第15章 因子变量
数据准备Creating factors现在你可以创建一个因子General Social SurveyModifying factor orderModifying factor levels
数据准备
要处理因子,我们将使用forcats包,它提供处理分类变量的工具(它是一个因子的组合)
它为处理因子提供了广泛的帮助。
forcats不是核心tidyverse的一部分,所以我们需要加载它
library(tidyverse)
library(forcats)
Creating factors
假设有一个记录月份的变量
x1 <- c("Dec", "Apr", "Jan", "Mar")
使用字符串记录这个变量有两个问题
1 因为有12个月,可能让你打字错误
2 它没有一个有用的分类方法
你可以用因子来解决这两个问题。要创建一个因素,你必须首先创建一个有效水平的列表:
month_levels <- c( "Jan", "Feb", "Mar", "Apr", "May", "Jun", "Jul", "Aug", "Sep", "Oct", "Nov", "Dec")
现在你可以创建一个因子
y1 <- factor(x1, levels = month_levels)
y1#> [1] Dec Apr Jan Mar#> Levels: Jan Feb Mar Apr May Jun Jul Aug Sep Oct Nov Dec
sort(y1)#> [1] Jan Mar Apr Dec#> Levels: Jan Feb Mar Apr May Jun Jul Aug Sep Oct Nov Dec
And any values not in the set will be silently converted to NA:
有时您希望级别的顺序与数据中第一次出现的顺序相匹配。在创建因子时,您可以将级别设置为unique(x),或者在事实发生后,使用fct_inorder():
f1 <- factor(x1, levels = unique(x1))
f1#> [1] Dec Apr Jan Mar#> Levels: Dec Apr Jan Mar
f2 <- x1 %>%
factor() %>%
fct_inorder()
f2#> [1] Dec Apr Jan Mar#> Levels: Dec Apr Jan Mar
General Social Survey
在本节的其余部分,我们将集中讨论forcats::gss_cat。这是芝加哥大学(University of Chicago)独立研究机构NORC长期在美国进行的一项调查。该调查有数千个问题,所以在gss_cat中,我选择了一些问题,它们将说明在处理因子时将遇到的一些常见问题
Modifying factor order
在可视化中改变因子水平的顺序通常是有用的。例如,假设你想探究不同宗教每天看电视的平均时间
relig_summary <- gss_cat %>%
group_by(relig) %>%
summarise( age = mean(age, na.rm = TRUE), tvhours = mean(tvhours, na.rm = TRUE), n = n() )
ggplot(relig_summary, aes(tvhours, relig)) + geom_point()

很难解释这个图,因为没有整体的模式。我们可以通过使用fct_reorder()重新排序relig的级别来改进它。fct_reorder()主要接受两个参数:
f 即您希望修改其级别的因子。
x 一个你想用来重新排序的数字向量。
ggplot(relig_summary, aes(tvhours, fct_reorder(relig, tvhours))) + geom_point()
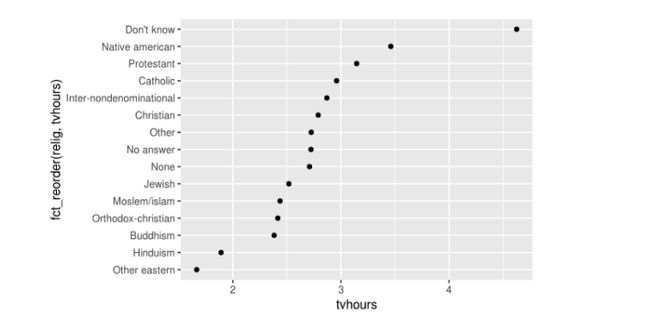
对宗教的重新排序让我们更容易看到不了解这一类别的人看更多的电视,而印度教和其他东方宗教的人看得更少
Modifying factor levels
比改变级别的顺序更强大的是改变它们的值。最通用和最强大的工具是fct_recode()。它允许您重新编码或更改每个级别的值
例如下面,水平是简洁但是不一致的。让我们调整它们的长度,并使用一个并行结构
gss_cat %>%
mutate(partyid = fct_recode(partyid, "Republican, strong" = "Strong republican", "Republican, weak" = "Not str republican", "Independent, near rep" = "Ind,near rep", "Independent, near dem" = "Ind,near dem", "Democrat, weak" = "Not str democrat", "Democrat, strong" = "Strong democrat" )) %>%
count(partyid)#> # A tibble: 10 x 2#> partyid n#> #> 1 No answer 154#> 2 Don't know 1#> 3 Other party 393#> 4 Republican, strong 2314#> 5 Republican, weak 3032#> 6 Independent, near rep 1791#> # ... with 4 more rows
要合并组,可以将多个旧级别分配到相同的新级别
gss_cat %>%
mutate(partyid = fct_recode(partyid, "Republican, strong" = "Strong republican", "Republican, weak" = "Not str republican", "Independent, near rep" = "Ind,near rep", "Independent, near dem" = "Ind,near dem", "Democrat, weak" = "Not str democrat", "Democrat, strong" = "Strong democrat", "Other" = "No answer", "Other" = "Don't know", "Other" = "Other party" ))
%>% count(partyid)
#> # A tibble: 8 x 2#> partyid n#> #> 1 Other 548#> 2 Republican, strong 2314#> 3 Republican, weak 3032#> 4 Independent, near rep 1791#> 5 Independent 4119#> 6 Independent, near dem 2499#> # ... with 2 more rows
有时你只是想把所有的小组放在一起,使情节或表格更简单。这就是fct_lump()的工作
默认行为是逐步将最小的组聚集在一起,确保聚合仍然是最小的组。
相反,我们可以使用n参数来指定要保留的组(不包括其他组)。
gss_cat %>%
mutate(relig = fct_lump(relig, n = 10)) %>%
count(relig, sort = TRUE) %>%
print(n = Inf)
#> # A tibble: 10 x 2#> relig n#>
#> 1 Protestant
10846#> 2 Catholic
5124#> 3 None 3523#> 4 Christian 689#> 5 Other 458#> 6 Jewish 388#> 7 Buddhism 147#> 8 Inter-nondenominational 109#> 9 Moslem/islam 104#> 10 Orthodox-christian 95