搞定分布式系列:分布式理论基础
分布式架构,需要的理论基础。
一、CAP理论
CAP理论是指在一个分布式系统中, Consistency(一致性)、 Availability(可用性)、Partition tolerance(分区容错性),三者不可兼得。
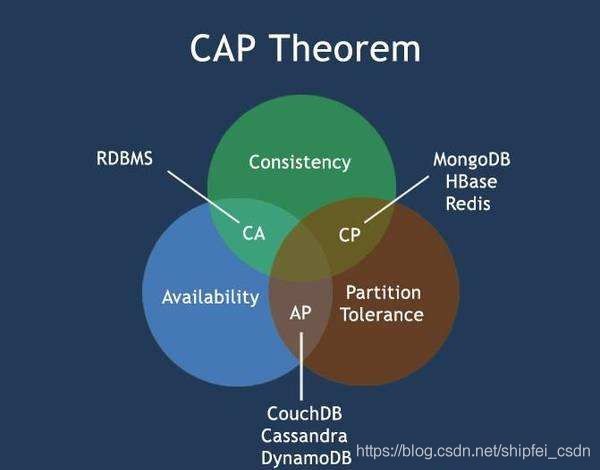
- C (Consistency),一致性:数据在分布式系统中的多个副本之间保持一致的特性。在数据一致的某个时间点,执行更新操作后,也要求系统各部分数据是一致的。
- A (Availability),可用性:服务随时可用,即使某些节点发生故障也不影响集群的对外服务。
- P (Partition),分区容错性:分区容错性约束了分布式系统在遭遇任何网络分区后(部分网络分区故障),仍要对外提供一致性和可用性的服务。(注:网络分区,即在分布式系统内,不同节点归属在不同网络子网,子网络之间可能出现网络不连通情况,但在子网内部的通信是正常的。)
二、BASE理论
BASE是Basically Available(基本可用)、Soft state(软状态)和Eventually consistent(最终一致性)三个短语的缩写。BASE理论是对CAP理论中一致性(A)和可用性(C)权衡的结果,来源于对大规模互联网系统分布式实践的结论。
- BA (Basically Available) ,基本可用:分布式系统出现故障时,允许损失部分可用性,保证核心可用。
- S (Soft state) ,软状态:系统中的节点数据允许存在中间状态,该中间状态的存在不会影响到整体的可用性,这通常体现在数据在一致性同步复制过程中,允许存在延时。
- E (Eventually consistent),最终一致性:系统中所有数据副本经过一段时间同步后,最终能够达到一致的状态。
由BASE理论,衍生出了很多数据一致性的解决方案,常见的有三种:强一致性、弱一致性、最终一致性。
BASE理论面向的是大型高可用可扩展的分布式系统,和传统的事物ACID特性是相反的,它完全不同于ACID的强一致性模型,而是通过牺牲强一致性来获得可用性,并允许数据在一段时间内是不一致的,但最终达到一致状态。但同时,在实际的分布式场景中,不同业务单元和组件对数据一致性的要求是不同的,因此在具体的分布式系统架构设计过程中,ACID特性和BASE理论往往又会结合在一起。
三、数据一致性(副本、协调者、分布式协议2PC 3PC、选举、逻辑时钟)
数据一致性是指:在分布式系统中,对每个节点的数据更新,整个集群都需要知道更新,并且是一致的。面临的问题:
- 消息传递异步无序: 现实网络不是一个可靠的信道,存在消息延时、丢失,节点间消息传递做不到同步有序。
- 节点宕机: 节点持续宕机,不会恢复。
- 节点宕机恢复: 节点宕机一段时间后恢复,在分布式系统中最常见。
- 网络分化: 网络链路出现问题,将N个节点隔离成多个部分。
- 拜占庭将军问题: 节点或宕机或逻辑失败,甚至不按套路出牌抛出干扰决议的信息。
常见的数据一致性解决方案如下,
1、副本
当前一般通过复制技术进行分布式系统的一致性的保证,不同的数据节点由于网络延迟、操作链中一环失败等原因,往往造成数据不一致的问题。
2、协调者
引入协调者的原因是在分布式操作者,需要一个中间者能够感知到该事务在其他环境中的执行情况,这样好决定在当前机器上是需要提交还是回滚。一般情况下,某一个数据库无法知道其他数据库在做什么,在一个分布式事务环境中,交易中间件是必须的,由他来通知和协调数据库提交或者回滚;而本地也将所做的操作影射到全局事务中。
3、分布式协议
常见的分布式协议有:2PC(两阶段提交)、3PC(三阶段提交),他们也不能根除数据不一致性问题。
3.1 2PC(两阶段提交)
我们将提议的节点称为协调者(coordinator),其他参与决议节点称为参与者(participants, 或cohorts)。两阶段为:
- 准备阶段(投票阶段),PreCommit。协调者发起一个提议,分别问询各参与者是否接受。
- 提交阶段(执行阶段),doCommit。协调者根据参与者的反馈,提交或中止事务,如果参与者全部同意则提交,只要有一个参与者不同意就中止。
3.2 3PC(三阶段提交)
3PC是2PC的改进版本,引入了超时机制,加入一个新的CanCommit阶段。三阶段为:
- CanCommit阶段:协调者向参与者发送commit请求,参与者如果可以提交就返回Yes响应,否则返回No响应。
- 事务询问 协调者向参与者发送CanCommit请求。询问是否可以执行事务提交操作。然后开始等待参与者的响应。
- 响应反馈 参与者接到CanCommit请求之后,正常情况下,如果其自身认为可以顺利执行事务,则返回Yes响应,并进入预备状态。否则反馈No
- PreCommit阶段:协调者根据参与者CanCommit阶段的反应情况来决定是否可以记性事务的PreCommit操作。若获得no响应,则中断事务;若获得yes响应,则,
- 发送预提交请求:协调者向参与者发送PreCommit请求,并进入Prepared阶段。
- 事务预提交:参与者接收到PreCommit请求后,会执行事务操作,并将undo和redo信息记录到事务日志中。
- 响应反馈:如果参与者成功的执行了事务操作,则返回ACK响应,同时开始等待最终指令。
- DoCommit阶段:该阶段进行真正的事务提交,若没有收到ACK响应则中断事务、回滚;若收到ACK响应,则,
- 发送提交请求:协调接收到参与者发送的ACK响应,那么他将从预提交状态进入到提交状态。并向所有参与者发送doCommit请求。
- 事务提交:参与者接收到doCommit请求之后,执行正式的事务提交。并在完成事务提交之后释放所有事务资源。
- 响应反馈:事务提交完之后,向协调者发送Ack响应。
- 完成事务:协调者接收到所有参与者的ack响应之后,完成事务。
4、选举、多数派、租约
4.1 选举
Bully算法是最常见的选举算法,其要求每个节点对应一个序号,序号最高的节点为leader。leader宕机后次高序号的节点被重选为leader。
4.2 多数派
在网络分化的场景下以上Bully算法会遇到一个问题,被分隔的节点都认为自己具有最大的序号、将产生多个leader,这时候就需要引入多数派(quorum)。多数派的思路在分布式系统中很常见,其确保网络分化情况下决议唯一。多数派的原理说起来很简单,假如节点总数为2f+1,则一项决议得到多于 f 节点赞成则获得通过。leader选举中,网络分化场景下只有具备多数派节点的部分才可能选出leader,这避免了多leader的产生。
4.3 租约
选举中很重要的一个问题,以上尚未提到:怎么判断leader不可用、什么时候应该发起重新选举?最先可能想到会通过心跳判别leader状态是否正常,但在网络拥塞或瞬断的情况下,这容易导致出现双主。租约(lease)是解决该问题的常用方法,其最初提出时用于解决分布式缓存一致性问题,后面在分布式锁等很多方面都有应用。
租约的原理同样不复杂,中心思想是每次租约时长内只有一个节点获得租约、到期后必须重新颁发租约。租约机制确保了一个时刻最多只有一个leader,避免只使用心跳机制产生双主的问题。在实践应用中,zookeeper等可用于租约颁发。
5、逻辑时钟
5.1 物理时钟 vs 逻辑时钟
可能有人会问,为什么分布式系统不使用物理时钟记录事件?每个事件对应打上一个时间戳,当需要比较顺序的时候比较相应时间戳就好了。这是因为现实生活中物理时间有统一的标准,而分布式系统中每个节点记录的时间并不一样,即使设置了NTP时间同步节点间也存在毫秒级别的偏差。因而分布式系统需要有另外的方法记录事件顺序关系,这就是逻辑时钟(logical clock)。
5.2 Lamport时间戳
Lamport时间戳帮助我们得到事件顺序关系。有这几个特点,
- 每个事件对应一个Lamport时间戳,初始值为0
- 如果事件在节点内发生,时间戳加1
- 如果事件属于发送事件,时间戳加1并在消息中带上该时间戳
- 如果事件属于接收事件,时间戳 = Max(本地时间戳,消息中的时间戳) + 1
5.3 Vector clock
有一种顺序关系不能用Lamport时间戳很好地表示出来,那就是同时发生关系(concurrent)。Vector clock是在Lamport时间戳基础上演进的另一种逻辑时钟方法,它通过vector结构不但记录本节点的Lamport时间戳,同时也记录了其他节点的Lamport时间戳。
5.4 Version vector
Version vector的实现与Vector clock非常类似,目的用于发现数据冲突。