What is Object Detection?
谈起Object Detection,必然要说到他与Classification的区别。我在Quora上看到的一个很直观的答案:
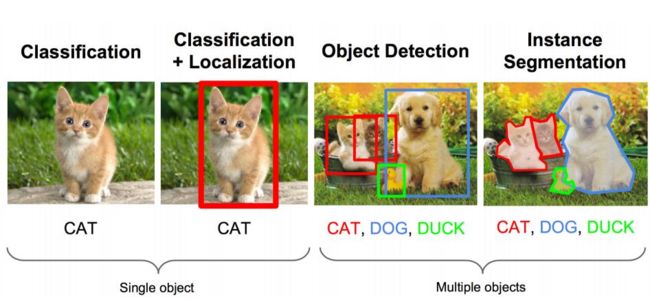
Object Detection = Localization + Classification
Classification是通过一张图片的特征量来判断图像是否包含了某种物体。Object Detection则是检测一张图中某种(某些)物品可能存在的位置。
Algorithm

有兴趣的话可以了解一下Object Detection的发展史。从R-CNN横空出世开始经历了百花齐放的变革。
Tensorflow Models
Tensorflow提供了一系列预训练好的模型使用。现在普遍使用的算法是YOLO,Faster-RCNN以及Mobilenet等等。考虑到实时检测对速度的需求,以及转换到其他平台可使用的模型的可能性,我在这里将选择使用SSDMobilenet。
Get Started
模型选好了,就可以开始进行训练的准备工作了。
Environment Setting
搭环境什么的最讨厌了。(小声BB)
如果还没有安装object detection模块,可以参照这个链接来安装。需要注意的是tensorflow的版本需要大于1.12。
Data Preparation
通常一张图片在图像识别问题中会经历 原始图像->特征提取->分类 的过程。而数据工程是第一位。在命令你的模型学习数据之前,要根据情况做一些必要的预处理。
Tensorflow专用的训练数据格式是TFRecord。TFRecord实际上是一种二进制格式
Tensorflow对Object Detection训练数据做了如下要求;
An RGB image for the dataset encoded as jpeg or png.
A list of bounding boxes for the image. Each bounding box should contain:
A bounding box coordinates (with origin in top left corner) defined by 4 floating point numbers [ymin, xmin, ymax, xmax]. Note that we store the normalized coordinates (x / width, y / height) in the TFRecord dataset.
The class of the object in the bounding box.
这一次我选了一个Kitchen Object的dataset。这原本是用Depth Camera拍摄的图像数据集,由视频分解成9个scenes,主要包含了11个厨房常见物品的box信息。我选择只用他的RGB图像信息以及boxes信息来训练自己的模型。
打开README看一下,这个数据集采用了和VOC2007/VOC2012一样的存储格式,也就是Annotation以xml树状文件来保存。让我随便打开一个xml文件看看里面什么样子吧!
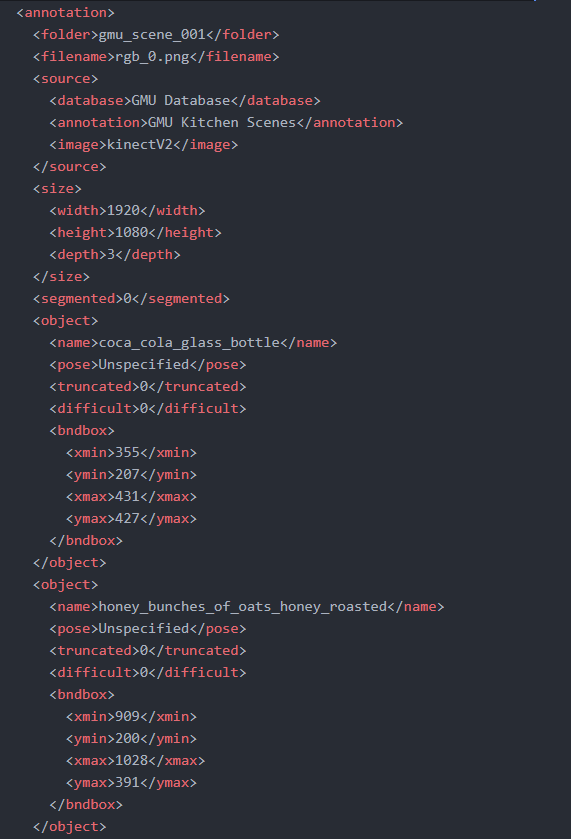
这里就包含了我需要用来训练的信息啦。plot一下,看起来没什么问题。(xmin,ymin),(xmax,ymax)也就是物体box左上角和右下角的坐标点。所以接下来就将他们转换成Tensorflow专用的TFrecord格式。
这里可以参照官网的指南:https://github.com/tensorflow/models/blob/master/research/object_detection/g3doc/using_your_own_dataset.md
简而言之就是TFRecord是一个二进制文件,可以将每一个图片文件名特征信息目标边框种类统统打包成一个example来存储管理在一起然后feed给你需要训练的tensorflow模型。
然而可能是我不够细心或者智商不行,老是卡在很小但是很头疼的地方。官方给出的例子只给出了一张图片有一个检测物体的例子,多目标检测的方式并没有给出。只给了一句话让我有些线索:A list of bounding boxes for the image.
也就是说同一张图片的每一条object的每种信息都保存在一个list里面,无论是一个还是10个。可以参照这个浣熊detection的主页。先将xml文件转换成csv,再从csv中读取每条信息并处理转换成tfrecord文件。
这样tfrecord文件就生成好了。在开始训练之前,除了tfrecord之外,还需要创建一个pbtxt文件来保存label信息。比如说我有一个classlist的list,大概长这个样子
['coca_cola_glass_bottle', 'honey_bunches_of_oats_honey_roasted', 'nature_valley_soft_baked_oatmeal_squares_cinnamon_brown_sugar', 'nature_valley_sweet_and_salty_nut_almond', 'pringles_bbq', 'red_bull', 'pop_secret_light_butter', 'palmolive_orange', 'coffee_mate_french_vanilla', 'hunts_sauce', 'mahatma_rice']
pbtxt文件要求将这个文件保存成这样。。
item {
id: 1
name: "coca_cola_glass_bottle"
}
item {
id: 2
name: "honey_bunches_of_oats_honey_roasted"
}
写起来嫌麻烦可以用下面的代码
print('Converting class file to labelmap file:')
with open('labelmap.pbtxt', mode='w') as f:
count = 1
for name in classes_list:
f.write('item {\n')
if count == 0:
f.write(' name: "none_of_the_above"\n')
f.write(' label: 0\n')
f.write('}\n')
else:
f.write(' id: '+ str(count)+'\n')
f.write(' name: "'+classes_list[count-1]+'"\n')
f.write('}\n')
count = count + 1
print('Saved labelmap file: labelmap.ptorotxt')
生成好了pbtxt文件之后,还需要一个一个model的config文件,去samples里面找到ssd_mobilenet_v1_coco.config,复制到与pbtxt相同目录下。 需要进行一下小小的修改,这个文件包含了我们训练数据的路径以及对训练器的配置。fine_tune_checkpoint 这个参数,把引号里面的删除掉(变成这样->fine_tune_checkpoint: "")。 里面的input_path都改成自己保存tfrecord的路径,label_map_path改成pbtxt文件的路径。
保存!
Training!
可以开始训练啦。用object_detection目录下的model_main.py文件进行训练,option写上各种自己的地址就可以啦!
python model_main.py --pipeline_config_path=data\ssd_mobilenet_v1_coco.config --model_dir=data\training --num_train_steps=30000
大概就是这样,回车!
下周回来看结果咯~