java面试知识点精华提炼
持续更新中。。。。。。
java基础
== 和 equals 的区别?
- equals 和 == 最大的区别是一个是方法一个是运算符。
- ==如果比较的对象是基本数据类型,则比较的是数值是否相等;如果比较的是引用数据类型,则比较的是对象的地址值是否相等。
- equals():用来比较方法两个对象的内容是否相等。
注意:equals 方法不能用于基本数据类型的变量,如果没有对 equals 方法进行重写,则比较的是引用类型的变量所指向的对象的地址。
int 和 Integer 的区别
int是基本数据类型,Integer是包装类(Integer是对象),Integer可以像对象一样被操作
java集合
- Collection:Collection 是集合 List、Set、Queue 的最基本的接口。
- Iterator:迭代器,可以通过迭代器遍历集合中的数据
- Map:是映射表的基础接口
1、Collection 和 Map 的继承体系:

list 集合
- List 是有序、且可以重复的 Collection集合。List 一共三个实现类,分别是 ArrayList、Vector 和 LinkedList。
ArraList
ArrayList 内部是通过数组实现,特点:读取快,增删慢。并且它是线程不安全的。
- 因为数组元素之间不能有间隔,所以从中间位置增删元素,需要对数组进行复制、移动、代价比较高。因此读取快,增删慢。
- ArrayList 初始大小是10,每次扩容是原来的1.5倍。
- ArrayList每次扩容都是通过Arrays.copyof(elementData,newCapacity)来实现的。
- 在知道元素的大致数量时提前指定集合的大小,可以做到优化作用。
LinkList
- LinkedList 是用链表结构存储数据的双向链表、支持序列化,特点:读取慢,增删快。并且它是线程不安全的。
- LinkedList 提供了 List 接口中没有定义的方法,用于操作表头和表尾元素,可以当作堆栈、队列和双向队列使用。
Vector(数组实现、线程同步)
- Vector 也是通过数组实现,不同的是它支持线程的同步,所以是线程安全的。
- 实现同步需要很高的花费,因此访问它比访问 ArrayList 慢。
Set 集合
- Set 是无序、且不可以重复的 Collection集合。
- set中是以对象的hashcode值作为判断,判断两个对象是否相等。
- 如果想要让两个不同的对象视为相等的,就必须覆盖 Object 的 hashCode 方法和 equals 方法。
HashSet(Hash 表)
- HashSet存放的是哈希值,存储元素的顺序是按照哈希值来存的。
- 取数据也是按照哈希值取得。元素的哈希值是通过元素的hashcode 方法来获取的。
- HashSet 首先判断两个元素的哈希值如果一样,会接着比较equals 方法,如果equals 方法结果相等就视为同一个元素,结果不相等就视为不同元素。
- 哈希值相同 equals 方法不相等的元素,是在同样的哈希值下顺延(可以认为哈希值相同的元素放在一个哈希桶中),也就是哈希一样的存一列
- HashSet 通过 hashCode 值来确定元素在内存中的位置,一个 hashCode 位置上可以存放多个元素。
如图 1 表示 hashCode 值不相同的情况; 图2 表示 hashCode 值相同,但 equals 不相同的情况。

- 当new 一个HashSet实例时, 其实底层是新创建了一个HashMap实例。 HashSet中的元素实际上由HashMap的key来保存,而HashMap的value则存储了一个PRESENT,它是一个静态的Object对象。
TreeSet(二叉树)
- TreeSet 是使用二叉树的原理对 add 的对象按照指定的顺序排序(升序、降序),每增加一个对象都会进行排序,将对象插入到二叉树指定的位置。
- Integer 和 String 对象都可以进行默认的 TreeSet 排序,而自定义类的对象是不可以的,自己定义的类必须实现 Comparable 接口,并且覆写相应的 compareTo()函数,才可以正常使用。
- 在覆写 compare()函数时,要返回相应的值才能使 TreeSet 按照一定的规则来排序,比较此对象与指定对象的顺序。
- 如果该对象小于、等于或大于指定对象,则分别返回负整数、零或正整数。
LinkHashSet(HashSet+LinkedHashMap)
- LinkedHashSet 继承与 HashSet、又基于 LinkedHashMap 来实现的。
- LinkedHashSet 通过传递一个标识参数,调用父类的构造器,底层构造一个 LinkedHashMap 来实现,在相关操
作上与父类 HashSet 的操作相同,直接调用父类 HashSet 的方法即可。
Map
HashMap(数组+链表+红黑树)
- java7中 hashmap 使用,数组+链表实现
- java8以后 hashmap 使用,数组+链表+红黑树实现
- HashMap 根据键的 hashCode 值存储数据,具有很快的访问速度,但遍历顺序却是不确定的。 查询快无序
- HashMap 中 key 不可重复,value可以重复,且线程不安全。
- HashMap 可以用 Collections 的 synchronizedMap 方法实现线程安全的能力,或者使用 ConcurrentHashMap。

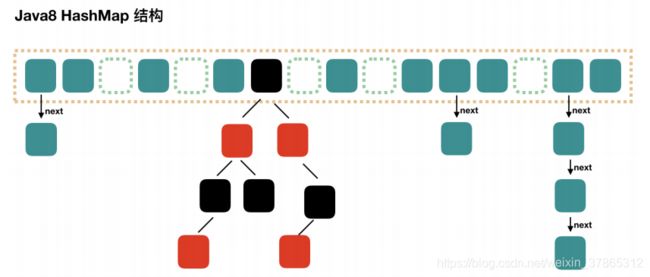
- 大方向上,HashMap 里面是一个数组,然后数组中每个元素是一个单向链表。
- 上图中每个绿色的实体是嵌套类 Entry 的实例,Entry 包含四个属性:key, value, hash 值和用于单向链表的 next。
- Java8 以后当链表中的元素超过了 8 个以后,会将链表转换为红黑树,
- 红黑树为了降低时间复杂度,由原来的 O(n) 降为 O(LogN),以加快检索速度。
- capacity:当前数组容量,始终保持 2^n,可以扩容,扩容后数组大小为当前的 2 倍。
- loadFactor:负载因子,默认为 0.75。
- threshold:扩容的阈值,等于 capacity * loadFactor
ConcurrentHashMap
- Java7 以前使用 segment(分段) + 数组 + 链表 实现,使用对 segment(分段)加锁实现线程安全,简称分段锁。
- Java8 以后使用 数组 + 链表 + 红黑树 实现,使用Synchronized和CAS实现线程安全。
1、Java7 以前 ConcurrentHashMap 由一个个 Segment(分段) 组成。
- Segment(分段) 通过继承 ReentrantLock 来进行加锁,每次加锁的操作锁住的是一个 segment(分段),这样只要保证每个 Segment 是线程安全的,也就实现了全局的线程安全。
- Segment(分段) 数量默认是 16,初始化时可以设置为其他值,但是一旦初始化以后,它是不可以扩容的。
- 因为是对 Segment(分段)单独加锁,所以理论上,最多可以同时支持 16 个线程并发写,只要它们的操作分别分布在不同的 Segment 上
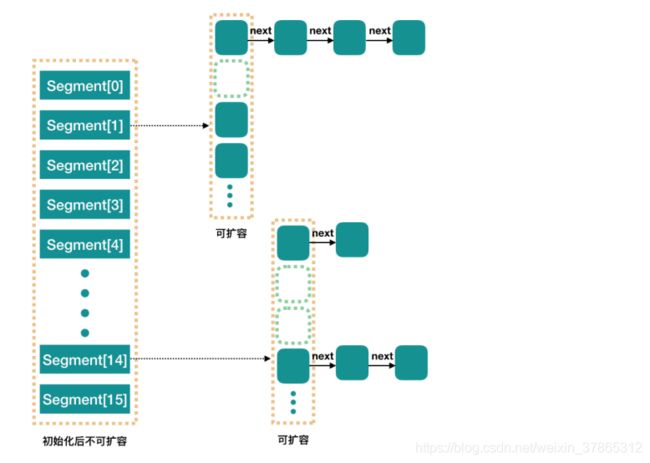
2、Java8以后 ConcurrentHashMap 和 HashMap 实现是差不多的,只是比HashMap多了Synchronized和CAS实现线程安全。
- 在 put 时首先计算 key 的 hash 值,判断 hash 值有没有冲突,没有冲突直接 CAS 插入。
- 如果 hash 值存在冲突,就使用 Synchronized 加锁,加锁时会只锁住单一链表或者红黑树的头结点。
HashTable(线程安全)
- Hashtable 很多的常用功能与 HashMap 类似,不同的是它继承自 Dictionary 类,并且是线程安全的。
- 并发性不如 ConcurrentHashMap,因为 ConcurrentHashMap 引入了分段锁。
- Hashtable 不建议使用,可以使用 HashMap 和 ConcurrentHashMap 代替。
TreeMap(可排序)
- TreeMap 实现 SortedMap 接口,根据键排序,默认是按键值的升序排序,也可以自定义排序。
- 如果使用到排序的功能,建议使用 TreeMap。
在使用 TreeMap 时,key 必须实现 Comparable 接口或者在构造 TreeMap 传入自定义的
Comparator,否则会在运行时抛出 java.lang.ClassCastException 类型的异常。
LinkHashMap(记录插入顺序)
- LinkedHashMap 是 HashMap 的一个子类,保存了元素的插入顺序,在用 Iterator 遍历
- LinkedHashMap 时,先得到的记录肯定是先插入的,也可以在构造时带参数,按照访问次序排序。
反射机制
- 反射机制是程序在运行中,获取任意一个类的属性和方法,并且可以调用。以达到动态获取类信息、动态调用对象的方法。
- 反射将类的各个组成部分封装成其他对象,这就是反射机制。
反射的应用场合
- Java 对象在运行时可能会出现两种类型:编译时类型和运行时类型。
- 编译时的类型由声明对象时用的类型来决定,运行时的类型由实际赋值给对象的类型决定 。
如:Person p=new Student();
其中编译时类型为 Person,运行时类型为 Student。
程序在运行时想要获取 Student 对象的真实信息,就只能依靠运行时信息来发现该对象和类的真实信息,此时就必须使用到反射了
反射 API
- Class 类:反射的核心类,可以获取类的属性,方法等信息。
- Field 类:Java.lang.reflec 包中的类,表示类的成员变量,可以用来获取和设置类之中的属性值。
- Method 类: Java.lang.reflec 包中的类,表示类的方法,它可以用来获取类中的方法信息或者执行方法。
- Constructor 类: Java.lang.reflec 包中的类,表示类的构造方法。
- 获取 Class 对象的 3 种方法
// 1 调用某个对象的 getClass()方法
Person p=new Person();
Class clazz=p.getClass();
// 2 调用某个类的 class 属性来获取该类对应的 Class 对象
Class clazz=Person.class;
// 3 使用 Class 类中的 forName()静态方法(最安全/性能最好/最常用)
Class clazz=Class.forName("类的全路径");
- 通过 Class 类中的方法获取并查看该类中的方法和属性。
// 获取 Person 类的 Class 对象
Class clazz=Class.forName("reflection.Person");
// 使用.newInstane 方法创建对象
Person p=(Person) clazz.newInstance();
// 获取构造方法创建对象并设置属性
Constructor c=clazz.getDeclaredConstructor(String.class,String.class,int.class);
Person p1=(Person) c.newInstance("李四","男",20);
//获取 Person 类的所有方法信息
// getMethods(),该方法是获取本类以及父类或者父接口中所有的公共方法(public修饰符修饰的)
// getDeclaredMethods(),该方法是获取本类中的所有方法,包括私有的(private、protected、默认以及public)的方法。
Method[] method=clazz.getDeclaredMethods();
for(Method m:method){
System.out.println(m.toString());
// 调用方法 使方法执行
m.invoke(p, 20);//需要两个参数,一个是要调用的对象(获取有反射),一个是实参
}
//获取 Person 类的所有成员属性信息
Field[] field=clazz.getDeclaredFields();
for(Field f:field){
System.out.println(f.toString());
}
//获取 Person 类的所有构造方法信息
Constructor[] constructor=clazz.getDeclaredConstructors();
for(Constructor c:constructor){
System.out.println(c.toString());
}
序列化和反序列化
- 序列化:将对象写入到IO流中
- 反序列化:从IO流中恢复对象
- 在类中增加 writeObject 和 readObject 方法可以实现自定义序列化策略。
- 通过 ObjectOutputStream 和 ObjectInputStream 对对象进行序列化及反序列化。
- 意义:序列化机制允许将实现序列化的Java对象转换为字节序列,这些字节序列可以保存在磁盘上,或通过网络传输,以达到以后恢复成原来的对象。序列化机制使得对象可以脱离程序的运行而独立存在。
- 使用场景:所有可在网络上传输的对象都必须是可序列化的,比如RMI(remote method invoke,即远程方法调用),传入的参数或返回的对象都是可序列化的,否则会出错;所有需要保存到磁盘的java对象都必须是可序列化的。
- 通常建议:程序创建的每个JavaBean类都实现Serializeable接口。并且创建序列化ID,用来判断是否可以反序列化。
- 序列化并不保存静态变量
- 要想将父类对象也序列化,就需要让父类也实现 Serializable 接口。
- 如果不想让某个变量被序列化,使用transient修饰,反序列化后,transient 变量的值被设为初始值,如 int 型的是 0,对象型的是 null。
- 对象的类名、实例变量(包括基本类型,数组,对其他对象的引用)都会被序列化;方法、类变量、transient实例变量都不会被序列化。
- 序列化对象的引用类型成员变量,也必须是可序列化的,否则,会报错。
- 反序列化时必须有序列化对象的class文件。
- 同一对象序列化多次,只有第一次序列化为二进制流,以后都只是保存序列化编号,不会重复序列化。
IO和NIO
1、主要区别:
- io是面向流、阻塞的。 Nio是面向缓存、非阻塞的。
- 传统IO基于字节流和字符流进行操作。
- NIO基于Channel(通道)、Buffer(缓冲区)进行操作,数据从通道读取到缓冲区中,或者从缓冲区读取到通道中。
- NIO中使用Selector(选择区)监听多个Channel(通道)事件,因此单个线程可以监听多个数据通道。(比如:连接打开,数据到达)
2、IO 工作流程:
- 由于Java IO是阻塞的,所以当面对多个流的读写时需要多个线程处理。例如在网络IO中,Server端使用一个线程监听一个端口,一旦某个连接被accept,创建新的线程来处理新建立的连接。其中 read/write 是阻塞的。
3、NIO 工作流程:
- NIO 提供 Selector 实现单个线程管理多个channel的功能。select 调用可能是阻塞的,也可以是非阻塞的。但是read/write是非阻塞的!
4、NIO为什么会被阻塞:
//这个方法可能会阻塞,直到有一个已注册的事件发生,或者当一个或者更多的事件发生时
//可以设置超时时间,防止进程阻塞
selector.select(long timeout);
//使用此方法可以防止阻塞,阻塞在select()方法上的线程也可以立刻返回,不阻塞
selector.selectNow();
//可以唤醒阻塞状态下的selector
selector.wakeup();
5、BIO、NIO、AIO 有什么区别:
- BIO:Block IO 同步阻塞式 IO,就是我们平常使用的传统 IO,它的特点是模式简单使用方 便,并发处理能力低。
- NIO:New IO 同步非阻塞 IO,是传统 IO 的升级,客户端和服务器端通过 Channel(通道) 通讯,实现了多路复用。
- AIO:Asynchronous IO 是 NIO 的升级,也叫 NIO2,实现了异步非堵塞 IO ,异步 IO 的 操作基于事件和回调机制。
代码执行顺序:父类子类 静态代码块、构造代码块、构造方法执行顺序
父静态、子静态、父构造代码块、父构造方法、子构造代码块、子构造方法
java多线程实现
- 创建多线程有4种方式,其中两种有返回值,两种没有返回值。
1.继承Thread类,重写run方法(其实Thread类本身也实现了Runnable接口)
2.实现Runnable接口,重写run方法
3.实现Callable接口,重写call方法(有返回值)
4.使用线程池(有返回值)
四种线程池
- Java 里面线程池的顶级接口是 Executor,但是严格意义上讲 Executor 并不是一个线程池,而只是一个执行线程的工具。真正的线程池接口是 ExecutorService。
- newSingleThreadExecutor
创建一个单线程的线程池。这个线程池只有一个线程在工作,也就是相当于单线程串行执行所有任务。如果这个唯一的线程因为异常结束,那么会有一个新的线程来替代它。此线程池保证所有任务的执行顺序按照任务的提交顺序执行。
new ThreadPoolExecutor(1, 1, 0L, TimeUnit.MILLISECONDS, new LinkedBlockingQueue<Runnable>());
- newFixedThreadPool
创建固定大小的线程池。每次提交一个任务就创建一个线程,直到线程达到线程池的最大大小。线程池的大小一旦达到最大值就会保持不变,如果某个线程因为执行异常而结束,那么线程池会补充一个新线程。
new ThreadPoolExecutor(int, int, 0L, TimeUnit.MILLISECONDS, new LinkedBlockingQueue<Runnable>());
- newCachedThreadPool
创建一个可缓存的线程池。如果线程池的大小超过了处理任务所需要的线程,那么就会回收部分空闲(60秒不执行任务)的线程,当任务数增加时,此线程池又可以智能的添加新线程来处理任务。此线程池不会对线程池大小做限制,线程池大小完全依赖于操作系统(或者说JVM)能够创建的最大线程大小。
new ThreadPoolExecutor(0, Integer.MAX_VALUE, 0L, TimeUnit.MILLISECONDS, new LinkedBlockingQueue<Runnable>());
- newScheduledThreadPool
创建一个大小无限的线程池。此线程池支持定时以及周期性执行任务的需求。
new ScheduledThreadPoolExecutor(10);
线程生命周期(状态)
- 线程有五种状态 新建(New)、就绪(Runnable)、运行(Running)、阻塞(Blocked)、死亡(Dead) 。
- 新建(New):使用 new 创建了一个线程之后,该线程就处于新建状态,此时仅由 JVM 为其分配内存,并初始化其成员变量的值
- 就绪(Runnable):线程对象调用 start()方法之后,该线程处于就绪状态。JVM 为其创建方法调用栈和程序计数器,等待调度运行。
- 运行(Running):如果处于就绪状态的线程获得了 CPU,开始执行 run() 方法的线程执行体,则该线程处于运行状态。
- 阻塞(Blocked):
指线程因为某种原因放弃了 cpu 使用权,也即让出了 cpu timeslice,暂时停止运行。
直到线程进入可运行(runnable)状态,才有机会再次获得 cpu timeslice 转到运行(running)状态。 - 阻塞的情况分三种:
- 等待阻塞(o.wait->等待对列):运行(running)的线程执行 o.wait()方法,JVM会把该线程放入等待队列(waitting queue)中。
- 同步阻塞(lock->锁池):运行(running)的线程没有获取到同步锁,该同步锁被别的线程占用,则JVM会把该线程放入锁池(lock pool)中。
- 其他阻塞(sleep/join):运行(running)的线程执行 Thread.sleep(long ms)或 t.join()方法,或者发出了 I/O 请求时,JVM 会把该线程置为阻塞状态。当 sleep()状态超时、join()等待线程终止或者超时、或者 I/O处理完毕时,线程重新转入可运行(runnable)状态。
- 线程死亡(DEAD):线程会以下面三种方式结束,结束后就是死亡状态。
- 正常结束,run()或 call()方法执行完成,线程正常结束。
- 异常结束,线程抛出一个未捕获的 Exception 或 Error。
- 调用 stop,直接调用该线程的 stop()方法来结束该线程—该方法通常容易导致死锁,不推荐使用。

sleep 与 wait 区别
- sleep()方法属于 Thread 类,而 wait()方法,则是属于Object 类中的。
- sleep()方法是暂停执行指定的时间,让出 cpu 给其他线程,但是他的监控状态依然保持,当指定的时间到了又会自动恢复运行状态。
- 在调用 sleep()方法的过程中,线程不会释放对象锁。
- 在调用 wait()方法的时候,线程会放弃对象锁,并进入等待队列,当其他线程调用notify()或者notifyAll()方法时,当前线程进入就绪状态
start 与 run 区别
- start()方法使用来启动线程,真正实现了多线程运行。这时无需等待 run 方法体代码执行完毕,可以直接继续执行下面的代码。
- run()方法是线程体,包含了要执行的内容,直接调用run()方法,并不是启动线程,和普通方法是一样的。
java框架
spring框架
spring核心
- IOC(Inverse of Control 控制反转):就是Spring 通过一个配置文件来,利用 Java 反射功能实例化并负责控制对象的,生命周期和对象间的关系。还提供了 Bean 实例缓存、生命周期管理、 Bean 实例代理、事件发布、资源装载等高级服务。
- AOP(Aspect Oriented Programming 面向切面编程):AOP 是一种编程思想,是面向对象编程(OOP)的一种补充。面向对象编程将程序抽象成各个层次的对象,而面向切面编程是将程序抽象成各个切面。
Spring 常用模块
- spring Beans:
- spring context:
- spring AOP:
- spring DAO:
- spring ORM:
- spring web:
spring常用注解
- @Controller(@RestController):
- @RequestMapping(@GetMapping、@PostMapping):
- @ResponseBody:
- @RequestBody:
- @RequestParam:
- @PathVariable:
- @Service:
- @Repository:
- @Autowired:注入对象
- @Component:
- @Configuration:定义配置类
- @ModeAttribute:将参数和返回值绑定到Model中
- @SessionAttribute:设置在Model中的属性名称
- @Valid:校验数据
- @CookieValue:用来获取Cokkie中的值
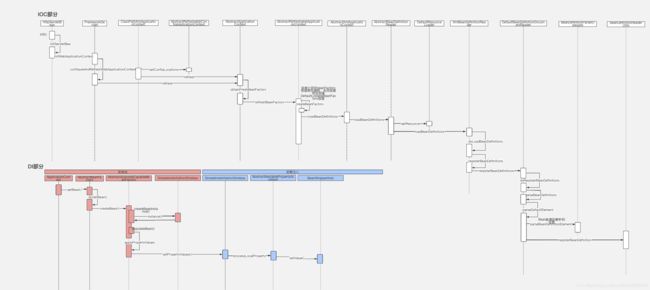
Spring IOC
IOC容器初始化时序图:
Spring Bean 作用域
- Bean的五中作用域:singleton(单例)、prototype(原型)、request(请求)、session(会话)、global session(全局会话)
- singleton:(默认)每一个Spring IoC容器都拥有唯一的一个实例对象,该模式在多线程下是不安全的。
- prototype:每次通过 Spring 容器获取 prototype 定义的 bean 时,容器都将创建一个新的 Bean 实例,每个 Bean 实例都有自己的属性和状态,而 singleton 全局只有一个对象。根据经验,对有状态的bean使用prototype作用域,而对无状态的bean使用singleton作用域。
- request:每个HTTP请求会产生一个Bean对象,Http 请求结束,该 bean实例也将会被销毁。只在基于web的SpringApplicationContext中可用。
- session:限定一个Bean的作用域为HTTPsession的生命周期,session结束bean销毁,只有基于web的Spring ApplicationContext才能使用
- global Session:限定一个Bean的作用域为全局HTTPSession的生命周期,只有基于web的SpringApplicationContext可用
Spring Bean 生命周期
- Spring Bean的生命周期分为四个阶段和多个扩展点。扩展点又可以分为影响多个Bean和影响单个Bean
- 四个阶段
实例化 Instantiation:createBeanInstance()
属性赋值 Populate:populateBean()
初始化 Initialization:initializeBean()
销毁 Destruction:至于销毁,是在容器关闭时调用的,详见ConfigurableApplicationContext#close() - 多个扩展点
生命周期:InitializingBean、DisposableBean
影响多个Bean:BeanPostProcessor、InstantiationAwareBeanPostProcessor
影响单个Bean:
Aware Group1:BeanNameAware、BeanClassLoaderAware、BeanFactoryAware
Aware Group2:EnvironmentAware、EmbeddedValueResolverAware、ApplicationContextAware(ResourceLoaderAware\ApplicationEventPublisherAware\MessageSourceAware)
Spring 依赖注入四种方式
- 构造器注入、setter 方法注入、静态工厂注入、实例工厂