本文为原创文章, 同时发布到本人的私人博客 http://www.caipiao365.vip/article/11
csdn: http://blog.csdn.net/canye/article/details/79535961
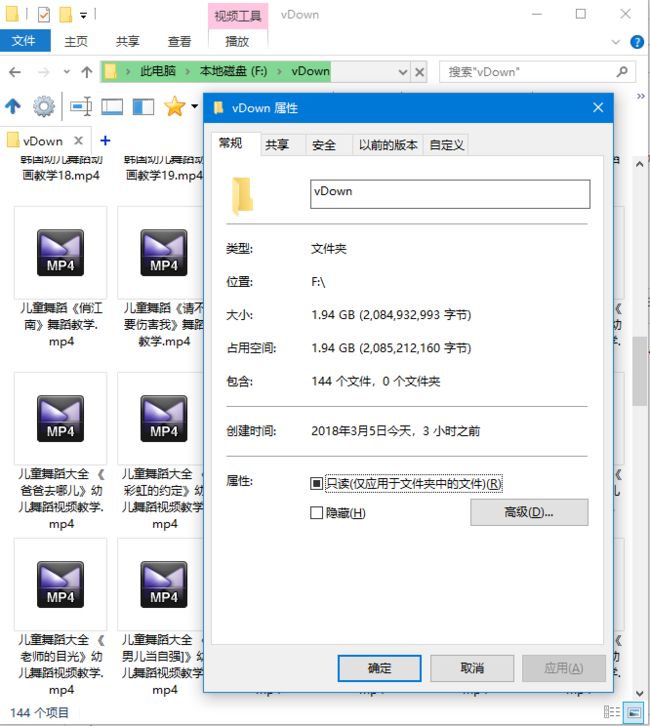
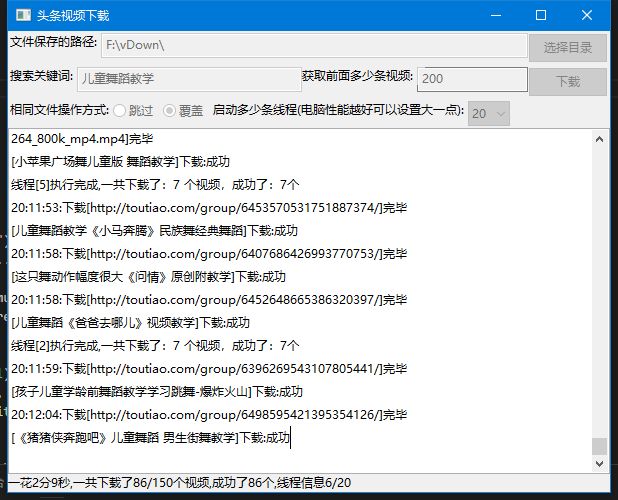
孩子特喜欢跳舞,以前下的视频看了好次了.想换短一点的新一点的视频.做为一个10多年的码农.是不可能手动一个个文件去下载的.当然想要一个方便的方法去下载自己想要的视频了.所以就想到了python.因为python在这方面有天生的优势.好了废话不多说先上几张图片看看效果.
下面言归正传来谈谈具体的细节。
第一步 我们打开https://www.toutiao.com/搜素关键词 如 儿童舞蹈
第二步 打开 开发者工具 把搜索结果页面移动到 最下面 就会看到有 ?offset=20&format=json......这样的连接 如下图片
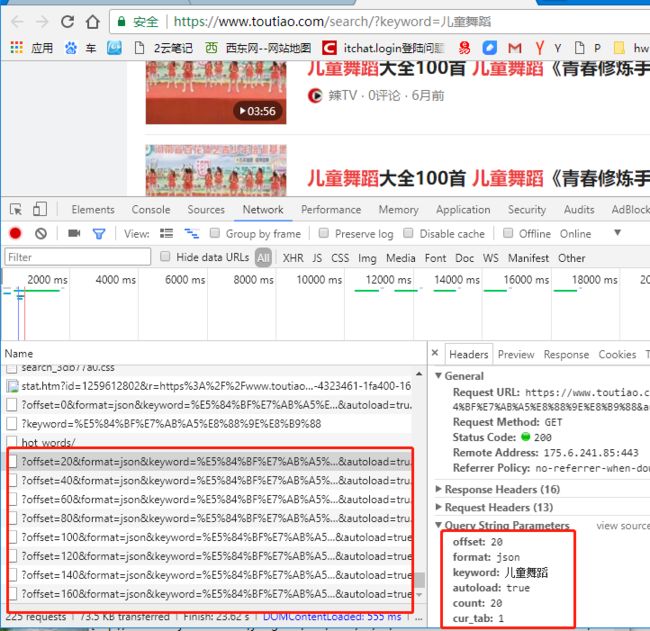
通过分析发现 这个连接是用来异步获取搜索结果的具体参数如说明如下:
"offset": nPages, #记录的开始数字 0开始 0 20 40 60 具体见 count 字段 默认是每页有20条记录但是每面多多少少有些广告
"format": "json", #返回的数据类型
"keyword": serchStr, #要搜索的关键词
"autoload": "true", #html网页获取记录后是否自动显示的页面里
"count": "20", #每次请求返回的记录大小(建议和前台的页面保持一致) 我设置其他的,他们的的服务器也只每次返回20条记录
"cur_tab": "2", #前面页面的标签(可以用2不用管他 和前台的页面保持一致)
"from": "search_tab", #提交搜索的前面页面的表单名(不用管他就用这个 也就是cur_tab 2)
"callback": JSARRNAME #Json数据返回后前台页面JS代码里数组的名字这个我改了一个 他的太长了点 看不习惯@_@
这个说明具体见 net\DownVideo.py里的 DownVideoMgr类的GetParas方法
然后在看一下这个连接返回的数据:
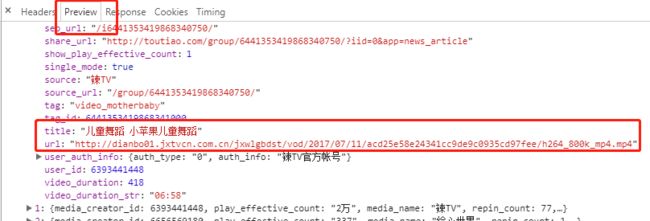
当时一看乐了,是mp4的地址,这不是非常非常简单吗.从网上用python下个文件就几行代码的事情.这样的话就非常快速的加上了下载文件的方法:
class VideoItem(object):
#视频的标题
title = ""
#视频的URL
url = ""
#初始化方法
# _title 视频的标题
# _url 视频的地址
def __init__(self, _title, _url):
self.title = _title
self.url = _url
class DownVideoMgr(object):
#根据url保存文件
#参数:
# url mp4文件的URL
# loactFile 本地保存的路径
#返回值:
# True 下载成功
# False 下载失败
def SaveUrl2File(self, url, loactFile):
bRet = True
try:
request = urllib2.Request(url, headers=headers)
response = urllib2.urlopen(request)
data = response.read()
with open(loactFile, "wb") as code:
code.write(data)
except Exception as e:
print e
bRet = False
return bRet
然后当时就想在写个写一个获取页面JSON返回的视频记录数据的方法然后就完成了.想到了就一鼓作气继续写了下面这几个方法:
#获取打开页面的结果
#参数:
# url 打开网页的地址
#返回值:
# 成功 打开页面的结果
# 失败 空字符串
def GetWebRet(self, url):
htmlStr = ""
try:
request = urllib2.Request(url, headers=headers)
response = urllib2.urlopen(request)
htmlStr = response.read()
except Exception as e:
print e
bRet = False
htmlStr = ""
return htmlStr
#获取搜索的结果
#参数:
# seachKey 搜索的关键词
# nPage 第几页
#返回值:
# 成功 搜索的JSON结果
# 失败 空字符串
def GetSeachRet(self, seachKey, nPage):
url = httpBase + self.GetParas(seachKey, nPage)
jsonStr = self.GetWebRet(url)
if (len(jsonStr) > 10):
jsonStr = jsonStr[len(JSARRNAME) + 1:-1]
return jsonStr
#根据KEY返回JSON对象的里值
# jsObj json对象
# key json对象的key
#参数:
# jsObj json对象
# key json对象的key
#返回值:
# 成功 要是KEY存在就返回对应的值
# 失败 要是KEY不存在返回空字符串
def GetJsonItemData(self, jsObj, key):
if jsObj.has_key(key):
return jsObj[key]
return ''
#根据JSON字符串获取视频记录信息
#参数:
# jsonStr json字符串
#返回值:
# VideoItem 列表
def GetVItem(self, jsonStr):
jsObj = json.loads(jsonStr)
itemsize = len(jsObj['data'])
videoList = []
for i in range(0, itemsize):
tmpJs = jsObj['data'][i]
#.decode('raw_unicode-escape').encode('utf-8')
title = u"" + self.GetJsonItemData(tmpJs, 'title')
url = u"" + self.GetJsonItemData(tmpJs, 'url')
if url.find("wukong.com/question") > 0:
url = ""
if len(title) > 0 and len(url) > 0 :
tItem = VideoItem(title, url)
videoList.append(tItem);
return videoList
#获取搜索的结果
#参数:
# seachKey 搜索的关键词
# nStart 从第几条记录开始获取
#返回值:
# VideoItem 列表
def GetVideoItem(self, seachKey, nStart):
jsonStr = self.GetSeachRet(seachKey, nStart)
return self.GetVItem(jsonStr)
写到这里心里想现在就差一个主方法了,然后开打电脑放这里让他自动下载.我可以关闭显示器睡觉去了.当时想想就心里乐开了.马上加了个非常简单的方法如:
#根据VideoItem下载视频
#参数:
# vItem 流媒体信息
# 可以通过 GetVideoItem 方法获取
#返回值:
# True 下载成功
# False 下载失败
def DownVideoItem(self, vItem):
fileSavePaht = self.sBaseFilePath + vItem.title.encode("gbk") + ".mp4"
if os.path.exists(fileSavePaht):
if self.isFileOver:
try:
os.remove(fileSavePaht)
except Exception as e:
print e
return False
else:
return True
return self.SaveUrl2File(vItem.url, fileSavePaht)
def Test():
DowObj = DownVideoMgr()
keyS = "儿童舞蹈教学"
vArrList = []
for i in range(0, 201, 20):
vItem = DowObj.GetVideoItem(keyS, i)
for r in vItem :
vArrList.append(r)
for r in vArrList :
DowObj.DownVideoItem(r)
if __name__ == '__main__':
Test()
写到这里然后高高兴兴的打开cmd 执行了 python xxxx.py 结果才发现是我高兴的太早了 以mp4结尾的文件有,但是更多的是流媒体格式的.
如:
title:"儿童舞蹈《爵士girl》"
url:"http://toutiao.com/group/6528510675289899527/"
然后打开下面这个url 一看视频是可以播放的.继续按F12 有video标签如 下图片:
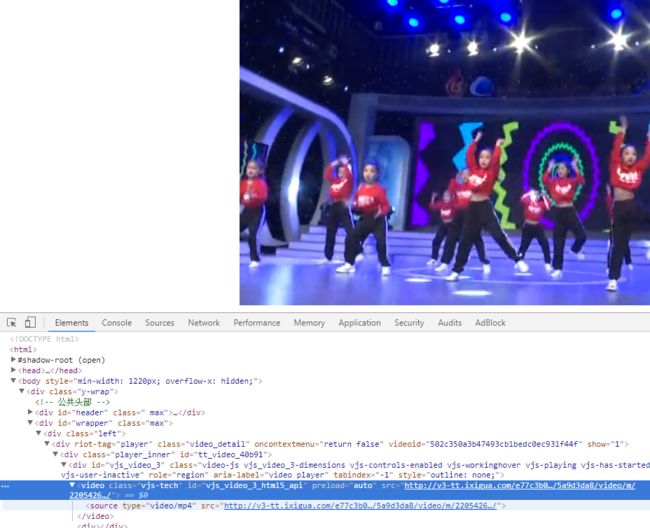
里面有src属性,打开这个src属性一看是流媒体的地址,用这个地址可以用上面的SaveUrl2File 方法下载.一看又来劲了(当时的心情比吃NNN条 士**架 还有劲)
这样是不是打开 打开前面获取里的 http://toutiao.com/group/6528510675289899527/ 这个URL页面就可以获取到这个 video 标签里的属性吗? 不就是在加一个流程的事情吗,easy.
GetWebRet 这个方法上面早就写好了 我就直接用就可了.
然后写了个小测试程序如下:
dObj = DownVideoMgr()
htmlStr = dObj.GetWebRet("http://toutiao.com/group/6528510675289899527/")
nStart = htmlStr.find("video")
print nStart
结果一运行 输出-1 我以为夜深了我眼睛太累了就搽了一下眼睛检查了几次代码在执行,结果死活还是-1.我想这不是我程序的问题吧.应该是那个页面的问题,这个video标签应该是JS动态生成的.然后就打开那个页面点右键查看源码.
果然是JS动态生成的.想算了.懒得分析JS了.但是又想一下前面写了这么多,费了这么多时间和精力现在放弃对不起孩子渴望看舞蹈视频的那种眼神.然后就继续分析这个页面和里面的JS代码加引用的JS文件.然后在眼睛上抹了几次的清凉油的结果下终于找到下面这一段JS,在http://s3.pstatp.com/tt_player/player/tt2-player.js这个脚本文件里(注JS给我格式化了.原页面里的JS压缩了没有换行):+
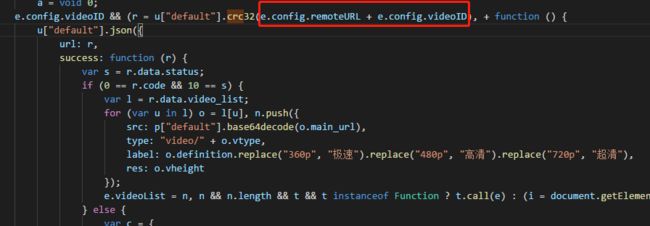
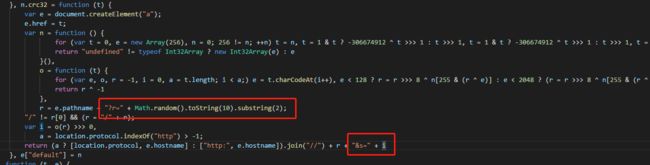
分析这段JS源码后加了下面几个方法和修改了部分方法
#根据流媒体的网页地址获取流媒体的srcID
#参数:
# url 流媒体的网页地址
#返回值:
# True 返回流媒体的src
# False 返回空字符串
def GetStreamingVideoID(self, url):
htmlStr = self.GetWebRet(url)
if len(htmlStr) < 5:
return "";
strID = ""
strFindSrart = "videoid"
nStart = htmlStr.find(strFindSrart)
nEnd = -1
if nStart > 0:
nEnd = htmlStr.find(",", nStart)
if nEnd > 10:
strID = htmlStr[nStart+len(strFindSrart)+2 : nEnd-1]
return strID
#获取随机数
#参数: 无
#返回值:
# 随机数字符串
def GetRandPara(self):
randStr = bytes(random.random()) [2:]
return randStr
#获取CRC检验右移的值
#参数:
# val 右移的值
# n 右移的值的位数
#返回值:
# 右移动的结果
def GetCrcValue(self, val, n):
return val >> n if val >= 0 else (val + 0x100000000) >> n
#根据视频的ID获取真实播放地址的API地址
#参数:
# vID 流媒体的ID
# vID 可以通过 GetStreamingVideoID 这个方法获取
#返回值:
# 获取真实播放地址的API地址
def GetStreamAPIUrl(self, vID):
r = self.GetRandPara()
jsUrl = 'http://i.snssdk.com/video/urls/v/1/toutiao/mp4/%s' % vID
n = urlparse.urlparse(jsUrl).path + '?r=' + r
c = binascii.crc32(n)
s = self.GetCrcValue(c, 0)
return jsUrl + '?r=' + r + '&s=' + bytes(s)
# 获取真实播放地址的API获取真实的流媒体播放地址
#参数:
# url 流媒体的获取API的地址
# url 可以通过 GetStreamAPIUrl 这个方法获取
#返回值:
# True 流媒体真实地址
# False 空字符串
def GetStreamSrc(self, url):
vID = self.GetStreamingVideoID(url)
src = self.GetStreamAPIUrl(vID)
jsonStr = self.GetWebRet(src)
vUrl = ""
strFindSrart = "main_url"
nStart = jsonStr.find(strFindSrart)
nEnd = -1
if nStart > 0:
nEnd = jsonStr.find(",", nStart)
if nEnd > 10:
vUrl = jsonStr[nStart+len(strFindSrart)+2 : nEnd-1]
videourl = base64.b64decode(vUrl)
return videourl
#根据流媒体的地址下载流媒体文件
#参数:
# url 流媒体的Src地址
# file 本地保存的路径
#返回值:
# True 下载成功
# False 下载失败
def DownStreamVideo(self, url, file):
videoUrl = self.GetStreamSrc(url)
return self.SaveUrl2File(videoUrl, file)
#根据VideoItem下载视频
#参数:
# vItem 流媒体信息
# 可以通过 GetVideoItem 方法获取
#返回值:
# True 下载成功
# False 下载失败
def DownVideoItem(self, vItem):
fileSavePaht = self.sBaseFilePath + vItem.title.encode("gbk") + ".mp4"
if os.path.exists(fileSavePaht):
if self.isFileOver:
try:
os.remove(fileSavePaht)
except Exception as e:
print e
return False
else:
return True
if vItem.IsMp4():
return self.SaveUrl2File(vItem.url, fileSavePaht)
else:
return self.DownStreamVideo(vItem.url, fileSavePaht)
到里步了 采集的功能基本上完成了,但是想到要是有个界面可以给我父母也可以找一些视频下载下来给我孩子看也是件美事(考虑到我这个民工不在家的时候,下载的视频孩子看厌烦了要换新的)
然后就用wx做了个简单的界面
就是上面的图片里的界面
还有一些没有讲的很详细,麻烦请看代码,源码里有详细的注释.要是还有没有讲明白的地方麻烦给我留言
详细源码见:gitee