2.正则表达式从入门到实战
目录
导读
一、正则表达式
1.点号“.”
2.星号“*”
3.问号“?”
4.“.*”和“.*?”的区别
5.反斜杠“\”
6.数字“\d”
7.括号“()”
二、在Python中使用正则表达式
1.findall
2.search
3.正则表达式练习
三、正则表达式的提取技巧
1.先抓大再抓小
2.括号内和括号外
四、实例:爬取百度贴吧的评论信息
1.在浏览器中获取网页的源代码
2.读取文本文件
3.应用正则表达式抓取信息
4.保存csv文件
五、项目实战
导读
在爬虫开发中,需要把有用的信息从一大段文本中匹配出来,正则表达式是提取信息的方法之一。学号正则表达式,是学好爬虫的第一步。[1]
通过这一章的学习,你将会掌握如下知识:
1.正则表达式的基本符号
2.在Python中使用正则表达式
3.正则表达式的提取技巧
一、正则表达式
正则表达式(Regular Expression)是一段字符串,它可以表示一段有规律的信息。Python自带一个正则表达式模块re,可是实现查找、提取、替换指定规律的字符串。
使用正则表达式有如下步骤:
(1)寻找规律
(2)使用正则符号表示规律
(3)提取信息
例如有以下字符串,其中包含了3段密码。仔细观察我们可以找到如下规律,所有的密码都被包在:分号和,逗号之间,所有我们能找到分号和逗号之间的内容,就能找到这3段密码。
'''
我在学习正则表达式, password:123456, 它是一段字符串,
password:abcdefg,它能表示一段有规律的信息,password:111333,学习正则表达式应该是一件有意思的事情。
'''我们先看一些简单例子:
# 任务一:找到字符串中所有‘n’
text1 = 'Loving can hurt'这里可以使用正则表达式:‘n’,它可以找出字符串中的所有n。
# 任务二:找到字符串中的We
text2 = '''
We keep this love in a photograph
We make these memories for ourselves
'''这里可以使用正则表达式:‘We’,它可以找到字符串中的所有We,它可以精准的匹配出字符串中所有的We。在英文中是有大小写之分的,在re的参数中可以设置区分大小写。(详见表)
以上两个例子都是最简单的正则表达式,再看下面的例子,我们让问题变得稍微复杂一点。
# 任务三:找到字符串中的英文单词We
text3 = '''
We keep this love in a photograph
We make these memories for ourselves
Well that's ok baby only words bleed
'''如果我们还是用第二个例子中的‘We’匹配text3,我们将得到We We We,但其实第三个We是英文单词Well的一部分,而不是英文单词We。这里我们就需要将正则表达式修改为‘\bWe\b’,其中\b是正则表达式匹配模式元素中的一种,\b的意义是匹配一个单词边界,也就是指单词和空格间的位置。例如, 'er\b' 可以匹配"never" 中的 'er',但不能匹配 "verb" 中的 'er'。
下面我们将具体学习正则表达式的符号使用
以下我们将介绍正则表达式中的最常用点好“.”、星号“*”、问号“?”以及他们的组合使用。
1.点号“.”
一个点好可以代替除了换行符以外的任何一个字符,包括但不限于英文字母、数字、汉字、英文标点符号和中文标点符号。例如有以下不同的字符串:
# 任务四:找到所有py thon之间的内容
text4 = '''
pyabcthon
py123hon
py谢谢您thon
py'o'thon
'''这些字符串的前2个字符都是'py',后四个字符都是‘thon’,只有中间的3个字符不同,如果使用点号表示,那么全部可以变成‘py...thon’,中间有多少个字就用多少个点。
2.星号“*”
一个星号可以表示它前面的一个子表达式(普通字符、另一个或几个正则表达式符号)0次到无限次。
# 任务五:找到以下所有字符串
text5 = '''
我是一名爬虫工程师
我是一名爬虫工程师师
我是一名爬虫工程师师师
我是一名爬虫工程师师师师
'''这些字符串里面,“师”字重复出现,我们用星号来表示,就可以表示为:
'我是一名爬虫工程师*'这里请大家一直保持警惕,正则表达式是一段字符串,所以我们要用单引号、双引号甚至三引号(多条规则)将它括起来。
既然星号可以表示它前面的字符,如果它前面的字符是一个点号呢?它能指代什么?例如:
'我.*师'它表示在‘我’和‘师’之间出现“任意多个除了换行符以外的任意字符。”这是因为点号表示除换行符以外的任意字符,星号表示它前面的一个子表达式的0次或者无限次。也就是说点号表示内容,星号表示重复次数,组合起来就是“任意多个除了换行符以外的任意字符。”我们看以下例子都可以用上面的正则表达式来表示:
# 任务六:找到以下所有字符串
text6 = '''
我师
我123师
我python师
我1+1=2这个算式是正确的师
'''3.问号“?”
问号表示它前面的子表达式0次或者1次。注意这里的问号是英文问号。
# 任务七:找到以下所有字符串
text7 = '''
我师
我师傅
我师傅傅
'''在这里例子中如果使用'我师傅?',将匹配到三个结果'我师', '我师傅', '我师傅'。第三行字符串实际上是“我师傅傅”,但是由于'?'的功能是匹配它前面的‘傅’0次或1次,所以最多只会匹配出一个‘傅’,导致最后一个匹配的结果也是‘我师傅’。
问号最大的最用是与点号和星号配合起来使用,构成“.*?”。通过正则表达式来提取信息的时候,用的最多的就是这个组合。
例如下面的字符串,除了最后一个,都可以用'我.*?师'来表示。
# 任务八:找到以下所有字符串
text8 = '''
我师
我123师
我python师
我1+1=2这个算式是正确的师
我的老师我的老师
'''匹配的结果是:'我师', '我123师', '我python师', '我1+1=2这个算式是正确的师', '我的老师', '我的老师'。
4.“.*”和“.*?”的区别
“.*”表示匹配一串任意长度的字符串任意次,它将匹配原来的整个字符串,除非在“.*”的前后加其他的符号来限定范围。例如“我.*师”,只会匹配“我”到“师”之间的任意内容。
如果在“.*”后面加一个问号,它将匹配它前面内容的0次或1次。于是,“.*?”的意思就是匹配一个能满足要求的最短字符串。在任务八中,正则表达式“我.*?师”在匹配字符串“我的老师我的老师”时,从‘我’开始匹配,匹配到第一个‘师’时整个表达式匹配成功,就不再继续向右匹配。但整个字符串还未结束,所以在下一次匹配时,是从第二个‘我’开始匹配,然后到第二个‘师’又匹配成功,从而返回第二个‘我的老师’。
“.*”代表一种贪婪的匹配模式,即尽可能多的匹配,就是看到合适的想要的,有多少要多少。“.*?”代表一种非贪婪模式,只要有一个满足的就结束了,其他再多的也不管。
关于贪婪模式和非贪婪有一篇文章分析的很意思,如有兴趣推荐阅读进一步了解。链接附在文章最后。[3]
5.反斜杠“\”
反斜杠在正则表达式中不能单独使用,需要和其他的字符配合使用来把特殊符号变成普通符号,或者把普通符号变成特殊符号。例如:
# 任务九:找到下面所有字符串
text9 = '''
我的密码藏在这里*abcedf*找到我了吗
我的密码藏在这里*123456*找到我了吗
'''如果将正则表达式写成'我的密码藏在这里‘*.*?*’找到我了吗'就会出错,因为星号在正则表达式中是有特殊意义的,不能直接使用星号来匹配星号,这时我们就需要用到反斜杠,来告诉计算机这个星号就是一个普通字符,不再具有正则表达式的意义。因此,正则表达式可以写成‘\*.*?\*’。
在正则表达式中将反斜杠和字符组合起来,指代特定的匹配模式
6.数字“\d”
正则表达式中使用“\d”来表示一位数字,d是digit(数字)的首字母。如果要提取2位数字,则用"\d\d"表示,如果是n位数字,则可以与*号组合起来使用,如“\d*”。
# 任务十:找到下面所有字符串
text10 = '''
我的密码藏在这里123456789,找到我了吗
我的密码藏在这里1,找到我了吗
我的密码藏在这里666666,找到我了吗
'''上看这些字符串我们用正则表达式可以表示为:'我的密码藏在这里\d*,找到我了吗'
7.括号“()”
前面讲到的符号仅仅能让正则表达式“表示”一串字符串,如果我们要将上面的三段密码单独提取出来该怎么办?这个问题我们就可以用到括号。括号的作用是将括号里面的内容提取出来。
我们使用正则表达式可以表示为:'我的密码藏在这里(\d*),找到我了吗'。我们得到的结果是:'123456789', '1', '666666'。
正则表达式有非常多的模式元素可供选择,见下表。[2]
| 模式 | 描述 |
|---|---|
| ^ | 匹配字符串的开头 |
| $ | 匹配字符串的末尾。 |
| . | 匹配任意字符,除了换行符,当re.DOTALL标记被指定时,则可以匹配包括换行符的任意字符。 |
| [...] | 用来表示一组字符,单独列出:[amk] 匹配 'a','m'或'k' |
| [^...] | 不在[]中的字符:[^abc] 匹配除了a,b,c之外的字符。 |
| re* | 匹配0个或多个的表达式。 |
| re+ | 匹配1个或多个的表达式。 |
| re? | 匹配0个或1个由前面的正则表达式定义的片段,非贪婪方式 |
| re{ n} | 匹配n个前面表达式。例如,"o{2}"不能匹配"Bob"中的"o",但是能匹配"food"中的两个o。 |
| re{ n,} | 精确匹配n个前面表达式。例如,"o{2,}"不能匹配"Bob"中的"o",但能匹配"foooood"中的所有o。"o{1,}"等价于"o+"。"o{0,}"则等价于"o*"。 |
| re{ n, m} | 匹配 n 到 m 次由前面的正则表达式定义的片段,贪婪方式 |
| a|b | 匹配a或b |
| (re) | 匹配括号内的表达式,也表示一个组 |
| (?imx) | 正则表达式包含三种可选标志:i, m, 或 x 。只影响括号中的区域。 |
| (?-imx) | 正则表达式关闭 i, m, 或 x 可选标志。只影响括号中的区域。 |
| (?: re) | 类似 (...), 但是不表示一个组 |
| (?imx: re) | 在括号中使用i, m, 或 x 可选标志 |
| (?-imx: re) | 在括号中不使用i, m, 或 x 可选标志 |
| (?#...) | 注释. |
| (?= re) | 前向肯定界定符。如果所含正则表达式,以 ... 表示,在当前位置成功匹配时成功,否则失败。但一旦所含表达式已经尝试,匹配引擎根本没有提高;模式的剩余部分还要尝试界定符的右边。 |
| (?! re) | 前向否定界定符。与肯定界定符相反;当所含表达式不能在字符串当前位置匹配时成功。 |
| (?> re) | 匹配的独立模式,省去回溯。 |
| \w | 匹配数字字母下划线 |
| \W | 匹配非数字字母下划线 |
| \s | 匹配任意空白字符,等价于 [\t\n\r\f]。 |
| \S | 匹配任意非空字符 |
| \d | 匹配任意数字,等价于 [0-9]。 |
| \D | 匹配任意非数字 |
| \A | 匹配字符串开始 |
| \Z | 匹配字符串结束,如果是存在换行,只匹配到换行前的结束字符串。 |
| \z | 匹配字符串结束 |
| \G | 匹配最后匹配完成的位置。 |
| \b | 匹配一个单词边界,也就是指单词和空格间的位置。例如, 'er\b' 可以匹配"never" 中的 'er',但不能匹配 "verb" 中的 'er'。 |
| \B | 匹配非单词边界。'er\B' 能匹配 "verb" 中的 'er',但不能匹配 "never" 中的 'er'。 |
| \n, \t, 等。 | 匹配一个换行符。匹配一个制表符, 等 |
| \1...\9 | 匹配第n个分组的内容。 |
| \10 | 匹配第n个分组的内容,如果它经匹配。否则指的是八进制字符码的表达式。 |
注意:表中re指的是表达式而不是字面的re这两个字母
正则表达式中的修饰符:
正则表达式可以包含一些可选标志修饰符来控制匹配的模式。修饰符被指定为一个可选的标志。多个标志可以通过按位 (|) 它们来指定。如 re.I | re.M 被设置成 I 和 M 标志:
| 修饰符 | 描述 |
|---|---|
| re.I | 使匹配对大小写不敏感 |
| re.L | 做本地化识别(locale-aware)匹配 |
| re.M | 多行匹配,影响 ^ 和 $ |
| re.S | 使 . 匹配包括换行在内的所有字符 |
| re.U | 根据Unicode字符集解析字符。这个标志影响 \w, \W, \b, \B. |
| re.X | 该标志通过给予你更灵活的格式以便你将正则表达式写得更易于理解。 |
二、在Python中使用正则表达式
在Python中使用正则表达式需要用到re模块。使用这个模块可以方便的通过正则表达式来从大段文本中提取有规律的信息。
要在Python使用re模块,首先要将该模块导入。
import re1.findall
Python的正则表达式模块包含一个findall方法,它能够以列表的形式返回所有满足要求的字符串。
findall函数的结构:re.findall(pattern,string,flags=0)
pattern表示正则表达式,string表示原来的字符串,flags表示正则表达式的修饰符。
findall的结果是一个列表,包含了所有匹配的结果。如果没有匹配到的内容,就会返回空列表。
现在我们解决最先提出的问题:
# 任务十二:找到所有密码
text12 = '''
我在学习正则表达式, password:123456, 它是一段字符串,
password:abcdefg,它能表示一段有规律的信息,password:111333,学习正则表达式应该是一件有意思的事情。
'''
password = re.findall(':(.*?),',text12)
print(password)所有的密码都被包在:分号和,逗号之间,正则表达式可构造为‘:(.*?),’。这里需要注意的是,表达式中分号和冒号与原字符串保持一致,都是是中文格式下的符号,其他符号是英文格式下的符号,不然匹配就会出错。这种时候为了防止格式不一致,在书写正则表达式建议直接从原字符串中复制出来。
输出的结果是:
['123456', 'abcdefg', '111333']2.search
search()的用法和findall()的用法一样,但是search()只返回第1个满足要求的字符串。
search方法如果匹配成功,返回的是一个正则表达式对象;如果没有匹配到任何数据,返回的结果是None。如果需要得到匹配的结果,则需要用到.group()这个方法来获取正则表达式中的值。
group括号中的参数为数字,当为0时是正则表达式匹配的整体结果,为1时是正则表达式中第1个括号中匹配到的内容,为2时是正则表达式中第2个括号中匹配到的内容,以此类推。
# 任务十二:找到所有密码
text13 = '''
我在学习正则表达式, 账号:python,密码:123456, 它是一段字符串,
'''
data = re.search('账号:(.*?),密码:(.*?),',text13S)
print(data.group(0))
print(data.group(1))
print(data.group(2))3.正则表达式练习
# 练习1:将字符串中的所有数值保留2位小数。
text14 = '''
23.10
111.77
abc123
32.771
59.1010
20.88
'''
# 拓展:如何找到只有2位小数的数值?
# 练习2:匹配字符串中的网址
text15 = '''
新浪微博
新浪新闻
新浪体育
新浪财经
'''三、正则表达式的提取技巧
1.先抓大再抓小
由于一些无效内容和有效内容可能具有相同的规则。这种情况下很容易把有效内容和无效内容混在一起,例如:
# 任务十三:排除无效信息
text16 = '''
有效信息:
password:123456
password:abcdef
password:888888
无效信息:
password:python
password:爬虫
'''有效密码和无效密码的前面都是“password:”,如果使用“password:(.*?)\n”,就会把有效信息和无效信息混在一起。
data = re.findall('password:(.*?)\n',text16)
print(data)
# 输出:
['123456', 'abcdef', '888888', 'python', '爬虫']
要解决这个问题,就需要使用先抓大再抓小的技巧。先把有效密码全部匹配出来,再从有效密码中匹配出密码。
data_all_useful = re.findall('有效信息:(.*?)无效信息', text16, re.S)
print(data_all_useful)
data = re.findall('password:(.*?)\n', data_all_useful[0], re.S)
print(data)
# 输出
['\npassword:123456\npassword:abcdef\npassword:888888\n']
['123456', 'abcdef', '888888']2.括号内和括号外
直接看例子:在下面的例子中,我们要找到所有年份在2017年的日期信息,这个时候正则表达式括号内的内容不能在只是‘.*?’,还需要将‘2017’识别条件放到括号的最前面。
# 任务十四:匹配出所有年份在2017年的日期信息
text17 = '''
date:2017-07-01
date:2017-08-01
date:2018-01-01
date:2019-01-10
date:2017-10-01
'''正则表达式如下:
data = re.findall('date:(2017.*?)\n',text17)
print(data)括号里面如果有其他普通字符,那么这些普通字符就会出现在获取的结果中。
以上内容只是正则表达式应用的部分举例说明,灵活运用正则表达式的匹配规则,可以帮助你从大段的文本中快速提取有用的信息。
四、实例:爬取百度贴吧的评论信息
在百度贴吧选择一个热门帖子,将其网页源代码复制下来,并保存在source.txt中,使用正则表达式找到所有发帖人姓名、发帖内容、发帖时间,并保存到csv文件中。
步骤:
(1)在浏览器中查看网页源代码
(2)使用Python读取文本文件
(3)应用正则表达式抓取信息
(4)使用Python写csv文件
1.在浏览器中获取网页的源代码
打开一篇百度热门帖子,在网页上点鼠标右键,点击“查看网页源代码”
在网页源代码页面中,“Ctrl+a”全选,“Ctrl+c”复制。
打开Pycharm,在工程中点击鼠标右键,新建一个名为‘source.txt’的文本文件。
 在Pycharm中新建文本文件
在Pycharm中新建文本文件
网页分析:
(1)按楼层将内容分块,找到每层楼的开始和结束:
使用Chrome浏览器的开发者工具,可以快速检查、追踪网页中的元素。
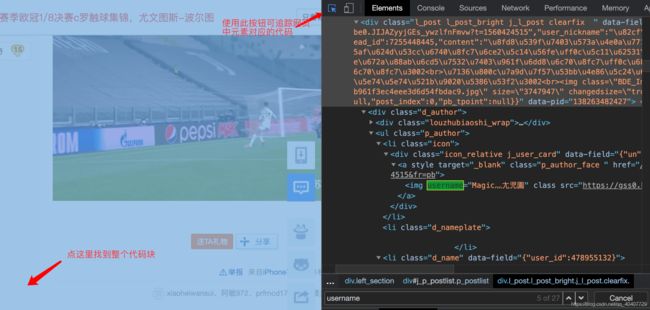 追踪网页中的元素
追踪网页中的元素
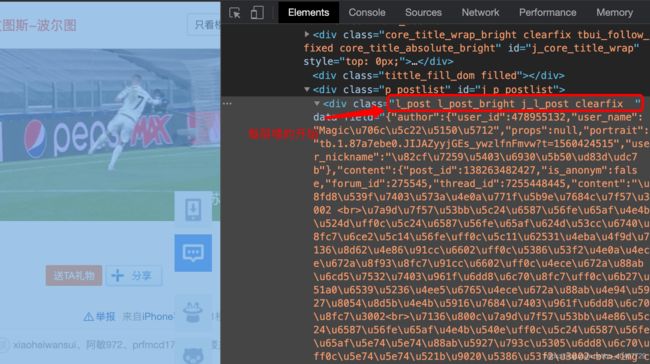 每层楼开始的地方
每层楼开始的地方
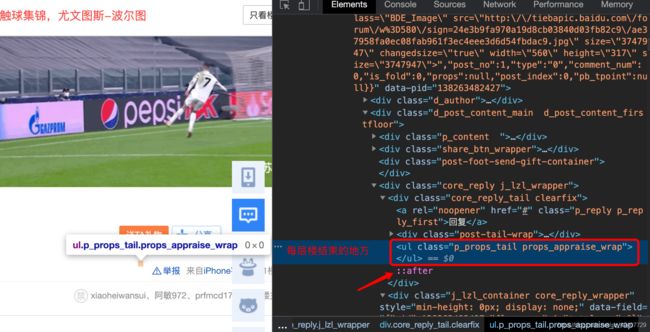 每层楼结束的地方
每层楼结束的地方
按楼层匹配内容的正则表达式:'
(2)找到发帖人用户名
使用追踪工具点击每层楼作者的头像,找到用户名在源代码中的位置。
匹配用户名的正则表达式:'username="(.*?)"'
(3)找到发帖时间
这里要特别说一下,发帖时间是在'tail-info">后面,但是在代码中的其他地方也有'tail-info",这里需要在括号内增加2021来区分我们要抓取的是时间。
匹配发帖时间的正则表达式:'tail-info">(2021.*?)<'
(4)找到内容信息
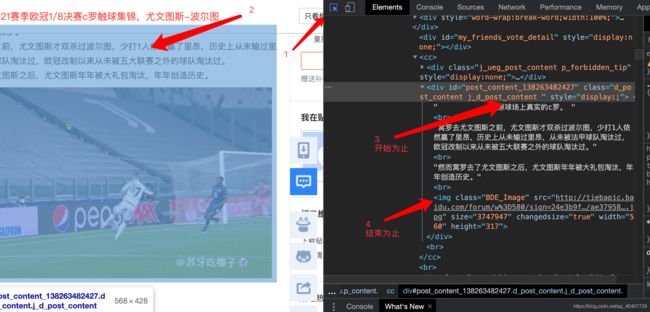 评论信息的开始和结束位置
评论信息的开始和结束位置
匹配发帖信息的正则表达式:'j_d_post_content " style="display:;">(.*?) 在Pycharm中新建一个名为baidutieba_spider.py的python文件。 首先导入re和csv两个模块。计划将用户名、发帖时间和帖子信息先保存在一个字典中,再将字典整体保存到列表中,这里我们创建一个名为result_list的空列表。 使用with-open来读取文件,将文件内容读取到content中。 最后使用csv模块将每层楼的用户名、发帖时间、发帖内容写入到tieba.csv中。 完整代码如下: 在百度贴吧中找到一个热门帖子,将每层楼的发帖人、发帖时间、发帖内容保存到csv文档中。 作业提交说明:按班级汇总后统一发至邮箱,一个班级一个压缩包,用“班级名称+日期(日期为4位数字,如0311)”。班级文件夹中,其中每位同学一个文件夹,文件夹用“学号+姓名”命名,文件夹不压缩,里面包含python和csv两个文件。 感言:每一次作业,希望大家都能认真对待,通过练习真正做到学懂悟透。加油~~!!! [1]Python爬虫开发从入门到实践.谢乾坤.人民邮电出版社 [2]Python正则re模块.https://www.cnblogs.com/CYHISTW/p/11363209.html [3]正则表达式之贪婪与非贪婪模式详解.https://www.cnblogs.com/admans/p/11955614.html2.读取文本文件
import re
import csv
result_list = []
with open('source','r',encoding='utf-8') as file:
content = file.read()3.应用正则表达式抓取信息
# 按楼层抓取整块发帖信息,发帖信息的源代码保存every_floor_reply的列表中,即一楼的信息存在every_floor_reply[0]中
every_floor_reply = re.findall('4.保存csv文件
with open('tieba.csv','w',encoding='utf-8') as f:
writer =csv.DictWriter(f,fieldnames=['username','content','reply_time'])
writer.writeheader()
writer.writerows(result_list) 写入数据后的csv文件
写入数据后的csv文件
import re
import csv
result_list = []
with open('source','r',encoding='utf-8') as file:
content = file.read()
# 按楼层抓取整块发帖信息,发帖信息的源代码保存every_floor_reply的列表中,即一楼的信息存在every_floor_reply[0]中
every_floor_reply = re.findall('五、项目实战