本周AI热点回顾:天津大学火速解聘学术不端教授,利用职权为女儿铺路;人脸识别第一案判决...
点击左上方蓝字关注我们

01
机器学习模拟1亿原子:中美团队获2020「超算诺贝尔奖」戈登贝尔奖
有超算界诺贝尔奖美称的「戈登贝尔奖」今年颁给了一个中美合作研究团队,他们的研究被认为是当今计算科学中最令人兴奋领域的重大进展。11 月 19 日,在美国亚特兰大举行的国际超算大会 SC 2020 上,美国计算机协会 ACM 公布了 2020 年戈登贝尔奖(Gordon Bell Prize)的颁奖结果。
来自中国和美国的一个研究小组获此奖项。他们通过机器学习将分子动力学极限从基线提升到了 1 亿原子的惊人数量,同时仍保证了「从头算(ab initio)」的高精度,效率是之前人类基线水平的 1000 倍。在基于物理模型的计算、机器学习和高性能 GPU 并行集群的共同助力下,研究人员已将超大系统的分子动力学模拟带进了一个全新时代。

研究团队在论文中写到:「这项工作的巨大成就在于,它在保持从头算精度的前提下,为分子模拟的空前数量和时间尺度打开了大门,对于更好地集成机器学习和物理建模的下一代超级计算机也提出了新的挑战。」
获奖团队成员包括来自 UC Berkeley 的博士后贾伟乐、副教授林霖,北京应用物理与计算数学研究所计算物理实验室的研究员王涵,北京大学助理教授陈默涵,北京大学研究生路登辉,普林斯顿大学化学系教授 Roberto Car、数学教授鄂维南以及普林斯顿大学数学系和化学系博士张林峰。
分子动力学(MD)是一种计算机模拟方法,可以用来分析原子和分子在一段固定的时间内如何移动与交互。分子动力学模拟可以帮助科学家理解某个系统(从单个细胞到气体云)随时间流逝发生的演变。分子动力学的实际应用包括大分子的研究,如用于药物研发的蛋白质。
在模拟中,从头算分子动力学(Ab initio Molecular Dynamics,AIMD)用不同于标准分子动力学的方法计算原子间的力,其所能达到的精度水平使其成为科学家 35 年来首选的模拟方法。但 AIMD 也有缺点,就是需要的计算量非常高,因此这方面的研究通常局限于小型系统(最多包含几千个原子的系统)。
在今年的戈登贝尔奖获奖论文中,研究团队引入了 Deep Potential 分子动力学(DPMD)。DPMD 是一种基于机器学习的新方法,每天能够模拟 1 亿个原子超过 1 纳秒的轨迹。虽然近年来分子动力学领域涌现了一些其他的基于机器学习的模拟方法,但获奖论文的作者表示,他们的研究首次在保持「从头算」精度的前提下实现了 1 亿个原子的高效分子动力学模拟。
论文链接:https://dl.acm.org/doi/pdf/10.5555/3433701.3433707
具体来说,之前模拟的系统最大包含 100 万个硅原子(速度 = 4X 10^(-3) s/step/atom),模拟速度最快达到 1.3X 10^(-6) s/step/atom (9000 个水原子系统)。而这项研究模拟了 6.79 亿个水分子,1.27 亿个铜原子。速度也比之前最快的模拟提高了几个数量级。

在算法的创新方面,研究团队写道:
为了有效利用 Summit 异构系统架构提供的算力,我们的目标是将几乎所有的计算任务和大量的通信任务迁移到 GPU。由于 DP 模型中计算粒度的大小相对有限,直接的 GPU 实现会遇到很多瓶颈,效率不高。因此,我们做出了以下算法方面的创新:
(1)通过引入一种新的相邻列表数据分布,避免了在计算嵌入矩阵时出现分支,从而增加了 DeePMD 的计算粒度;
(2)相邻列表的新数据结构中的元素被压缩为 64 位整数,以便 GPU 对自定义 TensorFlow 算子进行更高效的优化;
(3)为 DP 模型开发了混合精度计算,计算密集型任务以单精度或半精度执行,而不降低物理观测的精度。
由于戈登贝尔奖表彰在高性能计算方面的成就,决赛选手必须证明他们提出的算法可以在世界上最强大的超级计算机上高效运行。于是,获奖团队开发了一份高度优化的代码(GPU Deep MD-Kit)并在美国能源部橡树岭国家实验室的 Summit 超级计算机上顺利运行,在双精度下实现了 91 PFLOPS 的速度,在混合单 / 半精度下实现了 162/275 PFLOPS 的速度。Summit 超级计算机是 IBM 计划研发的一款超级计算机,目前在全球超级计算机 Top500 新榜单中排名第二。
信息来源:机器之心
02
天津大学火速解聘学术不端教授!退学研究生123页PDF实名举报,控诉利用职权为女儿留学铺路
天津大学这次出手,堪称雷厉风行。11月19日晚,天津大学化工学院官网发表了一则情况说明,对化工学院教授张裕卿被实名举报一事,做出了回应:
已解除聘用。

此时,距离最初举报在网上曝光,仅过去数小时时间。事情的经过是这样的。
一篇长达123页的实名举报信在网上传出,直指天津大学化工学院教授张裕卿学术造假。举报者是张裕卿曾经的学生吕翔——在4年前退学,硕士研究生肄业。信中揭露,2011年到2020年期间,张裕卿有大量论文造假、学术不端行为。
并详细列举了其论文造假、一稿多投的实据。
吕翔自述出身农村,毕业于普通本科院校,辛苦备考一年多后,于2014年被天大化工录取为硕士。那时候的他与众多化工学生一样,怀揣着科研梦想。然而在导师张裕卿的实验室做实验时,吕翔很快发现了不对劲:写期刊小论文时,张裕卿要求他们直接拿上上届的硕士毕业论文来用。在记录实验数据时,大家都在人为调整。
吕翔称,张裕卿的实验室,从2011年到2016年几乎从未预约过表征 (用物理或化学方法对物质进行化学性质的分析、测试或鉴定,并阐明物质的化学特性)。所有的论文数据和图片,无论网上截图、还是找别人借数据、要图片,都需要学生自己造假。2011-2020年期间,张平均每年发表四篇SCI,据吕翔称,每篇SCI成本不足500元。而张的履历,也因此非常亮眼。
吕翔表示,之所以长时间无人举报,是因为张裕卿会在学生毕业时,逼他们签一份声明,声明这些实验数据都是真的,不然就让学生无法顺利毕业。吕翔于2016年6月退学,并曾于2017年与张裕卿教授就造假问题沟通过一次,但得到的回复如下:

那么,张教授造假的论文,究竟有多离谱?吕翔以自己的亲身经历为例,详细列举了张裕卿在学术论文上造假的种种劣迹。
第一类,生造数据。无论是不符合要求的实验数据,还是没做过实验的数据,只要想,就能造出来。
这是吕翔小论文中的实验数据。这里会用到一个高中数学知识,lg(x)中的x必须大于0,否则就没有意义。所以,根据计算公式,这个数据原本根本就算不出来,但张裕卿却要求强行编一个数据进去。

这样的“违背常识”,不仅不止一次,而且吕翔自述称,这种现象“多着呢”。据吕翔称,在涉及到膜的稳定性论文上,由于审稿需要,大论文上根本没有,张裕卿就指导吕翔预测数据。在张裕卿的“指导”下,吕翔在10分钟内就预测了6个月的数据,数据还精确到了小数点后两位。
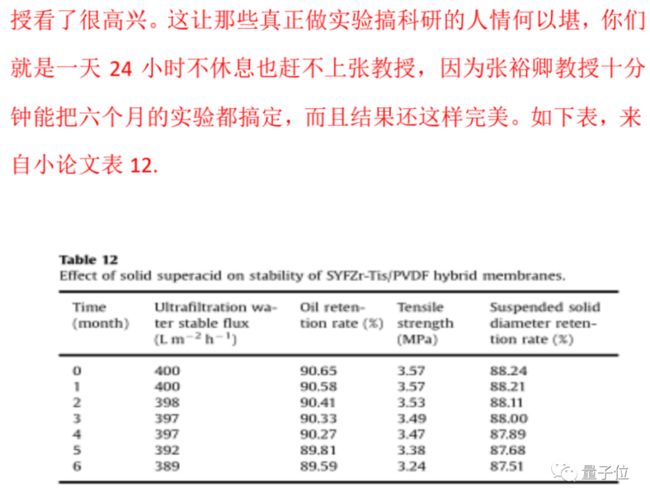
第二类,直接上手P图,无论是自己之前发过的论文、还是网上的截图,都可以拿来P。据吕翔称,下面的图,全都是来自一个样品,也就是说,5篇论文只做过1次实验。但因为这样的图在网上太难找,所以其他论文只能在第一幅图上进行加工。
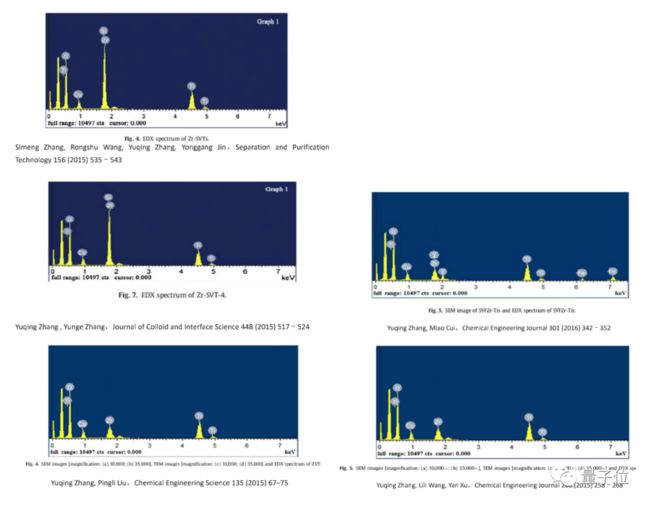
除了一个图片抄袭加工五次,甚至还有直接在图片结果上进行改正,使数据看起来符合预期的。下面这张图,据吕翔称,所有圈出来的峰值都是他们在后期自己加工P上去的,目的就是为了让论文更好写。

等等,似乎这张图还发现了什么华点?(嗯,张连自己的名字都打错了……)

这样的例子,在举报信中还有很多,吕同学历时4年,写得非常详细,有理有据,堪比论文——甚至最后还有参考文献。
此外,张裕卿甚至直接给自己2011年-2015年期间还在读本科的女儿张丝萌“开了后门”。给自己女儿发表的所有论文,二作永远是张裕卿的导师王荣树。这里面,不仅自我抄袭(抄的硕士毕业论文),还给自己的女儿当上一作,这里只是其中的两篇,一共有7篇,一作4篇,3作3篇。

值得一提的是,据吕翔称,张丝萌本科就读于河北工业大学,从来没有来过张裕卿的实验室。吕翔表示,张裕卿本人曾说,他在女儿上高中的时候,就让她帮忙修改过研究生论文了。

这封举报信,无疑给天大和科研界投下了一枚重磅炸弹。但出于外界意料,这一次天津大学反应非常迅速,第一时间给出了调查及处理结果:
已解除聘用。

而天大这次雷厉风行,也被与近年来教育部重点打击学术不端的态度,联系在一起。2016年,教育部就发布了《高等学校预防与处理学术不端行为办法》,其中明确规定了学术不端行为的认定和处理办法。
今年7月,教育部印发《关于进一步加强面向中小学生的全国性竞赛活动管理工作的通知》。针对“学二代”现象,通知中第五条给出明确说明,重点是对于为子女、他人提供帮助参加评奖的的行为,无论是教师还是父母,或是其他人,一经发现,依据法规严肃处理。
信息来源:量子位
03
夺魁NeurIPS 2020电网调度大赛,百度PARL实现NeurIPS强化学习竞赛三连冠
受疫情影响,人工智能顶级学术会议 NeurIPS 2020 将通过线上的形式进行。随着会议召开时间临近,该会议承办的竞赛也陆续揭晓结果。今年新增的电网调度竞赛(Learning To Run a Power Network Challenge)共包含两个赛道:鲁棒能力赛道和泛化能力赛道,经过三个月的激烈比拼,最终来自百度的 PARL 团队拿下全部两个赛道的冠军。同时,这也是该团队在 NeurIPS 上拿下的第三个强化学习赛事冠军,实现三连冠的里程碑。
NeurIPS 2020 电网调度大赛主要是由 RTE(法国电网公司)、EPRI(美国电力研究协会)和 TenneT(德国 - 荷兰电网公司)等能源企业联合 INRIA(法国国家信息与自动化研究所)、谷歌研究、UCL 和卡塞尔大学等人工智能研究机构共同举办。赛事共吸引了来自全球的上百支队伍,参赛选手中有来自各个地区的人工智能研究机构,还有来自清华大学、国家电网北美研究院等机构的电网领域专家。本次赛事的举办主旨是探索强化学习在能源调度领域的应用,希望结合强化学习技术实现电网传输的自动化控制,保障整个电网系统在各种突发状况下都能稳定运行。
PARL 开源仓库地址:
https://github.com/PaddlePaddle/PARL
本次电网调度竞赛的总体任务目标是维持整个电网仿真系统的供需平衡,并应对各种突发事件。在电网仿真环境运行的每一个时刻,参赛选手需要根据观测到的电网状态(供电 / 用电数据、电网拓扑结构和电线负载等信息),选择合适的动作(包括变电站拓扑修改和发电厂发电功率修改等)来保持电网的稳定运行。NeurIPS 2020 举办的电网调度赛事相比前两届的电网调度赛事具有更大的挑战难度,不仅电网规模更大,动作空间也更复杂,而且根据电网的真实场景,分别设置了更具有现实意义的鲁棒性(Robustness)和适应性(Adaptability)两个挑战赛道。两个赛道的设置分别如下:
Track 1(赛道一):采用中型电网(相当于三分之一的美国中西部电网),离散动作空间数量有 6 万多个。该赛道中,每天电网的不同线路会因随机的攻击而断开,以此模拟现实生活中电网系统受到不可预期的事故(例如被闪电击中),对决策系统在各种突发事件下的鲁棒性而言,是个很大的挑战。
Track 2(赛道二):采用大型电网(相当于整个美国中西部电网),离散动作空间数量高达 7 万多个。该赛道中,发电厂的可再生能源比例是动态变化的(比如风能在夏季发电效率高,冬季则下降),为了保持整个电网的供需平衡,这个赛道对决策系统在不同能源比例下的自动适应能力有很高的要求。
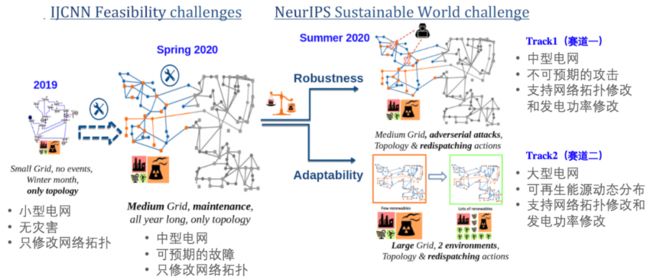
电网调度系列赛事
从官方榜单中可以看到,百度 PARL 团队拿下了两个赛道的冠军,在比赛阶段的公榜以及评估阶段的私榜上都名列第一,体现了强大的技术能力,以及针对实际场景的技术实用性。
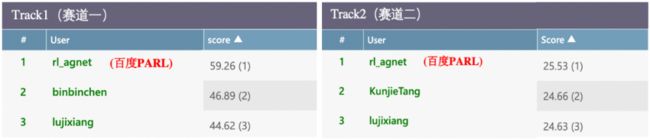
百度 PARL 拿下电网调度大赛双料冠军。
在参赛过程中,百度 PARL 团队注意到专家系统方案以及纯强化学习方案很难解决这次的挑战。传统的专家系统解决方案主要是利用专家先验知识进行候选动作的筛选,然后根据电网系统的预仿真(simulate)功能来评估不同动作给电网系统带来的影响,这种方案需要有一定的专家经验,并且存在搜索耗时长和无法考虑长远收益等缺点。纯强化学习方案虽然可以考虑长远收益,但在大规模电网调度场景中,动作空间复杂,电网系统运行过程中不确定性大,这个方案存在探索难度大和价值函数训练方差大等问题,很难在数万个候选动作中直接选择一个最优动作。
百度 PARL 团队提出了一种融合专家系统和强化学习两者优点的解决方案:融合专家知识的大规模进化神经网络,该方案首先采用模仿学习(Imitation learning)来学习专家知识,得到一个用神经网络表示的策略之后,通过进化算法迭代这个策略。需要注意的是,一般强化学习算法是每次采样一个动作然后根据反馈(reward)进行更新,在该方案的进化算法中,每次会采样多个动作(动作组合)进行优化。当选出动作组合之后,后续的策略依然可以拼接多种专家经验,选出更优的动作。得益于进化算法的黑盒优化特点,整个策略可以直接把电网平稳运行时长作为反馈来更新策略。这个解决方案不仅可以克服强化学习选择单一动作风险高的问题,还可以考虑电网系统的长期奖励,有利于寻找维持电网系统稳定运行的最优解。
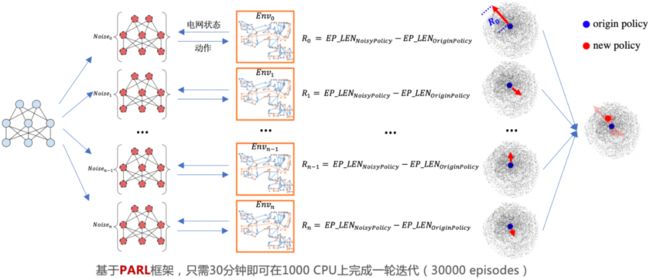
大规模进化算法图示。
PARL 是基于百度飞桨深度学习平台(PaddlePaddle)自主研发的强化学习框架,汇聚了百度多年来在强化学习领域的技术深耕和产品应用经验。PARL 采用模块式的编码设计,已复现的算法覆盖了包括 Multi-gent、Model-based、Evolution Strategy 和 Distributed RL 等不同方向的主流强化学习算法。除了强可扩展性和高质量算法复现,PARL 框架更提供了高性能且便捷灵活的并行支持能力。开发者只需要通过数行代码和命令就能搭建起集群,并行调度资源,低成本地实现数百倍的性能加速。正是基于这样的能力,PARL 团队连续拿下了 NeurIPS 2018/2019 仿生人 Learning To Run 挑战和 NeurIPS 2020 L2RPN 挑战三连冠。
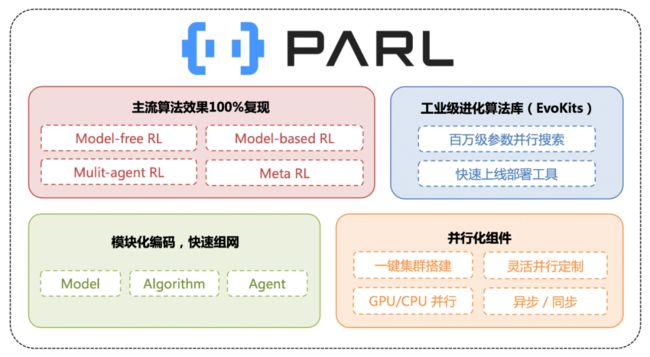
PARL 框架概览。
据悉,PARL 框架已经应用在信息流推荐、智能打车、智能机器人等多个行业领域,也将致力于把强化学习运用在能源调度、供应链和交通等更多场景,将强化学习独有的决策能力赋予到各行各业。
信息来源:飞桨PaddlePaddle
04
人脸识别第一案判决:原告郭教授获赔偿,仍将上诉
去年 10 月,浙江理工大学的特聘副教授郭兵,因拒绝刷脸入园,将杭州野生动物世界告上法院一事引发社会广泛关注:
2019 年 4 月,郭兵支付 1360 元购买野生动物世界双人年卡,确定指纹识别的入园方式。郭兵与其妻子留存了姓名、身份证号码、电话号码等,并录入指纹、拍照。2019 年 7 月、10月,野生动物世界两次向郭兵发送短信,通知年卡入园识别系统更换事宜,要求激活人脸识别系统,否则将无法正常入园。野生动物园将年卡用户的入园方式从指纹识别再度升级为人脸识别。郭兵认为人脸信息属于高度敏感个人隐私,不同意接受人脸识别,要求园方退卡。双方协商未果,2019 年 10 月 28 日,郭兵向杭州市富阳区人民法院提起诉讼。同年11月3日,杭州市富阳区人民法院正式受理此案。
11 月 20 日下午,杭州市富阳区人民法院公开开庭,宣判原告郭兵与被告杭州野生动物世界有限公司(以下简称野生动物世界)服务合同纠纷一案。本次法院判决结果如下:
野生动物世界赔偿郭兵合同利益损失及交通费共计 1038 元,删除郭兵办理指纹年卡时提交的包括照片在内的面部特征信息;
驳回郭兵提出的确认野生动物世界店堂告示、短信通知中相关内容无效等其他诉讼请求。
法院观点 :
本案双方因购买游园年卡而形成服务合同关系,后因入园方式变更引发纠纷,其争议焦点实为对经营者处理消费者个人信息,尤其是指纹和人脸等个人生物识别信息行为的评价和规范问题。
我国法律对于个人信息在消费领域的收集、使用虽未予禁止,但强调对个人信息处理过程中的监督和管理,即:
个人信息的收集要遵循「合法、正当、必要」的原则和征得当事人同意;
个人信息的利用要遵循确保安全原则,不得泄露、出售或者非法向他人提供;
个人信息被侵害时,经营者需承担相应的侵权责任。
判决根据一: 消费者知情权与个人信息自主决定权,未受侵害
本案中,客户在办理年卡时,野生动物世界未对消费者作出不公平、不合理的其他规定,因此客户的消费知情权和对个人信息的自主决定权未受到侵害。郭兵系自行决定提供指纹等个人信息而成为年卡客户。
判决根据二:野生动物世界单方变更合同,属违约
野生动物世界在经营活动中使用指纹识别、人脸识别等生物识别技术,其行为本身并未违反前述法律规定的原则要求。但是,野生动物世界在合同履行期间,将原指纹识别入园方式变更为人脸识别方式,属于单方变更合同的违约行为,该做法不构成双方合同内容,对郭兵不具有法律效力,因此,郭兵作为守约方,有权要求野生动物世界承担相应法律责任。
判决根据三:野生动物世界采集原告照片信息,不具正当性
此外,双方在办理年卡时,约定采用的是以指纹识别方式入园,野生动物世界采集郭兵及其妻子的照片信息,超出了法律意义上的必要原则要求,故不具有正当性。此外,审理中未发现有证据表明野生动物世界对郭兵实施了欺诈行为。
综上,法庭依法作出前述一审判决。
「人脸识别第一案」引发社会各界对于 AI 技术、大数据及其背后隐私问题的更多思考,其实相关的立法也在推动和实施中。今年 5 月在十三届全国人大三次会议表决通过的《民法典》,也再次强调了个人信息的保护,专章规定了「隐私权和个人信息保护」。

《民法典》也首次明确将个人生物识别信息纳入个人信息的保护范畴,这是法律对人格权保护的重要扩展。不过,新版《民法典》将于 2021 年 1 月 1 日正式实施,在本案判决并不生效,也无法援引,另外由于本案的具体情况,仍聚焦于野生动物园的合同违约行为。
「人脸识别第一案」作为全国第一个因人脸识别引起的民事诉讼案,坚持维护权益的郭兵教授的行为,具有着全国性的示范意义。
信息来源:量子位
05
AI性能暴涨7倍,AMD昨夜发布Instinct MI100新卡,英伟达也祭出百亿亿次超算时代神器
AMD (超微半导体公司)昨夜正式推出其 AMD Instinct MI100 加速GPU芯片,这是一款新的图形处理器处理器(GPU) ,在科学研究计算方面起着专门的加速器作用。
这种 7nm GPU 加速器使用 AMD 的 CDNA 结构来处理高性能计算(HPC)和人工智能任务,这样科学家们就可以从事重负荷的计算任务,比如冠状病毒研究。MD 公司表示,MI100芯片是世界上最快的高性能计算处理器 GPU,也是第一个性能超过10万亿次浮点运算的 x86 服务器 GPU。

该设备支持新的加速计算包括 AMD 的客户:戴尔,技嘉,惠普和超微。

AMD高级副总裁丹 · 麦克纳马拉在新闻发布会上说: 「高性能计算机在分析感染冠状病毒、开发疫苗以及各种生命科学应用的可能性方面确实发挥了非常重要的作用」。
MI100与第二代 AMD Epyc 处理器和 ROCm 4.0开放软件相结合,旨在帮助科学家取得科学突破。
用于图形和企业的GPU
今年3月,AMD发布了其首个专门针对数据中心高性能计算而设计的CDNA架构,与其Radeon的 RDNA 游戏架构分道扬镳。二者虽然还有一些共通点,但在设计、优化上已经在各自的领域里有了不同的特色。
AMD的内部人士也称,不同的任务处理实际上并不需要共存,没有必要用一个芯片去玩steam游戏的同时也可以进行高级分子模拟、抗震分析或天体物理模拟。Instinct MI100 是 AMD 史上性能最高的HPC GPU,FP64 双精度浮点性能达到了 11.5 TFlops(也就是每秒1.15亿亿次),并在架构设计上专门加入了 Matrix Core(矩阵核心),用于加速HPC、AI运算。

AMD称其在混合精度和FP16半精度的AI负载上,性能提升接近7倍,为 AI 和机器学习工作负载提供 FP32 Matrix 单精度矩阵计算为 46.1TFlops(每秒4.61亿亿次),FP16 Matrix 半精度矩阵计算为 184.6TFlops(每秒18.46亿亿次),Bfloat16 浮点为92.3TFlops(每秒9.23亿亿次)的性能。
既然AMD发布了MI100,那老对手自然也不会缺席。AMD这款芯片的竞争对手是80GB 版本的 Nvidia A100 GPU,该GPU也于今天发布。该芯片基于英伟达的 Ampere 图形架构,旨在通过实现更好的实时数据分析,帮助企业和政府实验室更快地做出关键决策。

A100 80GB 版本的内存是六个月前推出的上一代的两倍。A100 芯片为研究人员和工程师提供了更快的速度和更高的性能,用于人工智能和科学应用。它提供超过每秒2 terabytes的内存带宽,这使得系统能够更快地将数据提供给 GPU。
Nvidia今天还宣布,新芯片将与 AMD 新推出的 Instinct MI100 GPU 竞争。与 AMD 相比,Nvidia 有一个单一的 GPU 架构,既可用于人工智能,又可用于图形处理。有国外的分析师认为,AMD GPU 的性能比 Nvidia 最初的40GB A100提高了18% 。但他说真正的应用程序可能会受益于80GB 的 Nvidia 版本。同时他还表示,虽然价格敏感的客户可能青睐 AMD,但他认为 AMD 在人工智能性能方面无法与 Nvidia 抗衡。
在人工智能领域,英伟达再次提高了门槛,几乎没有任何竞争对手能够跨越这一障碍。Nvidia 说,A100 80GB 消除了对数据或模型并行体系结构的需求,这些体系结构实现起来很费时间,跨多个节点运行起来很慢。
通过其多实例 GPU (MIG)技术,A100可以被划分为多达7个 GPU 实例,每个实例拥有10GB 的内存。这提供了安全的硬件隔离,并最大限度地利用 GPU 的各种较小的工作负载。而A100 80GB 与AMD的芯片一样,同样可以为科学应用提供加速,比如天气预报和量子化学。
信息来源:新智元
飞桨(PaddlePaddle)以百度多年的深度学习技术研究和业务应用为基础,是中国首个开源开放、技术领先、功能完备的产业级深度学习平台,包括飞桨开源平台和飞桨企业版。飞桨开源平台包含核心框架、基础模型库、端到端开发套件与工具组件,持续开源核心能力,为产业、学术、科研创新提供基础底座。飞桨企业版基于飞桨开源平台,针对企业级需求增强了相应特性,包含零门槛AI开发平台EasyDL和全功能AI开发平台BML。EasyDL主要面向中小企业,提供零门槛、预置丰富网络和模型、便捷高效的开发平台;BML是为大型企业提供的功能全面、可灵活定制和被深度集成的开发平台。
END
