HashMap简介
JDK1.8后的HashMap在底层数据结构上采用数组+链表/红黑树,通过散列映射来存储键值对数据,因为在查询上使用散列码hashcode,所以在查询上的访问速度较快。HashMap可以存储值为null的键(key)和值(value),但是null作为键只能有一个,而null作为值可以有多个。它是无序的、非线程安全的。
HashMap底层数据结构
在JDK1.7及之前的HashMap底层是由数组+链表构成,也就是链表散列。其中,数组是HashMap的主体,链表则是主要为了解决哈希冲突而存在的。
JDK1.8以后的HashMap在解决哈希冲突时有了较大的变化,当链表长度大于阈值(默认为8)(将链表转换为红黑树之前会判断,如果当前数组的长度小于64,那么会选择先进行数组扩容,而不是直接转换为红黑树)时,将链表转化为红黑树,以减少搜索时间。
HashMap底层实现
通过key的hashcode经过扰动函数处理后得到hash值,然后通过(n-1) & hash判断当前元素存放的位置(这里的n指的是数组的长度),如果当前位置存在元素的话,就判断该元素与要存入的元素的hash值以及key是否相同,如果相同的话,直接覆盖;不相同就通过拉链法解决冲突。
扰动函数:hashmap的hash方法,使用hash方法即扰动函数为了防止一些实现比较差的hashcode()方法,换句话说扰动函数可以减少碰撞。
拉链法:将链表和数组相结合。即创建一个链表数组,数组中每一格就是一个链表。若遇到哈希冲突,则将冲突的值加到链表中即可。
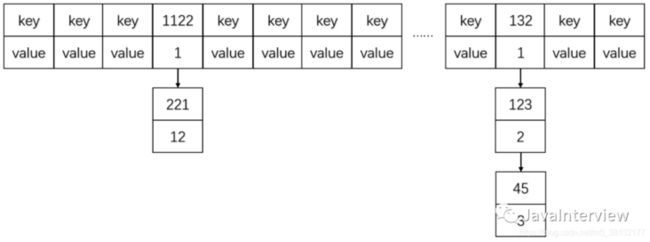
HashMap的长度为什么是2的幂次方
hash值的取值范围是2147483648到2147483647,大概有40亿的映射空间,只要hash函数映射的比较均匀松散,一般很难出现碰撞。但是一个长度为40亿的数组,内存是放不下的。因此这个散列值不能直接拿来用,需要先对数组的长度进行取模运算,得到的余数用来作为存放的位置也就是对应的数组下标。这个取模运算计算方法是“(n-1)&hash”(n代表数组长度)。
这个时候有人要问:取模操作不是%吗?
原因:采用二进制位操作&,相对于%能够提高运算效率。因此,取余(%)操作中如果除数是2的幂次则等价于与其除数减一的与(&)操作,也就是说,hash%length==hash&(length-1),而这个等式成立的前提是length是2的n次方。
HashMap的扩容机制
要了解HashMap的扩容过程,首先需要了解HashMap中的变量
Node:链表节点,包含了key,value,hash值,next指针四个元素;
table:Node类型的数组,里面的元素是链表,用来存放HashMap元素的实体;
size:表示当前HashMap包含的键值对数量
final float loadFactor:负载因子,用于扩容
int threshold:扩容的阈值,决定了HashMap何时扩容,以及扩容后的大小,一般等于table * loadFactor
static final float DEFAULT_LOAD_FACTORY = 0.75f:默认的负载因子
static final int DEFAULT_INITIAL_CAPACITY = 1<<4:默认的table初始容量(16)
static final int TREEIFY_THRESHOLD = 8:链表长度大于该参数转红黑树
statci final int UNTREEIFY_THRESHOLD = 6:当树的节点数小于等于该参数转成链表
何时进行扩容?
当当前存入的数据容量大于阈值threshold时需要进行resize扩容。而threshold取决于两个因素:当前长度容量capacity以及负载因子loadFactory。
threshold = capacity * loadFactory
HashMap扩容可以分为三种情况
第一种:使用默认构造方法初始化HashMap。HashMap在一开始初始化的时候会返回一个空的table,并且threshold为0。因此第一次扩容的容量为默认值DEFAULT_INITIAL_CAPACITY = 1<<4,因此threshold = DEFAULT_INITIAL_CAPACITY * DEFAULT_LOAD_FACTOR = 12。
第二种:指定初始容量的方法构造HashMap。初始容量等于threshold,接着threshold = 当前的容量(threshold) * DEFAULT_LOAD_FACTOR。
第三种:HashMap不是第一次扩容。如果HashMap已经扩容过的话,那么每次table的容量以及threshold量为原有的两倍。
下面是HashMap扩容机制核心方法Node
/**
* Initializes or doubles table size. If null, allocates in
* accord with initial capacity target held in field threshold.
* Otherwise, because we are using power-of-two expansion, the
* elements from each bin must either stay at same index, or move
* with a power of two offset in the new table.
*
* @return the table
*/
final Node[] resize() {
Node[] oldTab = table;//首次初始化后的table为null
int oldCap = (oldTab == null) ? 0 : oldTab.length;
int oldThr = threshold;//默认构造器下的阈值为0
int newCap, newThr = 0;
if (oldCap > 0) { //table扩容过
//当前table容量大于最大值的时候返回当前table
if (oldCap >= MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return oldTab;
}
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
//table的容量乘以2,threshold的值也乘以2
newThr = oldThr << 1; // double threshold
}
else if (oldThr > 0) // initial capacity was placed in threshold
//使用带有初始容量的构造器时,table容量为初始化得到的threshold
newCap = oldThr;
else { // zero initial threshold signifies using defaults
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
if (newThr == 0) {
//使用带有初始容量的构造器在此处进行扩容
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
threshold = newThr;
@SuppressWarnings({"rawtypes","unchecked"})
Node[] newTab = (Node[])new Node[newCap];
table = newTab;
if (oldTab != null) {
for (int j = 0; j < oldCap; ++j) {
Node e;
if ((e = oldTab[j]) != null) {
oldTab[j] = null;
if (e.next == null)
//当前index没有发生hash冲突,直接对2取模,即移位运算hash & (2^n-1)
//扩容都是按照2的幂次方进行扩容,因此newCap = 2^n
newTab[e.hash & (newCap - 1)] = e;
else if (e instanceof TreeNode)
//当前index对应的节点为红黑树,当树的个数小于等于UNTREEIFY_THRESHOLD则转成链表
((TreeNode)e).split(this, newTab, j, oldCap);
else { // preserve order
把当前index对应的链表分成两个链表,减少扩容的迁移量
Node loHead = null, loTail = null;
Node hiHead = null, hiTail = null;
Node next;
do {
next = e.next;
if ((e.hash & oldCap) == 0) {
//扩容后不需要移动的链表
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
else {
//扩容后需要移动的链表
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
if (hiTail != null) {
hiTail.next = null;
//扩容长度为当前index位置+旧的容量
newTab[j + oldCap] = hiHead;
}
}
}
}
}
return newTab;
}
}
HashMap与HashSet、HashTable的区别
HashMap和HashSet
HashSet底层是基于HashMap实现的,且都是非线程安全的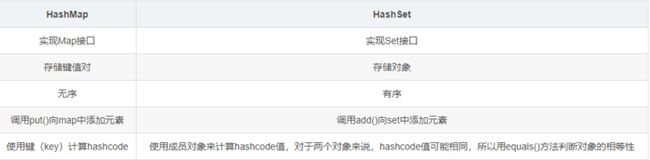
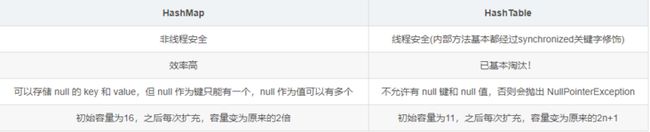
HashMap和HashTable
ConcurrentHashMap
JDK1.7
由Segment数组+HashEntry数组+链表实现: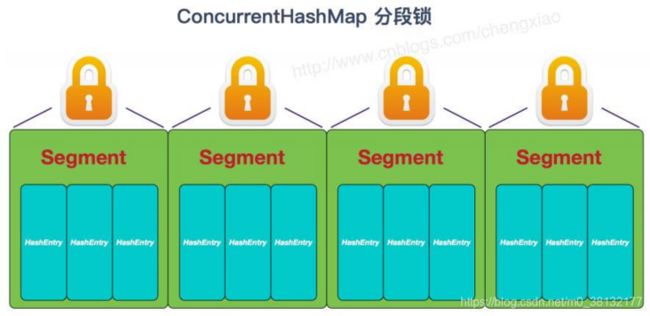
ConcurrentHashMap分段锁对整个桶数组进行了分割分段(segment),每一把锁只锁容器的其中一部分数据,多线程访问容器里不同数据段的数据,就不会存在锁竞争,提高并发访问率。
JDK1.8
到了JDK1.8的时候已经摒弃了segment的概念,而是直接用Node 数组+链表+红黑树实现。同时采用CAS 和 synchronized 来保证并发安全,整个看起来就像是优化且线程安全的HashMap。
synchronized 只锁定当前链表或红黑二叉树的首节点,这样只要 hash 不冲突,就不会产生并发,效率又提升 N 倍。
集合框架底层数据结构总结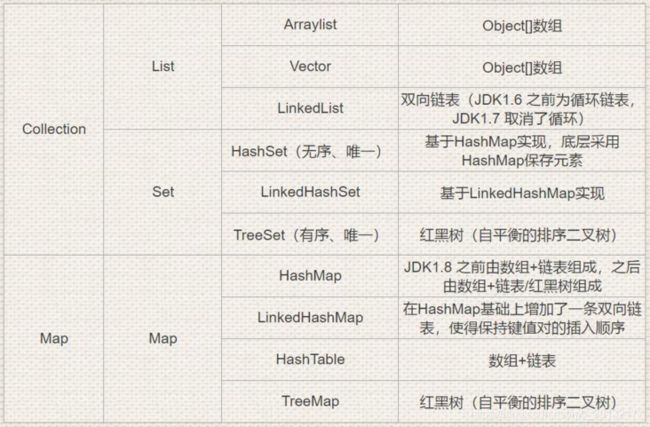
那么如何选用集合呢?
主要根据集合的特点来选用,比如我们需要根据键值获取到元素值时就选用 Map 接口下的集合,需要排序时选择 TreeMap ,不需要排序时就选择 HashMap ,需要保证线程安全就选用ConcurrentHashMap 。
当我们只需要存放元素值时,就选择实现 Collection 接口的集合,需要保证元素唯一时选择实现 Set 接比的集合比如 TreeSet 或 HashSet ,不需要就选择实现 List 接口的比如 ArrayList 或 LinkedList ,然后再根据实现这些接口的集合的特点来选用。
最后
在文章的最后作者为大家整理了很多资料!包括java核心知识点+全套架构师学习资料和视频+一线大厂面试宝典+面试简历模板+阿里美团网易腾讯小米爱奇艺快手哔哩哔哩面试题+Spring源码合集+Java架构实战电子书等等!有需要的朋友可以关注公众号:前程有光回复资料自动下载