HDFS编程实践
HDFS编程实践
-
- 一、实验环境
- 二、在Windows上解压Hadoop 3
- 三、Hadoop Linux服务器设置
- 四、在Eclipse上安装Hadoop插件
- 五、WordCount编程
- 六、HDFS基础编程
- 七、应用程序的部署
一、实验环境
| 编号 | 项目 | 软件及版本 |
|---|---|---|
| 1 | 操作系统 | Windows 7-64bit |
| 2 | Hadoop | hadoop-3.1.1.tar.gz |
| 3 | JDK | 10.0.1 |
| 4 | Eclipse | 2018-09(4.9.0),Build id:20180917-1800 |
| 5 | Hadoop4Win | hadoop3.00-bin.rar |
| 6 | Eclipse插件 | hadoop-eclipse-plugin-2.6.5.jar |
二、在Windows上解压Hadoop 3
HDFS编程需要使用hadoop库,所以需要安装hadoop。在Windows上安装Hadoop 3只需要解压缩hadoop-3.1.1.tar.gz(与Linux服务器上的hadoop版本一致)就可以了。例如解压缩至C:\根目录下。
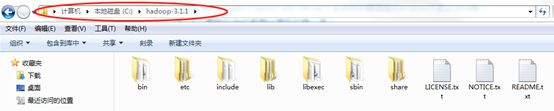
然后,从服务器上下载hadoop3.00-bin.rar,解压缩覆盖掉hadoop-3.1.1\bin文件夹。并且将bin目录中hadoop.dll(hadoop.dll尽量使用最新版本)复制到C:\Windows\System32中。
接着,设置环境变量:
- 鼠标右击“计算机”,选择“属性” >> “高级系统设置” >> “环境变量”。

- 新建“系统变量”HADOOP_HOME。

- 编辑“系统变量”Path,新增hadoop的bin路径(注意以英文分号;分割)。

三、Hadoop Linux服务器设置
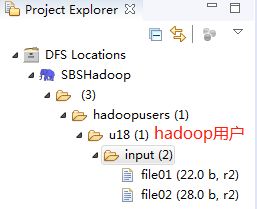
在Hadoop Master服务器上,确保已经创建了用户及其主目录(具体见《Hadoop 3.1安装与初步使用》中的“八.Hadoop平台测试”)。然后,修改hdfs-site.xml,在文档中添加。
dfs.permissions
false
启动HDFS分布式系统(详见《Hadoop 3.1安装与初步使用》),也可以使用$ start-all.sh命令。此时,看到Eclipse项目浏览器中有Hadoop用户的主目录,如下图所示。
四、在Eclipse上安装Hadoop插件
从服务器上下载hadoop-eclipse-plugin-2.6.5.jar,放到Eclipse安装目录下的plugins目录(如:C:\eclipse\plugins中),重新启动Eclipse。
打开Eclipse后,在菜单“Window” >> “Preferences”中“Hadoop Map/Reduce”下设置Hadoop的路径,如下图。
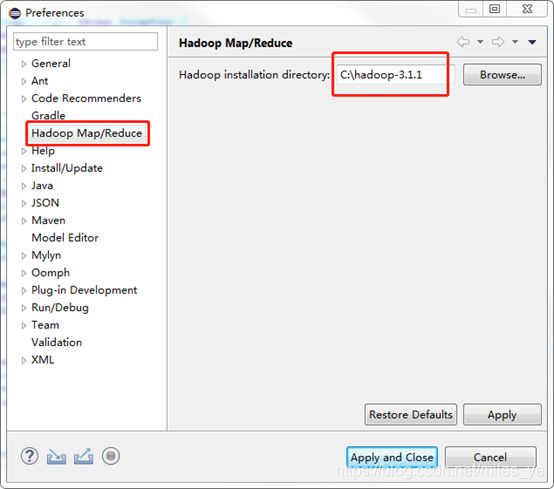
然后,通过如下两种方法之一打开Hadoop监视窗口(Perspecitve),在其中选择“Map/Reduce Locations”。
![]()

- 菜单“Window” >> “Show View” >> “Other…”
- 点击右上角“监视窗口(Perspecitve)”按钮

在Hadoop监视窗口(Perspecitve)中,右键单击“New Hadoop location…”
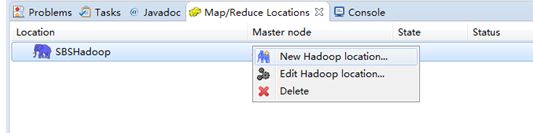
在打开的窗口中,配置主机IP地址和端口号。

选择“Advanced parameters”选项卡,设置hadoop.tmp.dir的路径和dfs.replication的复制数量为2,必须和core-site.xml中配置的要一致(例如:《Hadoop 3.1安装与初步使用》中配置的路径如下)。

最后点击“Finish”,使配置生效。
五、WordCount编程
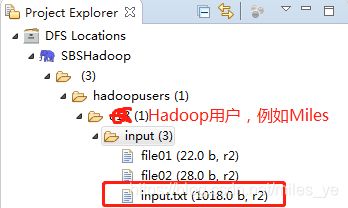
- 在Hadoop用户主目录input文件夹中,上传input.txt文件。在Eclipse工程浏览窗口右键单击Hadoop用户主目录input文件夹,选择“Upload Files to DFS…”。

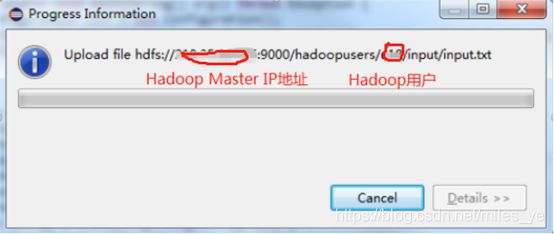
选择本地的txt文件(其中内容各类英文单词,例如:英文小说),出现如下窗口,说明文件正在上传。上传成功后可以在该目录下看到该文件。
-
创建Map/Reduce project工程。通过“File” >> “new” >> “Project” >> “Map/Reduce project”;输入项目名称“WordCount”;在“Java Settings”的 “Libraries”选项卡中选择“Classpath”;点击右边的“Add External JARs…”按钮,将下列JAR包添加到项目中:
- 本地Windows的hadoop主目录下的share/hadoop/common目录下的所有JAR包;
- 本地Windows的hadoop主目录下的share/hadoop/common/lib目录下的所有JAR包;
- 本地Windows的hadoop主目录下的share/hadoop/hdfs目录下的所有JAR包。
- 本地Windows的hadoop主目录下的share/hadoop/hdfs/lib目录下的所有JAR包。
-
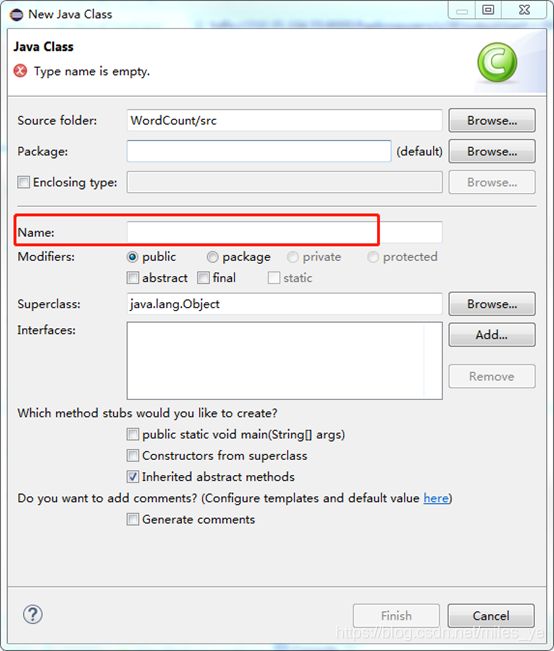
创建名称为“WordCount”的类(class)。右击WordCount工程目录下的“src”,选择“New” >> “src”,在“Java Class”窗口中输入名称(Name):WordCount。
-
在WordCount类中编写程序。
import java.io.IOException;
import java.util.Iterator;
import java.util.StringTokenizer;
import org.apache.hadoop.*;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class WordCount {
public WordCount() {
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
String[] otherArgs = (new GenericOptionsParser(conf, args)).getRemainingArgs();
if(otherArgs.length < 2) {
System.err.println("Usage: wordcount [...] " );
System.exit(2);
}
Job job = Job.getInstance(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(WordCount.TokenizerMapper.class);
job.setCombinerClass(WordCount.IntSumReducer.class);
job.setReducerClass(WordCount.IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
for(int i = 0; i < otherArgs.length - 1; ++i) {
FileInputFormat.addInputPath(job, new Path(otherArgs[i]));
}
FileOutputFormat.setOutputPath(job, new Path(otherArgs[otherArgs.length - 1]));
System.exit(job.waitForCompletion(true)?0:1);
}
public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable> {
private static final IntWritable one = new IntWritable(1);
private Text word = new Text();
public TokenizerMapper() {
}
public void map(Object key, Text value, Mapper<Object, Text, Text, IntWritable>.Context context) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while(itr.hasMoreTokens()) {
this.word.set(itr.nextToken());
context.write(this.word, one);
}
}
}
public static class IntSumReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable();
public IntSumReducer() {
}
public void reduce(Text key, Iterable<IntWritable> values, Reducer<Text, IntWritable, Text, IntWritable>.Context context) throws IOException, InterruptedException {
int sum = 0;
IntWritable val;
for(Iterator i$ = values.iterator(); i$.hasNext(); sum += val.get()) {
val = (IntWritable)i$.next();
}
this.result.set(sum);
context.write(key, this.result);
}
}
}
- 右击“WordCount类”,选择“Run As” >> “Run Configuations”,在“Arguments”选项卡中输入(如图所示):
hdfs://MasterIP地址:9000/hadoopusers/miles/input
hdfs://MasterIP地址:9000/hadoopusers/miles/output

-
- 右键“WordCount工程”,选择“Run As” >> “Java Application”,见到类似的程序运行情况。
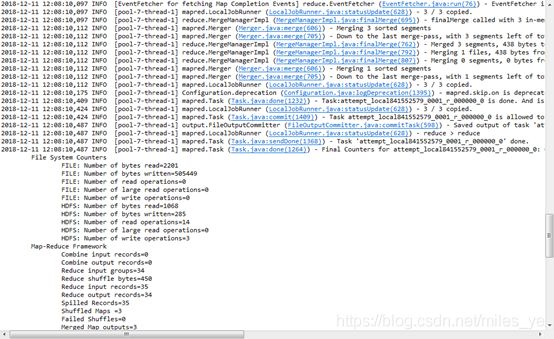
- 右键“WordCount工程”,选择“Run As” >> “Java Application”,见到类似的程序运行情况。
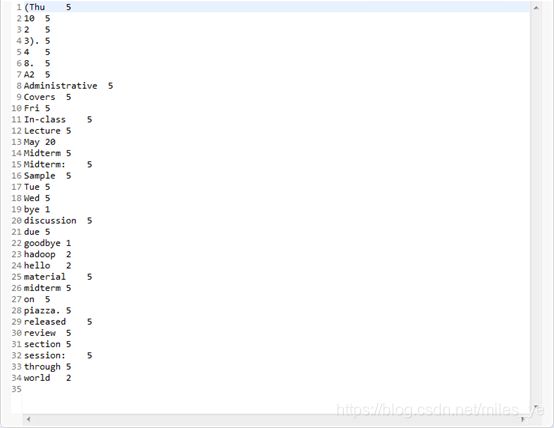
- 查看运行结果。运行结束后,在Hadoop用户主目录下回产生一个名为“output”的目录,其中有运行结果文件(如:part-r-00000)。双击打开运行结果文件,类似结果如下。
六、HDFS基础编程
编程一个程序用来测试HDFS中Hadoop用户主目录下是否存在一个名为“test”的文件。
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
public class HDFSFileIfExist {
public static void main(String[] args) {
try {
String fileName="tmp";
Configuration conf=new Configuration();
conf.set("fs.defaultFS", "hdfs://210.35.104.55:9000");
conf.set("fs.hdfs.impl", "org.apache.hadoop.hdfs.DistributedFileSystem");
FileSystem fs=FileSystem.get(conf);
if(fs.exists(new Path(fileName))) {
System.out.println("File exists");
}else {
System.out.println("File doesnot exist");
}
}catch (Exception e) {
e.printStackTrace();
}
}
}
七、应用程序的部署
将Java应用程序生成JAR包,部署到Hadoop上运行。
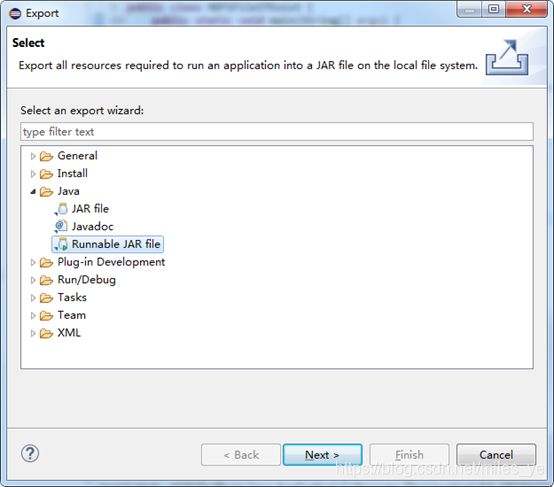
- 右击Eclipse中的“WordCount”工程,选择“Export…”。在“Select”窗口中选择“Runnable JAR file”,点击Next。
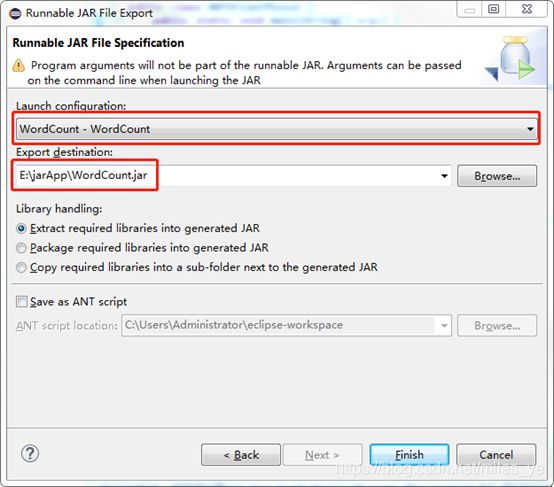
- 选择“Launch configuration”,输入“Export destination”的路径。
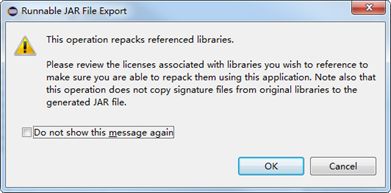
- 点击“Finish”,弹出如下警告,选择“OK”,启动打包命令。
- 打包结束后,出现如下警告窗口。在指定的目录下(Export destination)生成了JAR文件。
- 将JAR包发送到hadoop Master上,然后执行命令如下。
参考文献
[1]. 大数据笔记
[2]. 熟悉HDFS操作
[3]. Hadoop3 在eclipse中访问hadoop并运行WordCount实例
[4]. Windows10下Eclipse搭建Hadoop3开发环境