使用Spark sql 合并 Flink 写Hive表的小文件
1.背景
Flink 1.11支持写直接写入Hive后,流批一体进一步实现。虽然可以通过调整sink.shuffle-by-partition.enable和checkpoint时间间隔的方式尽可能地减少Flink产生的小文件,但是即使Flink 1.12加入了自动合并小文件的功能,也无法完全避免小文件的产生。
所以需要定期对Flink 写hive表的小文件进行合并。
2.Hive Tez 方式 合并小文件
set hive.exec.dynamic.partition=true;
set hive.exec.dynamic.partition.mode=nonstrict;
set hive.exec.max.dynamic.partitions=100000;
set hive.exec.max.dynamic.partitions.pernode=100000;
set hive.merge.smallfiles.avgsize=256000000;
set hive.merge.size.per.task=256000000;
insert overwrite table t partition (p_dt,p_hours)
select * from t where p_dt='2021-02-23';
Tez合并小文件存在的问题
1.合并时占用大量yarn内存,合并2-3天的数据,就会占用TB级别的内存,内存使用完全不可控,影响其他业务集群稳定性。
2.由于上述的问题,每次只能合并1~2天的数据,如果要合并数月的数据,使用脚本遍历执行,由于频繁的启动任务,需要的总时间很长。对集群的压力很大,不利于集群的稳定性。
3.Spark sql 合并小文件
set hive.exec.dynamic.partition=true;
set hive.exec.dynamic.partition.mode=nonstrict;
set spark.sql.adaptive.enabled=true;
set spark.sql.adaptive.coalescePartitions.enabled=true;
set spark.shuffle.sort.bypassMergeThreshold=800;
set spark.sql.shuffle.partitions=900;
Flink 写hive 生成的文件如下图,这里Flink 的checkpoint为5分钟,sink.shuffle-by-partition.enable=true,即Flink会5min产生一个文件。按照天,小时分区。
理论上会有(12+n+1)*24 个文件
其中n为跨小时延迟的数据文件,例如,10点01分,来了9点的数据。因为是按照数据的时间分区,而不是process time 分区。
大概率为300+个文件。
hdfs dfs -count -h /user/hive/warehouse/dw_db.db/dw_recessw_browser_pc_behavior_rt/*

使用spark3.0的原因就在于hint 提示符。
可以直接使用sql的方式合并小文件。
参考文档
https://spark.apache.org/docs/latest/sql-ref-syntax-qry-select-hints.html#partitioning-hints
-
COALESCE
The
COALESCEhint can be used to reduce the number of partitions to the specified number of partitions. It takes a partition number as a parameter. -
REPARTITION
The
REPARTITIONhint can be used to repartition to the specified number of partitions using the specified partitioning expressions. It takes a partition number, column names, or both as parameters. -
REPARTITION_BY_RANGE
The
REPARTITION_BY_RANGEhint can be used to repartition to the specified number of partitions using the specified partitioning expressions. It takes column names and an optional partition number as parameters.
这里我们选择REPARTITION_BY_RANGE。
如果不加提示符,spark也会合并部分小文件,而且性能会快不少,但是不会保证小文件彻底合并,加上提示符,可以保证文件彻底合并,但是需要消耗更多的时间。
spark-sql --master yarn --queue common --num-executors 10 --executor-cores 8 --executor-memory 28G
注意这里core不适合设置太多,太多可能会导致oom。
insert overwrite table t partition (p_dt,p_hours) select * from t where p_dt between '2021-01-20' and '2021-02-19' ;
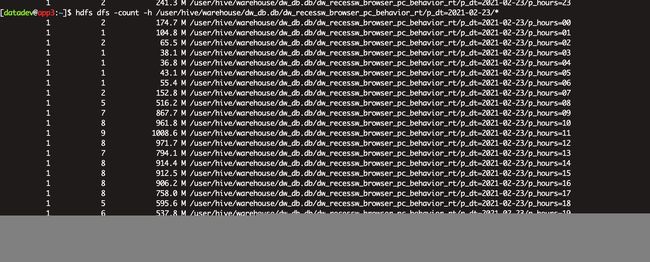
如上图所示,p_hours=02分区有2个文件,其实很不合理,但是这个2,和合并前的数据文件数量有关,所以,不加提示符也可以合并部分小文件,但是结果会有不确定性。
insert overwrite table t partition (p_dt,p_hours) select /*+ REPARTITION_BY_RANGE(p_dt,p_hours) */ * from t where p_dt between '2021-01-20' and '2021-02-19' ;

而加了提示符过后,数据文件个数严格按照提示符来。
1.使用sparksql合并小文件,同样的数据300g内存可以跑几个月的数据,不用频繁启动任务。大量减少时间,总体合并时间远小于tez合并的方式。
2.内存使用稳定控制在300g,不影响其他程序运行。
3.spark默认完成了snappy压缩。而tez合并小文件,不会压缩文件。压缩后文件大小大致为之前的四分之一,存储成本降低75%。
4.相对于spark 脚本合并小文件,spark sql合并的方式更便捷,可以直接改造 spark sql 写的离线任务,从根源上解决部分离线任务的小文件的问题。