
'num_classes':10,
},
"test_batch_size":256,
'quant_bit': 4,
}4、结果
Origin Model Correct: 0.9877
Quant Model Correct: 0.9871github: https://github.com/2anchao/Model_Squeeze
B站参考: https://www.bilibili.com/video/BV1u7411W7zL
将weight可视化,可见weight已经离散化。
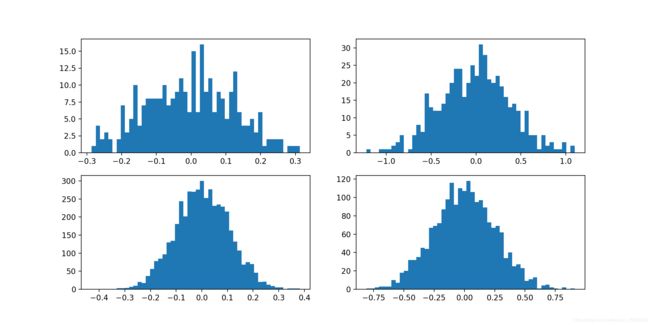 原始模型weights
原始模型weights
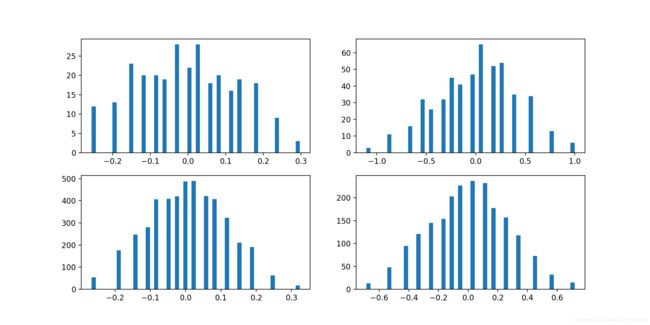 量化模型weights
量化模型weights