2.Hystrix说明
官方文档[https://github.com/Netflix/Hy...]
hystrix是netflix开源的一个容灾框架,解决当外部依赖故障时拖垮业务系统、甚至引起雪崩的问题。
2.1为什么需要Hystrix?
在大中型分布式系统中,通常系统很多依赖(HTTP,hession,Netty,Dubbo等),在高并发访问下,这些依赖的稳定性与否对系统的影响非常大,但是依赖有很多不可控问题:如网络连接缓慢,资源繁忙,暂时不可用,服务脱机等。
当依赖阻塞时,大多数服务器的线程池就出现阻塞(BLOCK),影响整个线上服务的稳定性,在复杂的分布式架构的应用程序有很多的依赖,都会不可避免地在某些时候失败。高并发的依赖失败时如果没有隔离措施,当前应用服务就有被拖垮的风险。
例如:一个依赖30个SOA服务的系统,每个服务99.99%可用。99.99%的30次方 ≈ 99.7%0.3% 意味着一亿次请求 会有 3,000,00次失败换算成时间大约每月有2个小时服务不稳定.随着服务依赖数量的变多,服务不稳定的概率会成指数性提高.
解决问题方案:对依赖做隔离。
2.2Hystrix设计理念
想要知道如何使用,必须先明白其核心设计理念,Hystrix基于命令模式,通过UML图先直观的认识一下这一设计模式
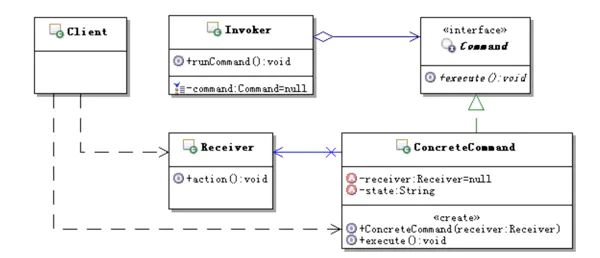
可见,Command是在Receiver和Invoker之间添加的中间层,Command实现了对Receiver的封装。那么Hystrix的应用场景如何与上图对应呢?
API既可以是Invoker又可以是reciever,通过继承Hystrix核心类HystrixCommand来封装这些API(例如,远程接口调用,数据库查询之类可能会产生延时的操作)。就可以为API提供弹性保护了。
2.3Hystrix如何解决依赖隔离
1:Hystrix使用命令模式HystrixCommand(Command)包装依赖调用逻辑,每个命令在单独线程中/信号授权下执行。
2:可配置依赖调用超时时间,超时时间一般设为比99.5%平均时间略高即可.当调用超时时,直接返回或执行fallback逻辑。
3:为每个依赖提供一个小的线程池(或信号),如果线程池已满调用将被立即拒绝,默认不采用排队.加速失败判定时间。
4:依赖调用结果分:成功,失败(抛出异常),超时,线程拒绝,短路。 请求失败(异常,拒绝,超时,短路)时执行fallback(降级)逻辑。
5:提供熔断器组件,可以自动运行或手动调用,停止当前依赖一段时间(10秒),熔断器默认错误率阈值为50%,超过将自动运行。
6:提供近实时依赖的统计和监控
2.4Hystrix流程结构解析
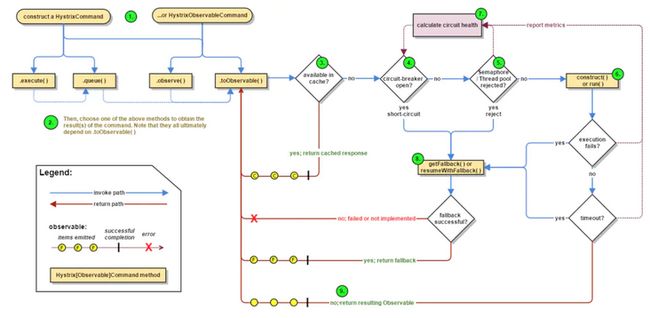
流程说明:
1:每次调用创建一个新的HystrixCommand,把依赖调用封装在run()方法中.
2:执行execute()/queue做同步或异步调用.
3:判断熔断器(circuit-breaker)是否打开,如果打开跳到步骤8,进行降级策略,如果关闭进入步骤.
4:判断线程池/队列/信号量是否跑满,如果跑满进入降级步骤8,否则继续后续步骤.
5:调用HystrixCommand的run方法.运行依赖逻辑5a:依赖逻辑调用超时,进入步骤8.
6:判断逻辑是否调用成功6a:返回成功调用结果6b:调用出错,进入步骤8.
7:计算熔断器状态,所有的运行状态(成功,失败,拒绝,超时)上报给熔断器,用于统计从而判断熔断器状态.
8:getFallback()降级逻辑.以下四种情况将触发getFallback调用:
(1):run()方法抛出非HystrixBadRequestException异常。
(2):run()方法调用超时
(3):熔断器开启拦截调用
(4):线程池/队列/信号量是否跑满
8a:没有实现getFallback的Command将直接抛出异常
8b:fallback降级逻辑调用成功直接返回
8c:降级逻辑调用失败抛出异常
9:返回执行成功结果
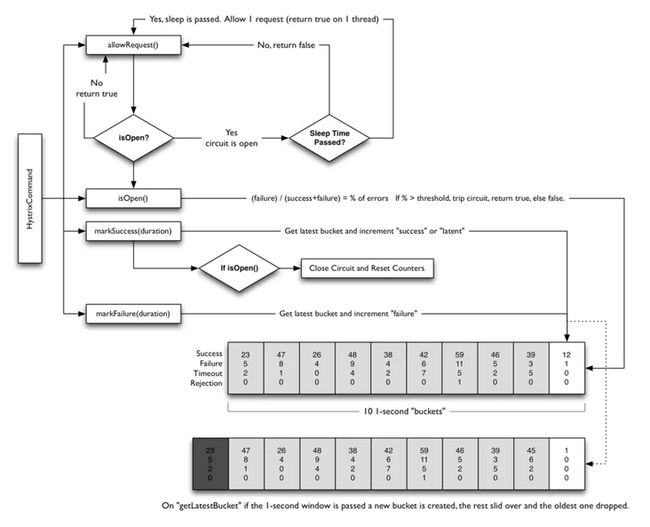
2.5熔断器:Circuit Breaker
每个熔断器默认维护10个bucket,每秒一个bucket,每个bucket记录成功,失败,超时,拒绝的状态,
默认错误超过50%且10秒内超过20个请求进行中断拦截.
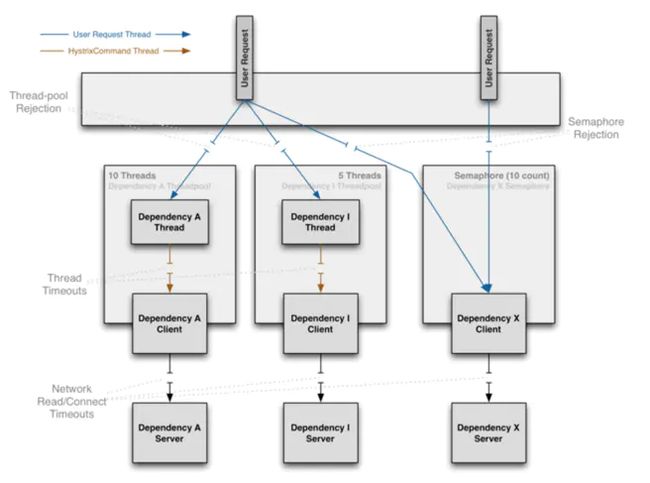
2.6Hystrix隔离分析
Hystrix隔离方式采用线程/信号的方式,通过隔离限制依赖的并发量和阻塞扩散.
(1)线程隔离
把执行依赖代码的线程与请求线程(如:jetty线程)分离,请求线程可以自由控制离开的时间(异步过程)。
通过线程池大小可以控制并发量,当线程池饱和时可以提前拒绝服务,防止依赖问题扩散。
线上建议线程池不要设置过大,否则大量堵塞线程有可能会拖慢服务器。
(2)线程隔离的优缺点
线程隔离的优点:
线程隔离的缺点:
NOTE: Netflix公司内部认为线程隔离开销足够小,不会造成重大的成本或性能的影响。
Netflix 内部API 每天100亿的HystrixCommand依赖请求使用线程隔,每个应用大约40多个线程池,每个线程池大约5-20个线程。
(3)信号隔离
信号隔离也可以用于限制并发访问,防止阻塞扩散, 与线程隔离最大不同在于执行依赖代码的线程依然是请求线程(该线程需要通过信号申请),
如果客户端是可信的且可以快速返回,可以使用信号隔离替换线程隔离,降低开销.
信号量的大小可以动态调整, 线程池大小不可以.
线程隔离与信号隔离区别如下图:
4.参数说明
其参数可参见https://github.com/Netflix/Hystrix/wiki/Con
分类参数作用默认值备注
基本参数groupKey表示所属的group,一个group共用线程池getClass().getSimpleName();
基本参数commandKey当前执行方法名
Execution ( 控制HystrixCommand.run()的执行策略)execution.isolation.strategy隔离策略,有THREAD和SEMAPHORE THREAD以下几种可以使用SEMAPHORE模式: 只想控制并发度 外部的方法已经做了线程隔离 调用的是本地方法或者可靠度非常高、耗时特别小的方法(如medis)
Executionexecution.isolation.thread.timeoutInMilliseconds超时时间1000ms默认值:1000 在THREAD模式下,达到超时时间,可以中断 在SEMAPHORE模式下,会等待执行完成后,再去判断是否超时 设置标准: 有retry,99meantime+avg meantime 没有retry,99.5meantime
Executionexecution.timeout.enabled是否打开超时true
Executionexecution.isolation.thread.interruptOnTimeout是否打开超时线程中断trueTHREAD模式有效
Executionexecution.isolation.semaphore.maxConcurrentRequests信号量最大并发度10SEMAPHORE模式有效
Fallback ( 设置当fallback降级发生时的策略)fallback.isolation.semaphore.maxConcurrentRequestsfallback最大并发度10
Fallbackfallback.enabledfallback是否可用true
Circuit Breaker (配置熔断的策略)circuitBreaker.enabled是否开启熔断true
Circuit BreakercircuitBreaker.requestVolumeThreshold一个统计窗口内熔断触发的最小个数/10s20
Circuit BreakercircuitBreaker.sleepWindowInMilliseconds熔断多少秒后去尝试请求5000ms
Circuit BreakercircuitBreaker.errorThresholdPercentage失败率达到多少百分比后熔断50主要根据依赖重要性进行调整
Circuit BreakercircuitBreaker.forceOpen是否强制开启熔断
Circuit BreakercircuitBreaker.forceClosed是否强制关闭熔断如果是强依赖,应该设置为true
Metrics (设置关于HystrixCommand执行需要的统计信息)metrics.rollingStats.timeInMilliseconds设置统计滚动窗口的长度,以毫秒为单位。用于监控和熔断器。10000滚动窗口被分隔成桶(bucket),并且进行滚动。 例如这个属性设置10s(10000),一个桶是1s。
Metricsmetrics.rollingStats.numBuckets 设置统计窗口的桶数量10metrics.rollingStats.timeInMilliseconds必须能被这个值整除
Metricsmetrics.rollingPercentile.enabled设置执行时间是否被跟踪,并且计算各个百分比,50%,90%等的时间true
Metricsmetrics.rollingPercentile.timeInMilliseconds设置执行时间在滚动窗口中保留时间,用来计算百分比60000ms
Metricsmetrics.rollingPercentile.numBuckets设置rollingPercentile窗口的桶数量6metrics.rollingPercentile.timeInMilliseconds必须能被这个值整除
Metricsmetrics.rollingPercentile.bucketSize此属性设置每个桶保存的执行时间的最大值。100如果设置为100,但是有500次求情,则只会计算最近的100次
Metricsmetrics.healthSnapshot.intervalInMilliseconds采样时间间隔500
Request Context ( 设置HystrixCommand使用的HystrixRequestContext相关的属性)requestCache.enabled设置是否缓存请求,request-scope内缓存true
Request ContextrequestLog.enabled设置HystrixCommand执行和事件是否打印到HystrixRequestLog中
ThreadPool Properties(配置HystrixCommand使用的线程池的属性)coreSize设置线程池的core size,这是最大的并发执行数量。10设置标准:coreSize = requests per second at peak when healthy × 99th percentile latency in seconds + some breathing room 大多数情况下默认的10个线程都是值得建议的
ThreadPool PropertiesmaxQueueSize最大队列长度。设置BlockingQueue的最大长度-1默认值:-1 如果使用正数,队列将从SynchronousQueue改为LinkedBlockingQueue
ThreadPool PropertiesqueueSizeRejectionThreshold设置拒绝请求的临界值5此属性不适用于maxQueueSize = - 1时 设置设个值的原因是maxQueueSize值运行时不能改变,我们可以通过修改这个变量动态修改允许排队的长度
ThreadPool PropertieskeepAliveTimeMinutes设置keep-live时间1分钟这个一般用不到因为默认corePoolSize和maxPoolSize是一样的。