Spark基础
✎ 学习目标
1.了解Spark的特点
2.掌握Spark集群的搭建和配置及架构
3.理解Spark作业提交的工作原理
4.掌握Spark HA集群的搭建和配置
Spark于2009年诞生于美国加州大学伯克利分校的AMP实验室,它是一个可应用于大规模数据处理的统一分析引擎。Spark不仅计算速度快,而且内置了丰富的API,使得我们能够更加容易编写程序。
Spark的概述
Spark在2013年加入Apache孵化器项目,之后获得迅猛的发展,并于2014年正式成为Apache软件基金会的顶级项目。Spark生态系统已经发展成为一个可应用于大规模数据处理的统一分析引擎,它是基于内存计算的大数据并行计算框架,适用于各种各样的分布式平台的系统。在Spark生态圈中包含了Spark SQL、Spark Streaming、GraphX、MLlib等组件。
**Spark Core:**Spark核心组件,实现了Spark的基本功能,包含任务调度、内存管理、错误恢复、与存储系统交互等模块。Spark Core中还包含对弹性分布式数据集的API定义。
Spark SQL:用来操作结构化数据的核心组件,通过Spark SQL可直接查询Hive、HBase等多种外部数据源中的数据。Spark SQL的重要特点是能够统一处理关系表和RDD。
Spark Streaming:Spark提供的流式计算框架,支持高吞吐量、可容错处理的实时流式数据处理,其核心原理是将流数据分解成一系列短小的批处理作业。
MLlib:Spark提供的关于机器学习功能的算法程序库,包括分类、回归、聚类、协同过滤算法等,还提供了模型评估、数据导入等额外的功能。
GraphX:Spark提供的分布式图处理框架,拥有对图计算和图挖掘算法的API接口及丰富的功能和运算符,便于对分布式图处理的需求,能在海量数据上运行复杂的图算法。
独立调度器、Yarn、Mesos:集群管理器,负责Spark框架高效地在一个到数千个节点之间进行伸缩计算的资源管理。
Spark的特点:
Spark计算框架在处理数据时,所有的中间数据都保存在内存中,从而减少磁盘读写操作,提高框架计算效率。同时Spark还兼容HDFS、Hive,可以很好地与Hadoop系统融合,从而弥补MapReduce高延迟的性能缺点。所以说,Spark是一个更加快速、高效的大数据计算平台。
Spark应用场景
数据科学,数据工程师可以利用Spark进行数据分析与建模,由于Spark具有良好的易用性,数据工程师只需要具备一定的SQL语言基础、统计学、机器学习等方面的经验,以及使用Python、Matlab或者R语言的基础编程能力,就可以使用Spark进行上述工作。
数据处理,大数据工程师将Spark技术应用于广告、报表、推荐系统等业务中,在广告业务中,利用Spark系统进行应用分析、效果分析、定向优化等业务,在推荐系统业务中,利用Spark内置机器学习算法训练模型数据,进行个性化推荐及热点点击分析等业务。
Spark与Hadoop对比
1.编程方式
Hadoop的MapReduce计算数据时,要转化为Map和Reduce两个过程,从而难以描述复杂的数据处理过程;而Spark的计算模型不局限于Map和Reduce操作,还提供了多种数据集的操作类型,编程模型比MapReduce更加灵活。
2.数据存储
Hadoop的MapReduce进行计算时,每次产生的中间结果都存储在本地磁盘中;而Spark在计算时产生的中间结果存储在内存中。
环境准备
由于Spark仅仅是一种计算框架,不负责数据的存储和管理,因此,通常都会将Spark和Hadoop进行统一部署,由Hadoop中的HDFS、HBase等组件负责数据的存储管理,Spark负责数据计算。
安装Spark集群前,需要安装Hadoop环境,本教材采用如下配置环境。
Linux系统:CentOS_6.7版本
Hadoop:2.7.4版本
JDK:1.8版本
Spark:2.3.2版本
Spark的部署方式
Spark部署方式有三种:Mesos模式,Standalone
模式,YARN模式
Standalone模式:
Standalone模式被称为集群单机模式。
该模式下,Spark集群架构为主从模式,即一台Master节点与多台Slave节点,Slave节点启动的进程名称为Worker,存在单点故障的问题。
Mesos模式:
Mesos模式被称为Spark on Mesos模式。
Mesos是一款资源调度管理系统,为Spark提供服务,由于Spark与Mesos存在密切的关系,因此在设计Spark框架时充分考虑到对Mesos的集成。
Yarn模式:
Yarn模式被称为Spark on Yarn模式,即把Spark作为一个客户端,将作业提交给Yarn服务。
由于在生产环境中,很多时候都要与Hadoop使用同一个集群,因此采用Yarn来管理资源调度,可以提高资源利用率。
Spark集群安装部署
本书将在Standalone模式下,进行Spark集群的安装部署。
规划的Spark集群包含一台Master节点和两台Slave节点。其中,主机名hadoop01是Master节点,hadoop02和hadoop03是Slave节点。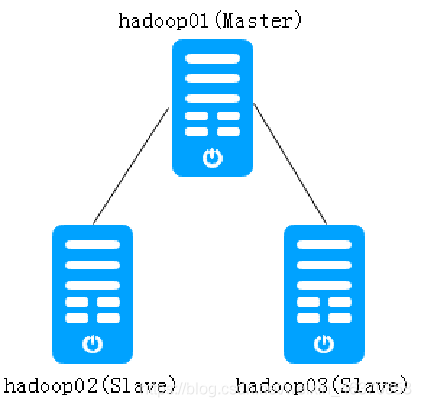
1、下载Spark安装包
2、解压Spark安装包
首先将下载的spark-2.3.2-bin-hadoop2.7.tgz安装包上传到主节点hadoop01的/export/software目录下,然后解压到/export/servers/目录,解压命令如下。
$ tar -zxvf spark-2.3.2-bin-hadoop2.7.tgz -C /export/servers/
3、修改配置文件
(1)将spark-env.sh.template配置模板文件复制一份并命名为spark-env.sh
(2)修改spark-env.sh文件,在该文件添加以下内容:
#配置java环境变量
export JAVA_HOME=/export/servers/jdk
#指定Master的IP
export SPARK_MASTER_HOST=hadoop01
#指定Master的端口
export SPARK_MASTER_PORT=7077
(3)复制slaves.template文件,并重命名为slaves
(4)修改spark-env.sh文件,在该文件添加以下内容:通过“vi slaves”命令编辑slaves配置文件,主要是指定Spark集群中的从节点IP,由于在hosts文件中已经配置了IP和主机名的映射关系,因此直接使用主机名代替IP,添加内容如下。
hadoop02
hadoop03
4、分发文件
修改完成配置文件后,将spark目录分发至hadoop02和hadoop03节点
$ scp -r /export/servers/spark/ hadoop02:/export/servers/
$ scp -r /export/servers/spark/ hadoop03:/export/servers/
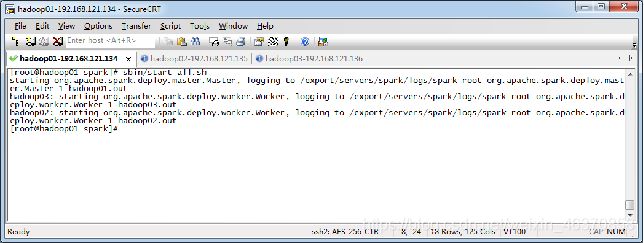
5、启动Spark集群
$ sbin/start-all.sh
集群进程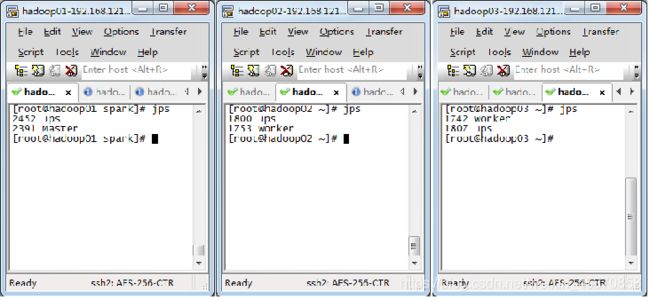
Spark集群管理页面
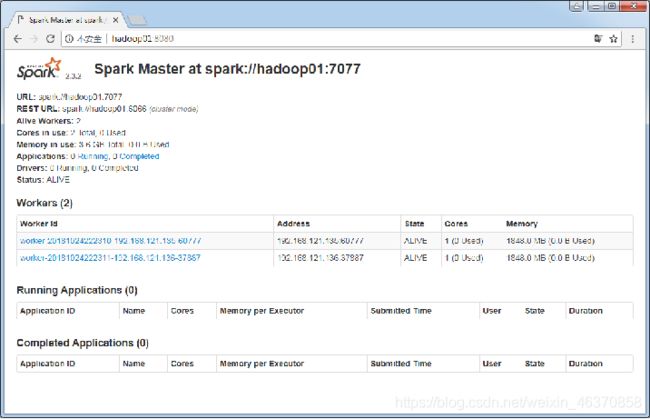
Spark HA集群部署
Spark Standalone集群是主从架构的集群模式,由于存在单点故障问题,解决这个问题需要用到Zookeeper服务,其基本原理是将Standalone集群连接到同一个Zookeeper实例并启动多个Master节点,利用Zookeeper提供的选举和状态保存功能,可以使一台Master节点被选举,另一台Master节点处于Standby状态。当活跃的Master发生故障时,Standby状态的Master就会被激活,恢复集群调度,整个恢复的过程可能需要1-2分钟。
- 启动Zookeeper集群服务。
- 在spark-env.sh配置文件中注释Master节点的配置参数,并指定Spark使用Zookeeper管理。
- 在hadoop01主节点启动Spark集群,在hadoop02节点再次启动Master服务。
- 关闭hadoop01节点中的Master进程,测试Spark HA集群。
基本概念
Application(应用)
Spark上运行的应用。Application中包含一个驱动器进程和集群上的多个执行器进程。
Driver Program(驱动器)
运行main()方法并创建SparkContext的进程。
Cluster Manager(集群管理器)
用于在集群上申请资源的外部服务(如:独立部署的集群管理器、Mesos或者Yarn)。
Worker Node(工作节点)
集群上运行应用程序代码的任意一个节点。
Executor(执行器)
在集群工作节点上为某个应用启动的工作进程,该进程负责运行计算任务,并为应用程序存储数据。
Task(任务)
运行main()方法并创建SparkContext的进程。
Job(作业)
一个并行计算作业,由一组任务组成,并由Spark的行动算子(如:save、collect)触发启动。
Stage(阶段)
每个Job可划分为更小的Task集合,每组任务被称为Stage
Spark集群运行架构
Spark运行架构主要由SparkContext、Cluster Manager和Worker组成,其中Cluster Manager负责整个集群的统一资源管理,Worker节点中的Executor是应用执行的主要进程,内部含有多个Task线程以及内存空间,下面通过图2-12深入了解Spark运行基本流程。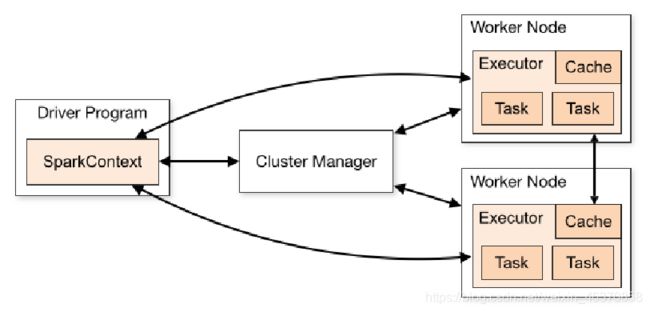
Spark运行基本流程
Spark应用在集群上作为独立的进程组来运行,具体运行流程如下所示。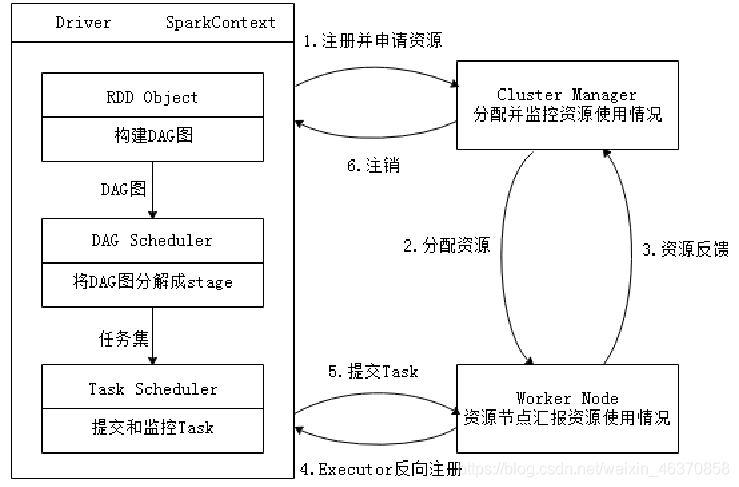
步骤1:当一个Spark应用被提交时,根据提交参数创建Driver进程,Driver进程初始化SparkContext对象,由SparkContext负责和Cluster Manager的通信以及资源的申请、任务的分配和监控等。
步骤2:Driver进程向Cluster Manager申请资源,Cluster Manager接收到Application的注册请求后,会使用自己的资源调度算法,在Spark集群的Worker节点上,通知Worker为应用启动多个Executor。
步骤3:Executor创建后,会向Cluster Manager进行资源及状态的反馈,便于Cluster Manager对Executor进行状态监控,如果监控到Executor失败,则会立刻重新创建。
步骤4:Executor会向SparkContext反向注册申请Task。
步骤5:Task Scheduler将Task发送给Worker进程中的Executor运行并提供应用程序代码。
步骤6:当程序执行完毕后写入数据,Driver向Cluster Manager注销申请的资源。
运行Spark官方示例SparkPi
Spark集群已经部署完毕,我们可以通过运行Spark官方示例SparkPi,体验Spark集群提交任务的流程。执行下述代码块中的命令,提交SparkPi程序。
bin/spark-submit
--class org.apache.spark.examples.SparkPi
--master spark://hadoop01:7077
--executor-memory 1G
--total-executor-cores 1
examples/jars/spark-examples_2.11-2.3.2.jar
10
提交Spark作业后,观察Spark集群管理界面,其中“Running Applications”列表表示当前Spark集群正在计算的作业,执行几秒后,刷新界面,在Completed Applications表单下,可以看到当前应用执行完毕,返回控制台查看输出信息,出现了“Pi is roughly 3.140691140691141”,说明Pi值已经被计算完毕。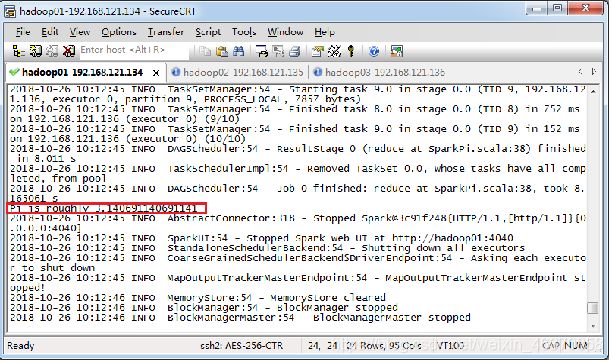
启动Spark-Shell
Spark-Shell是一个强大的交互式数据分析工具,初学者可以很好的使用它来学习相关API,用户可以在命令行下使用Scala编写Spark程序,并且每当输入一条语句,Spark-Shell就会立即执行语句并返回结果,这就是我们所说的REPL(Read-Eval-Print Loop,交互式解释器),Spark-Shell支持Scala和Python,如果需要进入Python语言的交互式执行环境,只需要执行“pyspark”命令即可。
运行Spark-Shell命令
在spark/bin目录中,执行下列命令进入Spark-Shell交互环境:bin/spark-shell --master
–master”表示指定当前连接的Master节点
用于指定Spark的运行模式
可取的详细值如下所示。

运行Spark-Shell读取HDFS文件
- 整合Spark和HDFS。
- 启动Hadoop、Spark服务。
- 启动Spark –Shell编写程序。
- 退出Spark-Shell客户端。
本地模式执行Spark程序
步骤一:创建Maven项目
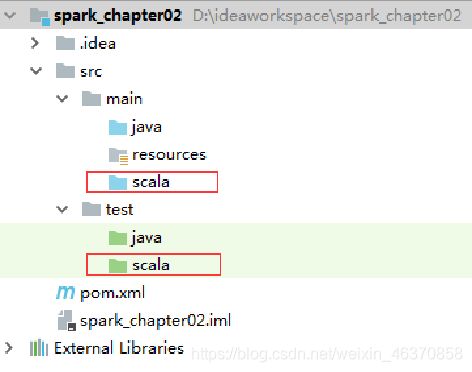
创建一个名为“spark_chapter02”的Maven项目,然后在main和test目录下分别创建一个名称为scala的文件夹。
将文件夹标记为资源文件夹类型 :
步骤二:添加Spark相关依赖,打包插件
设置依赖的版本号
添加了Scala、Hadoop和Spark相关的依赖
步骤三:编写代码,查看结果
在main目录的scala文件夹中,创建WordCount.scala文件实现词频统计。 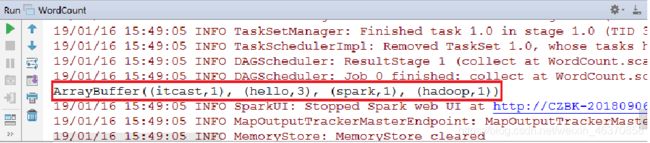
集群模式执行Spark程序
步骤一:添加打包插件
注意:如果在创建Maven工程中选择Scala原型模板,上述插件会自动创建。这些插件的主要功能是方便开发人员进行打包。
步骤二:修改代码,打包程序
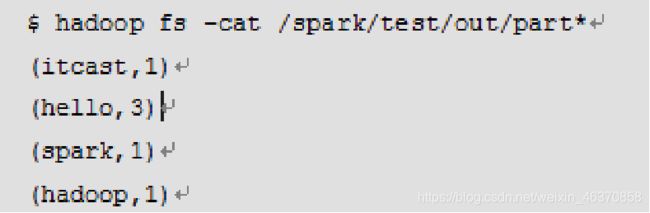
步骤三:执行提交命令“spark-submit”
加个关注吧 持续更新!
加个关注吧 持续更新!
加个关注吧 持续更新!
Thank you !Thank you !Thank you !