目录
- 介绍
KHR_mesh_quantization和EXT_meshopt_compression - 用途、用法
- 性能(压缩、加载、解析)
- 可用(场景、范围)
- 缺点
- 猜想未来改进方向
- 总结
介绍
GLTF的压缩,估计都知道Draco,因为适配GLTFLoader到小程序的原因,发现还有不少其他压缩扩展,比如KHR_mesh_quantization和EXT_meshopt_compression

KHR_mesh_quantization
Quantization也就是向量化,是把用浮点数表示的数据使用整形数据表示,方便压缩存储,但是会丢失精度。之前在tfjs的模型有见过类似的方法,gltf的网格数据都是使用浮点数储存,一个单精度浮点数占32位4byte,一个顶点3个数12byte,纹理坐标8byte,法线,12byte,正切空间16byte,一个顶点附带的信息数量就需要48byte,那么使用通过该扩展,使用SHORT来保存顶点坐标,纹理坐标4byte,使用BYTE存储法线坐标4byte, 正切空间4byte(为了不破坏标准都是4的倍数byte),一共20byte所以经过向量化之后的网格能有大概58.4%的压缩。
EXT_meshopt_compression
该扩展于r122进入three。其压缩的pipeline如下。其中第五步则是上面的向量化。

KHR_DRACO_MESH_COMPRESSION
https://github.com/google/draco 进一步了解可以阅读大佬的分析,默认压缩参数比上面的都激进些
由于wasm的支持和js的体积和worker数量限制问题,小程序下就不太合适了。js版decoder比three都要大

用法
KHR_mesh_quantization和EXT_meshopt_compression可以使用同一个工具gltfpack
> npm i -g gltfpack
# gltfpack命令行工具是C项目构建出WASM执行的,目测未来会有更多wasm这类项目产出
# KHR的优化版的basis trancoder是使用assemblyscript编译成wasm
# 转成KHR_mesh_quantization
> gltfpack -i model.glb -o out.glb
# EXT_meshopt_compression只需加个-cc参数即可
> gltfpack -i model.glb -o out.glb -cc使用gltfpack的好处是向量化的参数是可以调整的(需要meshopt扩展),比如法线需要更高精度的话修改-vn即可,具体使用阅读gltfpack -h即可
KHR_DRACO_MESH_COMPRESSION可以使用gltf-pipeline
> npm i -g gltf-pipeline
> gltf-pipeline -i model.glb -o out.glb -d同样也可以调整draco的向量化参数
性能(压缩、加载、解析)
那么下来就需要对比其压缩网格的性能对比了
使用的模型是来源于glTF-Sample-Models


这里可以看到仅仅有顶点数据ReciprocatingSaw.glb则是draco是最好的,其实原因也很简单,Draco默认压缩参数比meshQuan激进得多,但是有动画的BrainStem.glb meshOpt是最好的。WaterBottle.glb是都差不太多,因为顶点数量有限,纹理占据大量主要体积。
那么由于默认参数是不相同的,对比起来draco就有优势了,所以把其他需要相同压缩参数重新对比下,这次仅仅需要对比BrainStem和ReciprocatingSaw即可,这里把gltfpack参数向draco对齐
> gltfpack -i model.glb -o out.glb -vp 11 -vt 10
> gltfpack -i model.glb -o out.glb -vp 11 -vt 10 -cc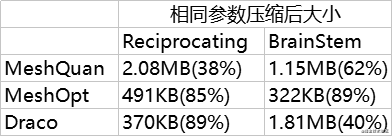
可以看到即便修改了参数,MeshQuan大小还是没有变,因为已经成为标准的了,向量化的参数已经是固定无法修改了,但是MeshOpt有些许提升。
Decoder加载
使用某个压缩方案,除了需要对比压缩大小,还得对比decoder的加载难易程度(web,小程序等环境下),还有DracoLoader十几KB还没算进去

值得注意是MeshOpt wasm版本是包含了两个版本一个是基础版,一个使用SIMD版

不过官方没有提供asm版本,需要手动通过binaryen/wasm2js转换下即可,或者使用我转换好的meshopt_decoder.asm.module.js
在decoder层面上感觉是MeshOpt完胜
解析时间对比
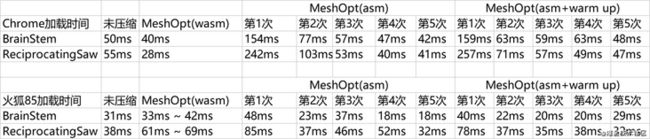
这里使用模型是默认参数压缩后的,电源模式是高性能,CPU一直在最高频率。尝试五次求均值,均是wasm版本。其中MeshOpt是SIMD版本,Chrome 88

可以看到MeshQuan和MeshOpt均比未压缩加载时间减少了不少,Draco则增加不少,如果考虑decoder的加载时间则需要看首次加载,3个扩展里只有Darco会有影响,因为只有Draco是第一次加载gltf需要从网络下载wasm,MeshOpt是序列化好存在字符串里,使用时只需unpack即可,无需网络请求。
asm版的解析时间对比在可用性部分
压缩前后效果对比
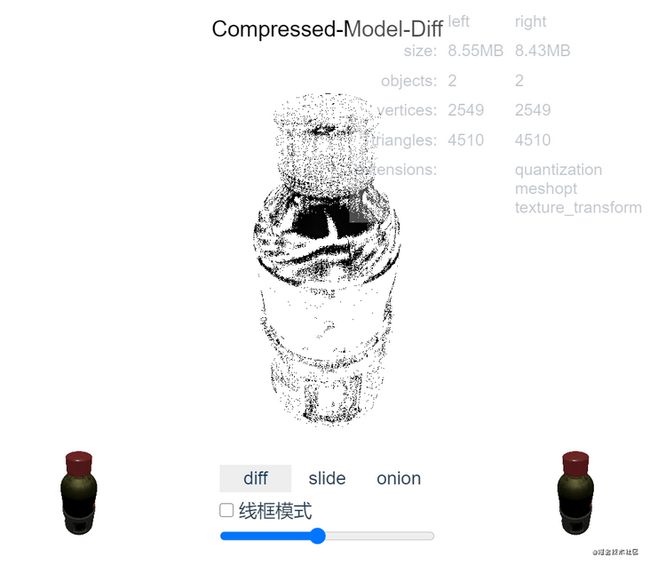
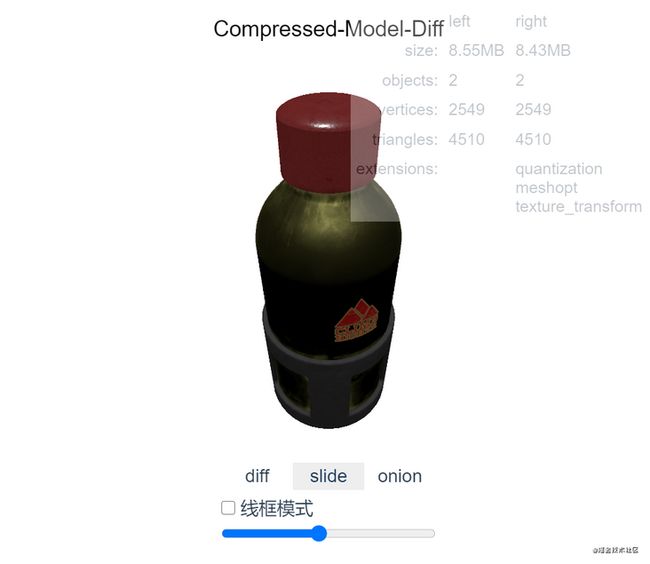
按道理除了对比性能上面的指标,还得对比压缩后是否出问题了,但是这个并不容易指标化,还是得看设计师是否妥协了,但是为了直观对比,所以我编写了一个compressed-model-diff工具
有3个对比模式和线框对比在线使用。

可用(场景、范围)
可用场景主要取决于Decoder加载难以程度和大小了

可以看到Draco在小程序上面就比较难受了,而MeshQuan无需decoder所以可用性是最高的,MeshOpt只需使用asm版兼容小程序ios即可。
所以如果需要兼容小程序平台,Draco就比较不太合适了,当然也可以对应平台加载对应的模型的方法,但是模型效果就需要对应平台单独微调了,还是全平台统一模型可维护性更高。
所以这里单独补充MeshOpt asm版的decode性能

但是有了奇怪的发现:第一次解析耗时很高,但是大概第3次接近未压缩的性能,第五次接近wasm的性能,这是为什么呢?是否说明一个潜在的优化方法呢?
先看看火狐的这个第一个支持ASM的浏览器如何,是否有类似的情况出现?

貌似在这个情况下火狐对js执行比chrome强不少,wasm反而没带来更好的效果,但是还是出现了类似的规律,是否说明decoder是需要一个预热,告诉浏览器decode的代码需要特殊优化?
所以这个通过加载一个1.21kb的Triangle-meshopt.glb,5次,再加载测试模型,记录数据
貌似莫得效果,估计是warm up的次数没够,Triangle-meshopt.glb,只有3个顶点,执行5次也就15个,量级没上去。从Web 3D是否需要WebAssembly?找到了答案
因为chrome浏览器的v8引擎支持JIT: Just-in-Time compilation,所以js程序的执行性能接近wasm(对于Web 3D程序,性能热点的逻辑会在主循环中多次被执行。而v8会在多次执行后,确定热点代码,会将其优化为字节码;然后从下次执行开始,直接执行字节码)
火狐下asm第一次加载耗时是未压缩的1.5 ~ 2.3倍\
chrome下asm第一次加载耗时是未压缩的3.08 ~ 4.4倍
当然由于只是微信小程序IOS下,IPhone的CPU本身比较好,所以还能接受,如果能找到warm up方法,第1次加载耗时等于第5次的就更好了。
缺点
向量化毕竟是丢失精度的有损压缩方法,但是也正如KHR_mesh_quantization所介绍,是一个精度和大小的妥协
Vertex attributes are usually stored using FLOAT component type. However, this can result in excess precision and increased memory consumption and transmission size, as well as reduced rendering performance.
KHR_mesh_quantization的缺点是向量化参数固定,无法修改,好处也是,无需额外decoder,而EXT_meshopt_compression则其升级版,可自定义向量化参数,比如法线精度要求高的时候可以增大容量
KHR_draco_mesh_compression这个比较知名的扩展,在这次测评下虽然纯顶点的模型压缩比最高,但是相比之下,其decoder大小和decode性能均不突出。
KHR_mesh_quantization和EXT_meshopt_compression都是固定转换,比如模型本身如果尺寸很小,其使用到的浮点数范围也很小,这时候丢失精度的情况就比较大了,解决办法除了增加存储的容量,更简单的其实是,放大模型,让顶点之间的距离变大,使用的时候再缩小即可。文本描述可能没有那么直观还是看动图吧。
模型放大10倍后,不是同一个模型版本忽略颜色变化
中间包包的差异基本可以忽略不计,但是下面还是有纹理偏移出现。
猜想未来改进方向
由上面的固定向量化导致模型处于小浮点数范围出现的误差问题可以推测下一步可以优化:动态向量化+偏移,目测可以进一步提供精度和压缩比,但是decoder的耗时会增加。
比如把模型的BoundingBox.xyz最大值作为映射到0-1,再映射到整型/自定义XByte,当然模型里面的子mesh也可以如此,也可以xyz分别维护等等。
当然只是想法,本文其实目的就是因为发现一个牛皮的扩展MeshOpt,但是想相对严谨去测试验证引入到项目可用性的,也是一个探索的过程。
总结
MeshOpt牛皮