1.导入库
import pandas as pd
import numpy as np
2.创建一个序列
s = pd.Series([1,3,6,np.nan,44,1])
s

dates = pd.date_range('20201010',periods = 6)
dates

3.创建一个dataframe
df = pd.DataFrame(np.random.randn(6,4),index = dates ,columns= ['a','b','c','d'])
df

df1 = pd.DataFrame(np.arange(12).reshape((3,4)))
df1

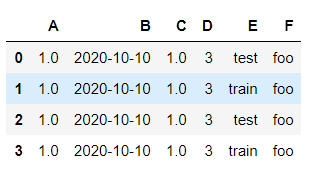
df2 = pd.DataFrame({
'A':1.,
'B':pd.Timestamp('20201010'),
'C':pd.Series(1,index=list(range(4)),dtype='float32'),
'D':np.array([3]*4,dtype = 'int32'),
'E':pd.Categorical(['test','train','test','train']),
'F':'foo'
})
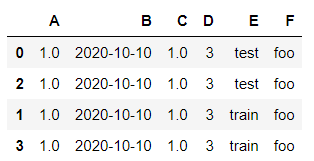
df2
4.一些基本操作
df2.dtypes

df2.index
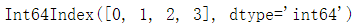
df2.values

df2.describe()

df2.T

df2.sort_index(axis=1,ascending=False)
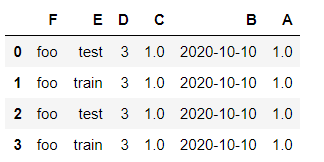
df2.sort_values(by = 'E')
5.选择数据
dates = pd.date_range('20201010',periods= 6)
df = pd.DataFrame(np.arange(24).reshape((6,4)),index= dates,columns=['A','B','C','D'])
df

print(df['A'])

df[0:3]

df.loc['20201010']

df.loc[:,['A','C']]
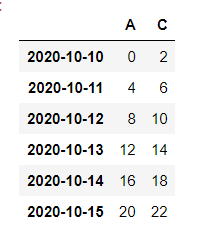
df.iloc[3:5,1:3]

df.iloc[[1,3,5],1:3]

df[df.A > 8]

6.赋值
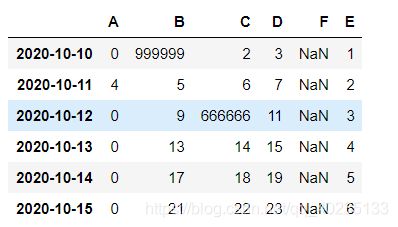
df.iloc[2,2] = 666666
df.loc['20201010','B'] = 999999
df.A[df.A > 4] = 0
df['F'] = np.nan
df['E'] = pd.Series([1,2,3,4,5,6],index=pd.date_range('20201010',periods=6))
df
7.处理丢失数据
dates = pd.date_range('20201010',periods=6)
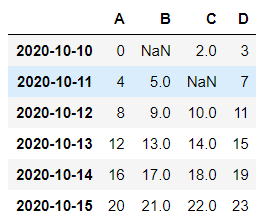
df = pd.DataFrame(np.arange(24).reshape((6,4)),index= dates,columns=['A','B','C','D'])
df.iloc[0,1] = np.nan
df.iloc[1,2] = np.nan
df
df.dropna(axis=0,how = 'any')
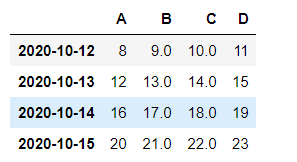
df.fillna(value= 0 )

np.any(df.isnull()) == True

8.pandas导入导出数据
data = pd.read_csv('student.csv')
data

data.to_pickle('student.pickle')
9.合并concat
df1 = pd.DataFrame(np.ones((3,4))*0,columns=['a','b','c','d'])
df2 = pd.DataFrame(np.ones((3,4))*1,columns=['a','b','c','d'])
df3 = pd.DataFrame(np.ones((3,4))*2,columns=['a','b','c','d'])
res = pd.concat([df1,df2,df3],axis=0,ignore_index = True)
res
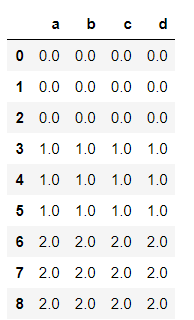
df1 = pd.DataFrame(np.ones((3,4))*0,columns=['a','b','c','d'],index = [1,2,3])
df2 = pd.DataFrame(np.ones((3,4))*1,columns=['b','c','d','e'],index = [2,3,4])
print(df1)
print(df2)

res = pd.concat([df1,df2],join='outer')
res

res = pd.concat([df1,df2],join='inner',ignore_index = True)
res

10.append合并
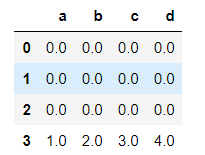
df1 = pd.DataFrame(np.ones((3,4))*0,columns=['a','b','c','d'])
df2 = pd.DataFrame(np.ones((3,4))*1,columns=['a','b','c','d'])
df3 = pd.DataFrame(np.ones((3,4))*1,columns=['a','b','c','d'],index = [2,3,4])
res = df1.append([df2,df3],ignore_index = True)
res

s1 = pd.Series([1,2,3,4],index=['a','b','c','d'])
res = df1.append(s1,ignore_index=True)
res
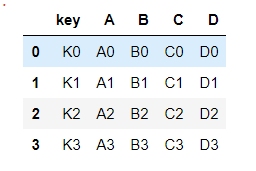
left = pd.DataFrame({
'key': ['K0', 'K1', 'K2', 'K3'],
'A': ['A0', 'A1', 'A2', 'A3'],
'B': ['B0', 'B1', 'B2', 'B3']})
right = pd.DataFrame({
'key': ['K0', 'K1', 'K2', 'K3'],
'C': ['C0', 'C1', 'C2', 'C3'],
'D': ['D0', 'D1', 'D2', 'D3']})
print(left)
print(right)

res = pd.merge(left,right,on = 'key')
res
left = pd.DataFrame({
'key1': ['K0', 'K0', 'K1', 'K2'],
'key2': ['K0', 'K1', 'K0', 'K1'],
'A': ['A0', 'A1', 'A2', 'A3'],
'B': ['B0', 'B1', 'B2', 'B3']})
right = pd.DataFrame({
'key1': ['K0', 'K1', 'K1', 'K2'],
'key2': ['K0', 'K0', 'K0', 'K0'],
'C': ['C0', 'C1', 'C2', 'C3'],
'D': ['D0', 'D1', 'D2', 'D3']})
res = pd.merge(left,right,on = ['key1','key2'])
res

11.merge合并
df1 = pd.DataFrame({
'col1':[0,1], 'col_left':['a','b']})
df2 = pd.DataFrame({
'col1':[1,2,2],'col_right':[2,2,2]})
print(df1)
print(df2)
res = pd.merge(df1, df2, on='col1', how='outer', indicator=True)
res = pd.merge(df1, df2, on='col1', how='outer', indicator='indicator_column')
res

left = pd.DataFrame({
'A': ['A0', 'A1', 'A2'],
'B': ['B0', 'B1', 'B2']},
index=['K0', 'K1', 'K2'])
right = pd.DataFrame({
'C': ['C0', 'C2', 'C3'],
'D': ['D0', 'D2', 'D3']},
index=['K0', 'K2', 'K3'])
print(left)
print(right)
res = pd.merge(left, right, left_index=True, right_index=True, how='outer')
res

boys = pd.DataFrame({
'k': ['K0', 'K1', 'K2'], 'age': [1, 2, 3]})
girls = pd.DataFrame({
'k': ['K0', 'K0', 'K3'], 'age': [4, 5, 6]})
res = pd.merge(boys, girls, on='k', suffixes=['_boy', '_girl'], how='inner')
print(res)

12.pandas 画图
import matplotlib.pyplot as plt
data = pd.Series(np.random.randn(1000),index = np.arange(1000))
data = data.cumsum()
data

data.plot()
plt.show()
data = pd.DataFrame(np.random.randn(1000,4),
index = np.arange(1000),
columns=list('ABCD'))
data = data.cumsum()
data.plot()
plt.show()

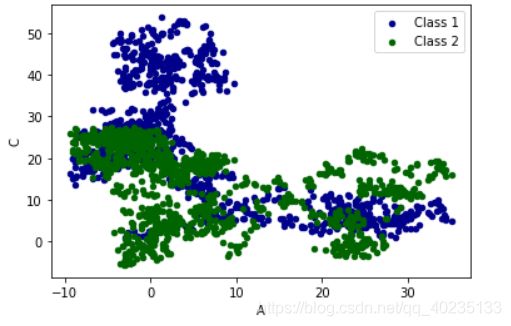
ax = data.plot.scatter(x='A',y='B',color = 'DarkBlue',label = 'Class 1')
data.plot.scatter(x='A',y='C',color = 'DarkGreen',label = 'Class 2',ax =ax)
plt.show()