Pytest框架详解(二)
Pytest框架详解(二)
文章目录
- Pytest框架详解(二)
-
- 一、引言
- 二、参数化
-
- 列表嵌套元组
- 三、标记
-
- 3.1显式指定
- 3.2模糊匹配
- 3.3pytest.mark
- 四、配置文件
- 五、依赖
- 六、结语
一、引言
在上一篇《Pytest框架详解(一)》中,我们讲解了Pytest从安装到入门,以及一些基础的用法,比如代码调用,命令行参数,初始化与清除机制。
今天,我们来学一些更为强大的功能。
还是把官方文档给大家贴出来,在使用过程中,有任何问题,以官方文档为准哦~~~
点击前往-官方英文文档
点击前往-中文文档
二、参数化
我们知道,现在做自动化测试,无论哪个框架,工具,必不可少需要解决的一个问题就是参数化!也就是数据驱动(DDT)。
首先,参数化,可以大大提高我们编写用例的效率。并且可以集中的管理测试数据。
比如登录场景,需要编写测试用例,最基本的,可以编写以下4条用例:
- 用户名正确,密码正确
- 用户名正确,密码错误
- 用户名错误,密码正确
- 用户名错误,密码错误
实际操作中,我们使用pytest,可以非常简便的实现各种形式的数据(列表、元祖、字典)。
列表嵌套元组
个人使用较多的情况是列表中嵌套元组的形式进行参数化。这样对于数据比较直观。其实包括Excel、CSV等数据源形式,都是可以通过读取,形成想要的数据。这里就不过多赘述了。
当我们数据量较少时,可以直接使用列表中嵌套元组进行参数化,列表中每一个元祖代表一组数据。当运行用例时,被
@pytest.mark.parametrize装饰器装饰的函数或方法,就会将每组数据代入用例,进行执行。
代码如下:
import pytest
# 准备列表形式测试数据
data = [
("Tom", "pwd123"),
("Jack", "pwd321")
]
class TestLogin:
@pytest.mark.parametrize("username,password", data)
def test_login(self, username, password):
# 具体登录逻辑就不写了,直接打印出来吧
print("\n用户名是:", username)
print("密 码是:", password)
if __name__ == '__main__':
pytest.main(["-s", "-v"])
先解释下,@pytest.mark.parametrize这是python中的装饰器用法。
装饰器后面()的参数,第一个是字符串形式的"变量1,变量2…",第二个是数据源。上述代码中,就写成了@pytest.mark.parametrize("username,password", data)这样。
在执行用例时,就会将"Tom", "pwd123"带入用例执行一次,再将("Jack", "pwd321")代入再执行一次。
结果如下:
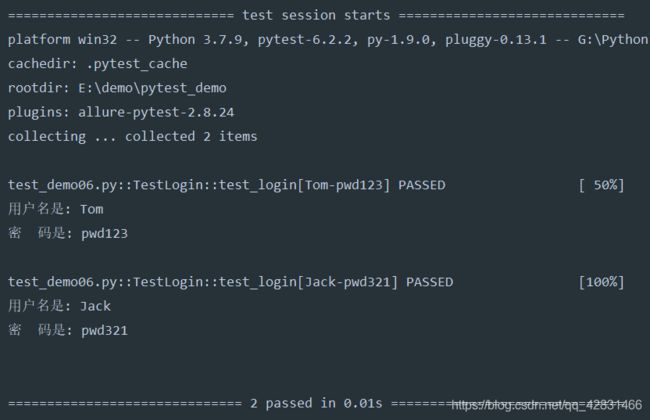
三、标记
标记呢,就是可以标记哪些用例执行,哪些用例不执行。
可以通过以下三种方法来细粒度的管理用例的执行。
3.1显式指定
test_no_mark.py::test_func1
# content of test_demo08.py
import pytest
def test1():
print("test1")
def test2():
print("test2")
我们在命令行中输入pytest test_demo08.py::test1,结果如下
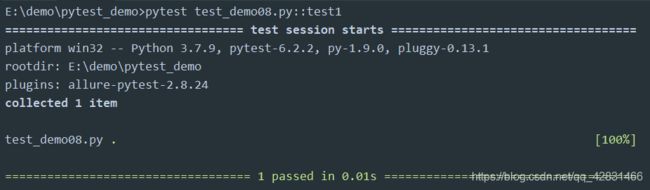
这样就只会去执行test1这个测试用例了。
3.2模糊匹配
pytest -k func1 test_no_mark.py
这个-k参数,指定的就是他后面的字符,做模糊查询,只要是包含这些字符的就会执行。
# content of test_demo08.py
import pytest
def test_reg():
print("test_reg")
def test_add():
print("test_add")
执行结果如下:
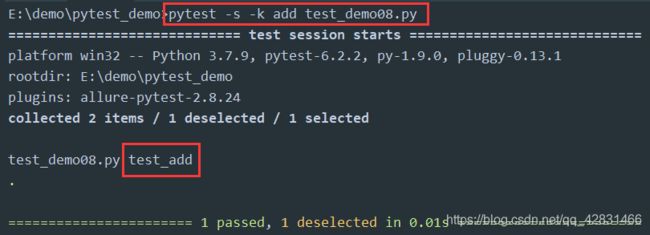
可以看到,只有test_add正常执行了。
需要提到的是,-k所指定查询的字符,不止是文件名,@pytest.mark.slow的slow也可以被指定。比如:
import pytest
@pytest.mark.slow
def test01():
print("test01")
def test02():
print("test02")
if __name__ == '__main__':
pytest.main(["-s", "-v", "-k slow"])
直接执行下面的主函数,会发现,只执行了test01这一个用例
3.3pytest.mark
@pytest.mark
mark标记呢,需要先在配置文件中注册自定义标记。如果不做这一步,会有warning提示。
在根目录或测试的文件夹中可以新建配置文件,这里我们使用pytest.ini
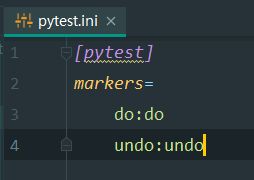
然后我们去编一个测试用例文件
# content of test_demo09.py
import pytest
@pytest.mark.do
def test01():
print("test01")
@pytest.mark.undo
def test02():
print("test02")
其中test01使用mark标记do,test02标记undo。
接着使用命令pytest -svm do test_demo09.py,结果如下:

可以看到,test01被执行,test02未被选取。
四、配置文件
上一节3.3中,我们提到了配置文件,接下来顺便说明下pytest中的配置文件设置。Pytest框架中,有4个配置文件,分别是
pytest.ini,pyproject.toml,tox.ini和setup.cfg文件。
根据官方文档的说明,推荐大家使用pytest.ini,因为他的优先级是最高的。
配置选项有哪些呢,太多了,这里给大家说明些常用的配置项。
- addopts
addopts是添加指定的命令行参数,比如pytest.ini中内容如下:
[pytest]
addopts = -sv
当我在命令行运行pytest时,实际上运行的是pytest -sv
-
markers
自定义标记,这个在上一节已经讲到了。
-
norecursedirs
这个功能很有用!!!!设置在递归查找用例时,不进入哪些文件夹中收集用例。比如新建如下目录结构:
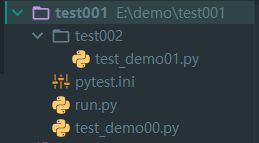
配置文件内容:
[pytest]
addopts = -sv
norecursedirs = test002
test_demo01.py:
def test_demo01():
print("我是test_demo01")
test_demo00.py:
def test_demo00():
print("我是test_demo00")
run.py:
import pytest
if __name__ == '__main__':
pytest.main()
接着,我们之间执行run.py的主函数。结果如下:
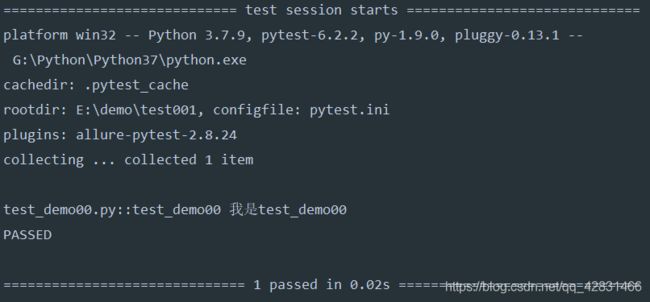
可以看到,因为配置项norecursedirs设置了test002目录,所以在执行过程中,就不会再去此目录下寻找用例。
好了,更全面的配置项需要去官方文档中查看-配置选项
五、依赖
用例依赖问题,在自动化实现中,普遍存在。
比如做接口测试,下一个请求的参数,需要用到上一个请求响应中的内容。典型场景就是cookie,session,token。
在selenium中,也有这种问题,比如,我要去购买一个商品,前提是需要登录网站,那我们在pytest中怎样解决这种问题呢?
Pytest有一个专门的依赖插件
pytest-dependency直接使用 pip3 install pytest-dependency 进行安装
编写一段代码,如下:
import pytest
@pytest.mark.dependency(name="a")
def test_a():
print("我是登录模块")
assert 2 == 3
@pytest.mark.dependency(depends=["a"])
def test_b():
print("我是购买商品")
- 首先给被依赖的用例使用装饰器
@pytest.mark.dependency()参数可以使用name命名,以待后续依赖此用例的用例调用 - 接着给需要依赖这个"a"的用例,同样用装饰器
@pytest.mark.dependency参数使用depends=[],[]内就填写被依赖的名字。 - 需要注意的是,如果被依赖的用例执行失败,后续的就直接跳过,不会执行。
以上代码运行如下:


可以看到,由于第一个用例失败,第二个用例直接Skipped跳过了。
六、结语
好了,今天我们学到了Pytest中的参数化(DDT数据驱动)、标记(mark)、配置文件、依赖等强大的功能。
下一次,我们做些收尾工作,比如一些小Tips、实际工作中会用到的技巧之类的~~