人工智能有两大分支,一支是机器学习,一支叫深度学习,目前后者占据人工智能技术的主流,当前流行的ZAO换脸应用,自动驾驶,人脸识别使用的都是后者。深度学习主要用于模仿人的认知能力,它的特长在于处理非机构化数据。
以前计算机算法主要用来处理结构化数据,例如链表,二叉树,堆栈等,这些数据结构依靠固定规则构建,但图片,人脸,声音,文章这些数据则无法找到对应的构建规则,例如你无法使用语言去描述一张人脸,使得别人看到你的描述就如同看到真实的人脸一样,我们知道这些对象存在某种形成规则,但无法使用逻辑将这些规则表达出来,这些领域则是神经网络发挥威力的地方。
神经网络是一种层级化的结构,每一层包含了很多个数值变量,数据每经过一层时就与该层含有的变量进行相应运算,运算的结果输出给下一层进行处理,神经网络的基本结构如下图:
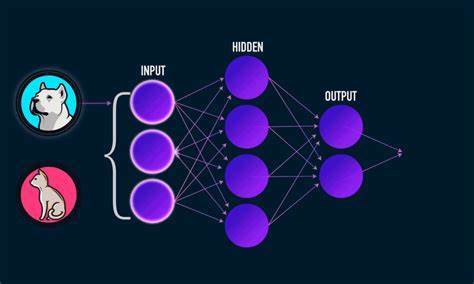
每层包含多个节点,上一层节点与下一层节点间以特定方式进行连接,两个节点连接路径上有对应参数,数据经过路径从一个节点传递到下一个节点时,需要与路径上的参数做运算,数据从输入层进入网络,经过层层处理后在输出层输出给定结果,例如要判断图片中动物是猫还是狗,我们只要把图片数据从输入层输入,在网络尾部会输出一个结果,如果结果为0就表示图片是狗,结果为1表示图片中内容是猫。
数据从每层节点出来时,需要经过特定运算,这些特定运算也叫“激活函数”,通常有三种运算比较常用,他们对于的汗水图形如下:
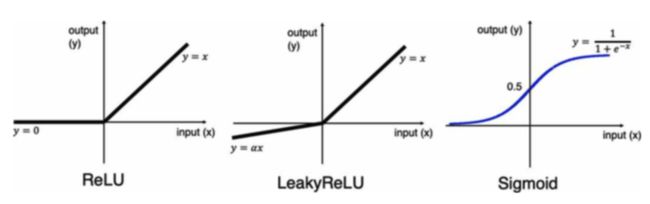
第一个函数表示,如果输入节点的数值大于0,那么就保持原样输出,如果小于0就输出0;第二个函数表示如果输入数值大于0,那就保持原样输出,如果小于0,那就是将它乘以一个常数后再输出;第三种对应的就是右上角函数所表示的运算。
网络的最后一层也就是输出层比较独特。如果我们网络只对输入数据做二元判断,例如判断输入图片是猫是狗,是男人还是女人,那么网络最后一层就可以只有一个节点,同时节点才有上图第三种运算,因为该运算输出的结果在[0,1]之间,我们可以根据运算结果是大于0.5还是小于0.5来判断图片内容属于那种情况,例如大于0.5表示图片内容是狗,小于0.5表示图片内容是猫。
如果网络任务是对输入数据进行多元判断,例如输入的图片可能对应十种不同物体,网络最后的输出层就可能包含10个节点,每个节点输出小于1的数值,用于表示输入图片属于对应种类物体的概率,这些数值加总得1,由此输出层节点对应运算如下:
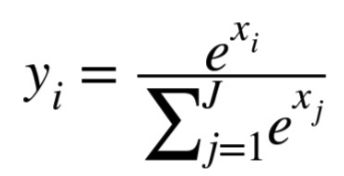
其中x(i)表示输出层第i个节点接收的输入数据,节点将接收的数据根据常数e做对数运算,然后将其结果除以所有节点运算输出结果之和,就是节点的输出结果也就是y(i),不难发现如果输出层有n个节点,那么y(1)+...+y(n)=1.
接下来我们看网络如何提升输出结果的准确性。例如网络用于判断输入图片是猫还是狗,如果图片内容是狗,当网络最后输出结果小于0.5,此时我们如何让网络调整使得当输入图片是狗时,网络输出层输出结果大于0.5呢。这就需要对网络进行“训练”,这里我们需要引入“损失函数”的概念,我们想象网络接收输入数据后输出一个或若干个结果,于是网络本质上就是一个函数。
网络的输出结果与输入数据对应的结果之间的差距叫做误差。例如我们用1来代表狗图片,如果网络最终输出结果为0.4,那么误差就是1-0.4=0.6,我们的目标是调整网络节点连接链路上的参数,使得网络输出结果对应正确结果的误差越来越小。
为了方便,我们都是将多次输入产生的结果误差加总起来,例如我们一次对网络输入n张对应猫和狗的图片,然后获得n个最终结果,我们把n个最终结果对应的误差加总起来作为一次训练过程的误差,为了实现更好的计算,我们不会简单的将网络输出结果与正确结果做差值,而是将网络输出结果与正确结果构造出某种专门函数,也就是前面描述的“损失函数”,如果网络面对的是二元分类,也就是对输入数据做两种可能性判断,那么损失函数如下:
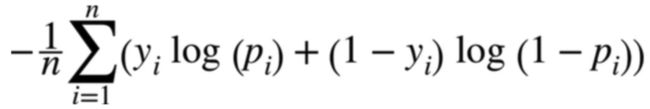
上面函数叫“交叉熵”,其中n对应输入的数据数量,p(i)是第i章图片输入网络后获得的结果,y(i)是图片对应的正确结果,我们的目标是调整网络中节点连接链路上的参数,使得上面公式计算结果尽可能的小。损失函数不止一种形式,另外一种常用形式如下:
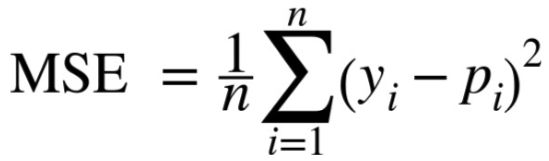
y(i)是网络对输入的第i个数据给出的结果,p(i)是第i个数据对应的结果,MSE对应最小差方和,上面公式计算出来的结果越小,网络对输入数据判断的结果就越准确。
如果我们把网络看做是一个函数f,输入数据看做x,输出结果就是y=f(x),我们把f(x)带入到上面公式中,于是让上面描述的损失函数结果变小,实际上是调整函数f(x)内部结构,使得它的输出更多的与正确结果p(i)相契合,这种调整就是所谓的模型训练过程。
学过高数,了解微积分的同学会知道,要让一个函数取最小值或最大值,我们只要在某一特定点对函数求导,如果结果为0,那么当前点就可能是函数的极值点,如果求导结果大于0,表明在当前点函数是递增的,因此要让函数值变小就要适当的减少当前点对应的值,如果求导结果小于0,说明函数在当前点递减,如果要让函数结果继续减少,我们可以适当增加当前点的值,深度学习的模型训练过程其实就是通过求导运算,不断改变网络内部参数,让损失函数计算结果尽可能降低的过程。
这里我仅是非常简单的介绍神经网络运行原理,我有专门课程非常详细的讲解神经网络内部运行机制,有兴趣的同学可以通过如下链接获取课程:
神经网络原理深入讲解,请点击本链接
接下来我们看一个神经网络实例,我们将拿到一堆图片,图片对应10种不同类型的物体,我们将构造一个网络识别图片中物体对应哪一种类别,示例代码如下
import numpy as np
from keras.utils import to_categorical
from keras.datasets import cifar10
'''
将加载数据分成两部分,一部分用于训练,一部分用于测试模型效果
'''
(x_train, y_train), (x_test, y_test) = cifar10.load_data()#加载图片数据
NUM_CLASSES = 10 #图片分为10个类别
x_train = x_train.astype('float32') / 255.0 #将像素点的值转换为[0,1]之间
x_test = x_test.astype('float') / 255.0
'''
将类别转换为向量,如果有10个类别,那么向量就包含10个元素,假设某个图片属于类别3
那么它对应的向量就是第三个元素设置为1,其他元素设置为0
'''
y_train = to_categorical(y_train, NUM_CLASSES)
x_test = to_categorical(y_test, NUM_CLASSES)
上面代码用于将数据加载到内存,并对数据做一些预处理,当网络用于处理图片数据时,我们需要将图片对应像素点转换到[0,1]之间,这样才有利于提高网络的判断准确率,上面代码中我们加载的数据集大概内容如下:

接下来我们构建网络识别图片中物体的类别,代码如下:
from keras.models import Models
from keras.layers import Input, Flatten, Dense
#输入层接收图片,图片规格为32*32,每个像素点对应RGB3个值
input_layer = Input(shape=(32, 32, 3))
#将图片由二维压缩为一维
x = Flatten()(input_layer)
#增加含有200个节点的全连接层
x = Dense(units = 200, activation = 'relu')(x)
#增加含有150个节点的全连接层
x = Dense(units = 150, activation = 'relu')(x)
#输出层有10个节点对应图片十种分类
output_layer = Dense(units = 10, activation = 'softmax')(x)
model = Model(input_layer, output_layer)
上面代码完成的模型,其结构与最开始的图片显示差不多,接下来我们把图片输入网络,然后训练网络让其输出结果与图片对应的正确结果尽可能的贴近,相应实现如下:
from keras.optimizers import Adam
'''
设置模型的优化方式,本质上是通过求导获取损失函数最小值,Adam对应求导计算的某种特别方法,本质上还是求导运算
categorical_crossentropy对应我们前面提到的交叉熵
'''
opt = Adam(lr = 0.0005)
model.compile(loss = 'categorical_crossentropy', optimizer = opt, metrics = ['accuracy'])
#调整模型内部参数,让它的输出与正确输出越来越对应
'''
x_train对应输入图片,y_train对应图片中物体类别,batch_size表示网络识别给定数量图片后将识别结果加总,
epochs表示网络反复进行给定优化次数,shuffle表示把图片的顺序随机打乱后再输入网络
'''
model.fit(x_train, y_train, batch_size = 32, epochs = 10, shuffle = True)
上面代码运行后输出结果如下:
Epoch 1/10
50000/50000 [==============================] - 8s 151us/step - loss: 1.8446 - acc: 0.3356
Epoch 2/10
50000/50000 [==============================] - 7s 143us/step - loss: 1.6625 - acc: 0.4078
Epoch 3/10
50000/50000 [==============================] - 7s 148us/step - loss: 1.5855 - acc: 0.4363
Epoch 4/10
50000/50000 [==============================] - 8s 155us/step - loss: 1.5296 - acc: 0.4556
Epoch 5/10
50000/50000 [==============================] - 8s 158us/step - loss: 1.4970 - acc: 0.4663
Epoch 6/10
50000/50000 [==============================] - 8s 159us/step - loss: 1.4615 - acc: 0.4775
Epoch 7/10
50000/50000 [==============================] - 8s 160us/step - loss: 1.4403 - acc: 0.4842
Epoch 8/10
50000/50000 [==============================] - 8s 165us/step - loss: 1.4127 - acc: 0.4957
Epoch 9/10
50000/50000 [==============================] - 9s 174us/step - loss: 1.3857 - acc: 0.5050
Epoch 10/10
50000/50000 [==============================] - 9s 180us/step - loss: 1.3660 - acc: 0.5159
这意味着网络经过10次反复训练后,对输入图片类型的判断结果正确率是51%左右,这个结果表明网络对图片内容的判断成功率不错,因为图片有10种类型,如果随机对图片进行判断,那么正确率应该只有10%,然而我们的网络能达到51%的正确率说明网络的确具备一定的图片识别能力。
在下一节我们将引入识别率更高的卷积网络以提升网络对图片识别的准确率。
请关注公众号,让我们共同学习进步

更详细的讲解和代码调试演示过程,请点击链接