Fink Sql Hive维表Join
Flink 1.11支持与Hive表的Join,Flink 1.11官方文档如下图所示。
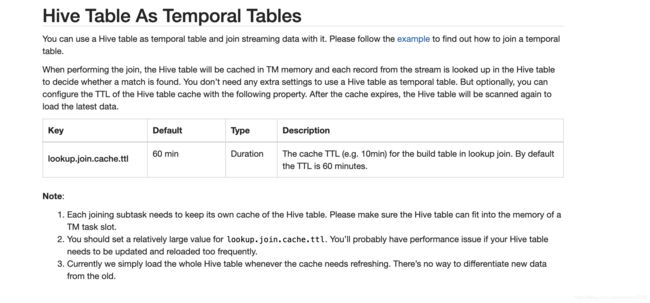
根据官方文档:
1.hive表会缓存到TM内存,所以join的hive表不宜太大。
2.根据lookup.join.cache.ttl 参数,flink会定期刷新hive缓存
而业务需求是Flink 读取kafka 和T+1更新的hive表,对于kafka的数据,只处理type字段在hive表中存在的数据。
首先尝试了如下Flink sql:
select a.* from flink_tab a where a.type in (select type from hive_tab);
这种sql 可以运行,也会读取hive表,但是从flink web ui 上可以看到,在读取hive表结束后,task就直接finish了。也不会定期刷新hive的数据,所以不符合我们的要求。
Flink 1.12 的文档中给出了标准的写法

其中主要3个参数
'streaming-source.enable' = 'false',
'streaming-source.partition.include' = 'all',
'lookup.join.cache.ttl' = '12 h'| streaming-source.enable |
false | Boolean | Enable streaming source or not. NOTES: Please make sure that each partition/file should be written atomically, otherwise the reader may get incomplete data. |
由于我们的需求是把hive当做bounded stream,所以这里我们选择false
| streaming-source.partition.include |
all | String | Option to set the partitions to read, the supported option are `all` and `latest`, the `all` means read all partitions; the `latest` means read latest partition in order of 'streaming-source.partition.order', the `latest` only works` when the streaming hive source table used as temporal table. By default the option is `all`. Flink supports temporal join the latest hive partition by enabling 'streaming-source.enable' and setting 'streaming-source.partition.include' to 'latest', at the same time, user can assign the partition compare order and data update interval by configuring following partition-related options. |
这个参数在Flink1.11中是不支持的,在Flink1.12才支持。这里就涉及到hive表的设计,如果是all,则hive表只能保存目前有效的配置,如果选择latest,则可以通过配置streaming-source.partition.order参数,来读取指定的分区。例如hive表根据年月日分区,flink关联的时候只读取当天的分区,这样,hive表就能保留所有历史数据。这个根据业务需求选择,由于我用的是1.11版本,经过测试,在不设置该参数的情况下,是读取hive表的所有数据,相当于all
| lookup.join.cache.ttl |
60 min | Duration | The cache TTL (e.g. 10min) for the build table in lookup join. By default the TTL is 60 minutes. NOTES: The option only works when lookup bounded hive table source, if you're using streaming hive source as temporal table, please use 'streaming-source.monitor-interval' to configure the interval of data update. |
lookup.join.cache.ttl:这个很简单,刷新缓存的时间间隔。
这里我们需要做的是证明这个参数有效,并且读取了正确的数据。
首先,对于hive表,添加参数
alter table hive_tab set tblproperties('lookup.join.cache.ttl'='60 min');
alter table hive_tab set tblproperties('lookup.join.cache.ttl'='1 min');
再次启动任务
可以看到刷新频率改为了1min。
通过日志 Reading ORC rows from ***,可以看到,flink读取hive,是直接读取的orc文件,而不是通过hive jdbc 返回数据。
这就可以解释,为什么flink jion hive表时如果 join 的是一个hive子查询,flink 会报错。
如果join 的hive 表数据需要经过处理,例如hive a join hive b 生成hive c ,hive c 再与flink join,那么建议离线T+1将hive c 生成好后,Flink 只与 hive c交互。
最终sql:
select a.f0,a.f1,a.f2 from
(select f0,f1,f2,PROCTIME() as proctime from flink_tab ) as a
inner join hive_tab FOR SYSTEM_TIME AS OF a.proctime as v on a.type=v.type