Python 基础入门第十六讲 文件读写操作、上下文管理器
第十六讲
一、文件读写
通过python我们可以对一些文件数据进行操作,文件包括txt、doc、xls、ppt等众多类型。
对于文件的操作一般分为三步走:
- 打开文件;
- 操作文件;
- 关闭文件;
1. 打开文件 open()
打开文件可以采用python内置方法open(),用于对文件进行读写操作。open()方法的返回值是一个file对象,我们将其赋值给一个变量(文件句柄),其基本的语法格式为:
f = open(file,mode='r',encoding=None) # 还有许多参数未涉及,可自行查看
需要注意的是,file参数可以给定当前工作目录下的文件名,如果文件非当前工作目录,需要输入完整的路径。mode是模式,经常使用到的模式有’r’、‘w’、'a’等,可以ctrl左键自行查看。encoding是编码或解码的格式,如果文本内容中有汉字,需要采用encoding = 'utf-8’才可进行读写操作。
常见的模式为:
'r' open for reading (default) # 可读,文件如果不存在则会报错
'w' open for writing, truncating the file first # 可写
'x' create a new file and open it for writing
'a' open for writing, appending to the end of the file if it exists
'b' binary mode
't' text mode (default)
'+' open a disk file for updating (reading and writing)
'U' universal newline mode (deprecated)
2. f.readable()、f.read()、f.redaline()
我们现在来看一个案例,学习一些具体的操作。
在工作目录下新建一个txt文档:

然后在业务程序中我们可以读取该文件,通过文件句柄接收,判断是否可读:
f = open('text.txt') # 默认mode = 'r', encoding = None
print(f.readable()) # 判断程序是否可读,返回值为布尔值
---------------------
结果:
True
如果想要打印输出所有文本内容:
print(f.read()) # 读取全部内容,f.read()可传入参数n,代表读取前n个字符数的意思
-----------------
结果:
123
456
789
需要着重说一下n这个参数,还是接着上面的案例,我们来看一下不同的结果:
print(f.read(3))
--------------
结果:
123
我们将n = 4输入:
print(f.read(4))
--------------
结果:
123
当n = 3和4的时候,输出结果看似相同,实则不然。需要注意的是,换行符 \n 也算作一个字符,因而结果实则多了一个换行。并且还需要注意的是,打印输出内容后相应的光标位置也会发生变化,比如连续打印输出:
print(f.read(3))
print(f.read(3))
-----------------
结果:
123 # 在首句print之后,出发print默认参数end = \n,换行
# text文件内的光标已经挪至第3个字符之后,再次print,首个字符为\n。
45 # 到此共打印6个字符
假设我们更改一下text文件的内容,加上汉字:
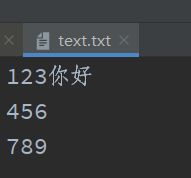
此时若要顺利读取该文件,需要将encoding参数设置为utf-8:
f = open('text.txt',encoding='utf-8') # mode参数仍旧默认为'r',只读
print(f.read())
-------------
结果:
123你好 # 汉字也只占用一个字符
456
789
如果我们想一行一行的读取也可以:
f = open('text.txt',encoding='utf-8')
print(f.readline()) # 通过该方法读取一行
---------------------------
结果:
123你好
3. f.tell()
通过该方法查看光标所在位置:
f = open('text.txt',encoding='utf-8')
print(f.tell())
print(f.readline(),end='') # 通过end=''取消多余的换行操作
print(f.tell())
-------------
结果:
0 # 刚开始光标在0字节的位置上
123你好 # 根据utf-8,数字占一个字节,汉字占三个字节,\n占两个字节。
11 # 现在光标在第11字节之后
需要注意下不同的字符所占字节数量。
4. f.readlines()
该方法也是读取全部字符,返回一个列表:
f = open('text.txt',encoding='utf-8')
print(f.readlines())
------------------------
结果:
['123你好\n', '456\n', '789']
做一个小练习,现在要在text第二行后面加一个"hello world"":
f = open('text.txt',encoding='utf-8')
res = f.readlines()
for i in range(len(res)): # 这里采用range,i的范围是[0,3)
if i == 1:
print(res[i].strip(),'hello world') # .strip()可以用来去掉行最后的换行符
else:
print(res[i],end='')
--------------------------------------
结果:
123你好
456 hello world
789
强调一下,.strip()方法是用来去掉字符串开头或者结尾的空格或者换行符。
二、其它模式
上面着重介绍了mode = ‘r’,也就是只读模式的一些应用,下面学习一下其它的模式。
1. 'w’只写模式,f.write()、f.writable()、f.writelines()
上节讲到,如果不存在文件,是无法采用’r’模式只读的。
如果是’w’模式,不存在文件则会创建一个新的文件。
f.writable()用以返回一个布尔值,判断文件是否可写。
f.write()是向文件中写入信息:
f = open('text.txt',mode='w')
f.write('hello world') # 向文件中写入字符串'hello world'
需要注意的是,f.write()方法执行完后光标仍然在最前端,也就是说,重复执行f.write()会将原先的内容覆盖,但是同时执行多个f.write(),各写入命令之间不会形成覆盖关系。用个例子解释一下:
f = open('text.txt',mode='w')
f.write('hello world')
-------------------------
执行一次,text文本内容为:
hello world
-------------------------
f.write('hello Tom')
-------------------------
再执行一次,text文本内容变为:
hello Tom
-------------------------
f.write('hello world')
f.write('hello Tom')
-------------------------
同时执行,text文本内容为: # 同时执行,各写入操作之间不会覆盖
hello worldhello Tom # 没有\n,所以不美观
同时写入多行可以采用f.writelines([list]):
f = open('text.txt',mode='w')
f.writelines(['hello world\n','hello Tom'])
--------------------
text文本内容为:
hello world
hello Tom
2. 'a’追加模式, f.write()
'a’模式被认为是追加模式,是单词append的首字母。追加模式同样可以创建一个原本不存在的文件。
追加模式可以向文件中追加内容,同样使用f.write()方法添加,不会覆盖原内容。
3. ‘r+’、'w+'模式
许多模式后加上一个“+”可以增加一些功能。
'r+'模式表示可读可写,以r为主导,并且拥有w和a模式的权限。以r为主导体现在不可以通过’r+'模式创建新文件,但是可以改写、添加内容。
'w+'模式不仅可写,还可读。
但是本人亲测了一下,**上述两个模式在经过f.write()方法调用后,再次读取就读不出内容了。**这个可能与f.write()方法的光标永远是在最前端有关,目前还无法厘清应用场景,日后再谈。
三、一些零碎的知识
1. 字节和字符
在python中,字节转为字符叫解码(decode),字符转为字节叫编码(encode),字节为bytes,是给计算机看的、保存或者运输的,字符是给人看的,用来操作的。
-
字节的概念:
字节(Byte )是计算机信息技术用于计量存储容量的一种计量单位,作为一个单位来处理的一个二进制数字串,是构成信息的一个小单位。最常用的字节是八位的字节,即它包含八位的二进制数。
位(bit):是计算机 内部数据 储存的最小单位,11001100是一个八位二进制数。
字节(byte):是计算机中 数据处理 的基本单位,习惯上用大写 B 来表示,1B(byte,字节)= 8bit(位)。 -
字符的概念:
字符是指计算机中使用的字母、数字、字和符号。在UTF-8编码 中,一个英文字母字符存储需要1个字节,一个汉字字符储存需要3个字节。
我们从网上获取的图片、音频都是二进制的数据形式。当我们需要将str模式的字符转化为bytes字节时,只需要在前面加上一个b:
a = b'hello world' # a为字节类型的对象
对于字节类型的数据,是否可以写进’w’模式的文件中呢?
a = b'hello world'
f = open('text.txt','w')
f.write(a)
---------------------
结果:
TypeError: write() argument must be str, not bytes
答案是否定的,'w’模式不可以写入字节类型的数据,因而我们需要换一下模式。在方法说明文档中有一个’b’模式,是专门服务于二进制数据的,我们将模式更改为’wb’即可。
a = b'hello world'
f = open('text.txt','wb')
f.write(a)
2. json数据的一些补充案例
在以后业务中会经常和json数据打交道。json是一种数据格式,也是可以作为文件的后缀名。它类似于将字典变为str后的数据格式,但一定是双引号加持。我们再实际工作中可以向json文件中写入数据,如:
import json
data = {
"name":"Tom"} # 这是一个字典
f = open('Json_doc.json','w') # 模式为'w'
json.dump(data,f) # json.dump()是将字典数据写入json文件中的方法
需要说明的是,json.dump(obj,fp)的两个参数obj和fp,obj是数据对象,即要传入的数据;fp是json文件,这里用文件句柄指代。还有其它很多参数没有了解,以后有需要的时候再做补充。
当我们需要读取处理json文件中的数据时,我们通常选择将其内容转化为字典的形式,这样可以通过key和value的对应关系来进行便捷处理:
import json
f = open('Json_doc.json','r') # 模式为'r'
res = json.load(f) # 用一个变量来接收json文件的内容,通过json.load方法,res此时为字典格式
print(res)
可以看出,在面对json文件的时候,我们的读写工作没有用到f.write()和f.read(),目的都是为了更加方便的处理数据。
四、文件关闭和上下文管理器
1. 文件关闭
f.close() 方法用于关闭一个已打开的文件,关闭后的文件不能再进行读写操作, 否则会触发 ValueError 错误。 close() 方法允许调用多次。
当file对象,被引用到操作另外一个文件时,Python 会自动关闭之前的 file 对象。使用 close() 方法关闭文件是一个好的习惯。
在这里说几个有意思的点。
之前在讲述f.write()的时候,当我们向空文件text.txt写入内容,再次读取,发现读不出内容:
f = open('text.txt','r+')
f.write('hello')
print(f.read())
---------------------
结果为空,但是查阅文件已经有内容hello写入,且光标在最前方
这是因为,f.write()是在所有程序执行完毕才写入,也就是发生在print(f.read())之后,咱也不明白为啥,可以通过time.sleep睡个几秒来验证一下,的确是这样的。
那么如何来实现写入文件内容后再次打印输出呢?巧用f.close():
f = open('text.txt','r+')
f.write('hello')
f.close()
f = open('text.txt','r+') # 重新打开文件
print(f.read())
---------------------------
结果:
hello
2. 上下文管理器
如果每次都需要关闭文件,在实际应用中遇到相对复杂的业务时就会显得较为麻烦。使用with open语句就可以省略f.close()这一步:
with open() as f:
pass
- with 自动调用__ enter__(),将方法的返回值赋给as后面的变量,相当于 f = open();
- with 后面的代码块全部执行完毕后,将调用前面返回对象的__ exit__()方法,相当于f.close()。
这个就叫做上下文管理器。与open()方法使用没有区别,只是最后打开的文件会自动关闭。