
在本次案例中,京东云的中台技术工程师遇到了来自客户提出的打破K8s产品功能限制的特殊需求,面对这个极具挑战的任务,攻城狮最终是否克服了重重困难,帮助客户完美实现了需求?且看本期K8s技术案例分享!(友情提示:文章篇幅较长,建议各位看官先收藏再阅读,同时在阅读过程中注意劳逸结合,保持身心健康!)
第一部分:“颇有个性”的需求
某日,我们京东云的技术中台工程师接到了客户的求助。客户在云上环境使用了托管K8s集群产品部署测试集群。因业务需要,研发同事需要在办公网环境能直接访问K8s集群的clueterIP类型的service和后端的pod。通常K8s的pod只能在集群内通过其他pod或者集群node访问,不能直接在集群外进行访问。而pod对集群内外提供服务时需要通过service对外暴露访问地址和端口,service除了起到pod应用访问入口的作用,还会对pod的相应端口进行探活,实现健康检查。同时当后端有多个Pod时,service还将根据调度算法将客户端请求转发至不同的pod,实现负载均衡的作用。常用的service类型有如下几种:
service类型简介
1、 clusterIP类型,创建service时如果不指定类型的话的默认会创建该类型service,clusterIP类型的service只能在集群内通过cluster IP被pod和node访问,集群外无法访问。通常像K8s集群系统服务kubernetes等不需要对集群外提供服务,只需要在集群内部进行访问的service会使用这种类型;
2、 nodeport类型,为了解决集群外部对service的访问需求,设计了nodeport类型,将service的端口映射至集群每个节点的端口上。当集群外访问service时,通过对节点IP和指定端口的访问,将请求转发至后端pod;
3、 loadbalancer类型,该类型通常需要调用云厂商的API接口,在云平台上创建负载均衡产品,并根据设置创建监听器。在K8s内部,loadbalancer类型服务实际上还是和nodeport类型一样将服务端口映射至每个节点的固定端口上。然后将节点设置为负载均衡的后端,监听器将客户端请求转发至后端节点上的服务映射端口,请求到达节点端口后,再转发至后端pod。Loadbalancer类型的service弥补了nodeport类型有多个节点时客户端需要访问多个节点IP地址的不足,只要统一访问LB的IP即可。同时使用LB类型的service对外提供服务,K8s节点无需绑定公网IP,只需要给LB绑定公网IP即可,提升了节点安全性,也节约了公网IP资源。利用LB对后端节点的健康检查功能,可实现服务高可用。避免某个K8s节点故障导致服务无法访问。
Part1小结
通过对K8s集群service类型的了解,我们可以知道客户想在集群外对service进行访问,首先推荐使用的是LB类型的service。由于目前K8s集群产品的节点还不支持绑定公网IP,因此使用nodeport类型的service无法实现通过公网访问,除非客户使用专线连接或者IPSEC将自己的办公网与云上网络打通,才能访问nodeport类型的service。而对于pod,只能在集群内部使用其他pod或者集群节点进行访问。同时K8s集群的clusterIP和pod设计为不允许集群外部访问,也是出于提高安全性的考虑。如果将访问限制打破,可能会导致安全问题发生。所以我们的建议客户还是使用LB类型的service对外暴露服务,或者从办公网连接K8s集群的NAT主机,然后通过NAT主机可以连接至K8s节点,再访问clusterIP类型的service,或者访问后端pod。
客户表示目前测试集群的clusterIP类型服务有上百个,如果都改造成LB类型的service就要创建上百个LB实例,绑定上百个公网IP,这显然是不现实的,而都改造成Nodeport类型的service的工作量也十分巨大。同时如果通过NAT主机跳转登录至集群节点,就需要给研发同事提供NAT主机和集群节点的系统密码,不利于运维管理,从操作便利性上也不如研发可以直接通过网络访问service和pod简便。
第二部分:方法总比困难多?
虽然客户的访问方式违背了K8s集群的设计逻辑,显得有些“非主流”,但是对于客户的使用场景来说也是迫不得已的强需求。作为技术中台的攻城狮,我们要尽最大努力帮助客户解决技术问题!因此我们根据客户的需求和场景架构,来规划实现方案。
既然是网络打通,首先要从客户的办公网和云上K8s集群网络架构分析。客户办公网有统一的公网出口设备,而云上K8s集群的网络架构如下,K8s集群master节点对用户不可见,用户创建K8s集群后,会在用户选定的VPC网络下创建三个子网。分别是用于K8s节点通讯的node子网,用于部署NAT主机和LB类型serivce创建的负载均衡实例的NAT与LB子网,以及用于pod通讯的pod子网。K8s集群的节点搭建在云主机上,node子网访问公网地址的路由下一跳指向NAT主机,也就是说集群节点不能绑定公网IP,使用NAT主机作为统一的公网访问出口,做SNAT,实现公网访问。由于NAT主机只有SNAT功能,没有DNAT功能,因此也就无法从集群外通过NAT主机访问node节点。
关于pod子网的规划目的,首先要介绍下pod在节点上的网络架构。如下图所示:

在节点上,pod中的容器通过veth对与docker0设备连通,而docker0与节点的网卡之间通过自研CNI网络插件连通。为了实现集群控制流量与数据流量的分离,提高网络性能,集群在每个节点上单独绑定弹性网卡,专门供pod通讯使用。创建pod时,会在弹性网卡上为Pod分配IP地址。每个弹性网卡最多可以分配21个IP,当一张弹性网卡上的IP分配满后,会再绑定一张新的网卡供后续新建的pod使用。弹性网卡所属的子网就是pod子网,基于这样的架构,可以降低节点eth0主网卡的负载压力,实现控制流量与数据流量分离,同时pod的IP在VPC网络中有实际对应的网络接口和IP,可实现VPC网络内对pod地址的路由。
你需要了解的打通方式
了解完两端的网络架构后我们来选择打通方式。通常将云下网络和云上网络打通,有专线产品连接方式,或者用户自建VPN连接方式。专线产品连接需要布设从客户办公网到云上机房的网络专线,然后在客户办公网侧的网络出口设备和云上网络侧的bgw边界网关配置到彼此对端的路由。如下图所示:

基于现有专线产品BGW的功能限制,云上一侧的路由只能指向K8s集群所在的VPC,无法指向具体的某个K8s节点。而想要访问clusterIP类型service和pod,必须在集群内的节点和pod访问。因此访问service和pod的路由下一跳,必须是某个集群节点。所以使用专线产品显然是无法满足需求的。
我们来看自建VPN方式,自建VPN在客户办公网和云上网络各有一个有公网IP的端点设备,两个设备之间建立加密通讯隧道,实际底层还是基于公网通讯。如果使用该方案,云上的端点我们可以选择和集群节点在同一VPC的不同子网下的有公网IP的云主机。办公网侧对service和pod的访问数据包通过VPN隧道发送至云主机后,可以通过配置云主机所在子网路由,将数据包路由至某个集群节点,然后在集群节点所在子网配置到客户端的路由下一跳指向端点云主机,同时需要在pod子网也做相同的路由配置。至于VPN的实现方式,通过和客户沟通,我们选取ipsec隧道方式。
确定了方案,我们需要在测试环境实施方案验证可行性。由于我们没有云下环境,因此选取和K8s集群不同地域的云主机代替客户的办公网端点设备。在华东上海地域创建云主机office-ipsec-sh模拟客户办公网客户端,在华北北京地域的K8s集群K8s-BJTEST01所在VPC的NAT/LB子网创建一个有公网IP的云主机K8s-ipsec-bj,模拟客户场景下的ipsec云上端点,与华东上海云主机office-ipsec-sh建立ipsec隧道。设置NAT/LB子网的路由表,添加到service网段的路由下一跳指向K8s集群节点K8s-node-vmlppp-bs9jq8pua,以下简称node A。由于pod子网和NAT/LB子网同属于一个VPC,所以无需配置到pod网段的路由,访问pod时会直接匹配local路由,转发至对应的弹性网卡上。为了实现数据包的返回,在node子网和pod子网分别配置到上海云主机office-ipsec-sh的路由,下一跳指向K8s-ipsec-bj。完整架构如下图所示:

第三部分:实践出“问题”
既然确定了方案,我们就开始搭建环境了。首先在K8s集群的NAT/LB子网创建K8s-ipsec-bj云主机,并绑定公网IP。然后与上海云主机office-ipsec-sh建立ipsec隧道。关于ipsec部分的配置方法网络上有很多文档,在此不做详细叙述,有兴趣的童鞋可以参照文档自己实践下。隧道建立后,在两端互ping对端的内网IP,如果可以ping通的话,证明ipsec工作正常。按照规划配置好NAT/LB子网和node子网以及pod子网的路由。我们在K8s集群的serivce中,选择一个名为nginx的serivce,clusterIP为10.0.58.158,如图所示:

该服务后端的pod是10.0.0.13,部署nginx默认页面,并监听80端口。在上海云主机上测试ping service的IP 10.0.58.158,可以ping通,同时使用paping工具ping服务的80端口,也可以ping通!

使用curl http://10.0.58.158进行http请求,也可以成功!

再测试直接访问后端pod,也没有问题:)

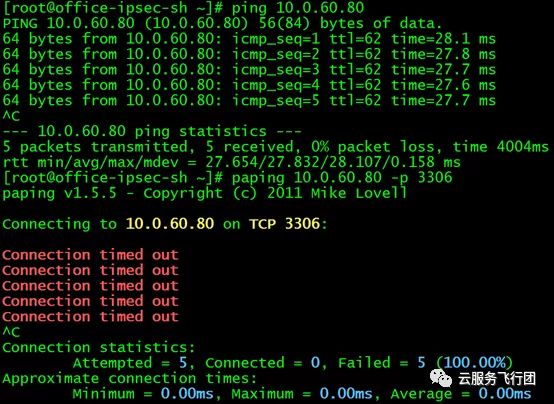
正当攻城狮心里美滋滋,以为一切都大功告成的时候,测试访问另一个service的结果犹如一盆冷水泼来。我们接着选取了mysql这个service,测试访问3306端口。该serivce的clusterIP是10.0.60.80,后端pod的IP是10.0.0.14。

在上海云主机直接ping service的clusterIP,没有问题。但是paping 3306端口的时候,居然不通了!
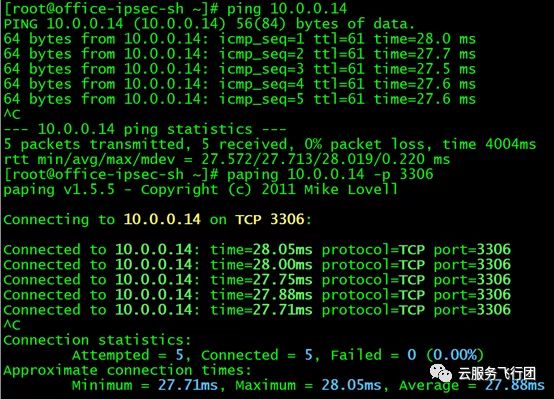
然后我们测试直接访问serivce的后端pod,诡异的是,后端pod无论是ping IP还是paping 3306端口,都是可以连通的!
肿么回事?
这是肿么回事?经过攻城狮一番对比分析,发现两个serivce唯一的不同是,可以连通nginx服务的后端pod 10.0.0.13就部署在客户端请求转发到的node A上。而不能连通的mysql服务的后端pod不在node A上,在另一个节点上。为了验证问题原因是否就在于此,我们单独修改NAT/LB子网路由,到mysql服务的下一跳指向后端pod所在的节点。然后再次测试。果然!现在可以访问mysql服务的3306端口了!

第四部分:三个为什么?
此时此刻,攻城狮的心中有三个疑问:
(1)为什么请求转发至service后端pod所在的节点时可以连通?
(2)为什么请求转发至service后端pod不在的节点时不能连通?
(3)为什么不管转发至哪个节点,service的IP都可以ping通?
深入分析,消除问号
为了消除我们心中的小问号,我们就要深入分析,了解导致问题的原因,然后再对症下药。既然要排查网络问题,当然还是要祭出经典法宝——tcpdump抓包工具。为了把焦点集中,我们对测试环境的架构进行了调整。上海到北京的ipsec部分维持现有架构不变,我们对K8s集群节点进行扩容,新建一个没有任何pod的空节点K8s-node-vmcrm9-bst9jq8pua,以下简称node B,该节点只做请求转发。修改NAT/LB子网路由,访问service地址的路由下一跳指向该节点。测试的service我们选取之前使用的nginx服务10.0.58.158和后端pod 10.0.0.13,如下图所示:

当需要测试请求转发至pod所在节点的场景时,我们将service路由下一跳修改为K8s-node-A即可。
万事俱备,让我们开启解惑之旅!Go Go Go!
首先探究疑问1场景,我们在K8s-node-A上执行命令抓取与上海云主机172.16.0.50的包,命令如下:
tcpdump -i any host 172.16.0.50 -w /tmp/dst-node-client.cap
各位童鞋是否还记得我们之前提到过,在托管K8s集群中,所有pod的数据流量均通过节点的弹性网卡收发?在K8s-node-A上pod使用的弹性网卡是eth1。我们首先在上海云主机上使用curl命令请求http://10.0.58.158,同时执行命令抓取K8s-node-A的eth1上是否有pod 10.0.0.13的包收发,命令如下:
tcpdump –i eth1 host 10.0.0.13
结果如下图:

并没有任何10.0.0.13的包从eth1收发,但此时上海云主机上的curl操作是可以请求成功的,说明10.0.0.13必然给客户端回包了,但是并没有通过eth1回包。那么我们将抓包范围扩大至全部接口,命令如下:
tcpdump -i any host 10.0.0.13
结果如下图:

可以看到这次确实抓到了10.0.0.13和172.16.0.50交互的数据包,为了便于分析,我们使用命令tcpdump -i any host 10.0.0.13 -w /tmp/dst-node-pod.cap将包输出为cap文件。
同时我们再执行tcpdump -i any host 10.0.58.158,对service IP进行抓包。
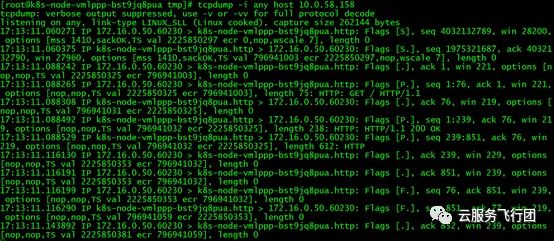
可以看到172.16.0.50执行curl请求时可以抓到数据包,且只有10.0.58.158与172.16.0.50交互的数据包,不执行请求时没有数据包。由于这一部分数据包会包含在对172.16.0.50的抓包中,因此我们不再单独分析。
将针对172.16.0.50和10.0.0.13的抓包文件取出,使用wireshark工具进行分析,首先分析对客户端172.16.0.50的抓包,详情如下图所示:
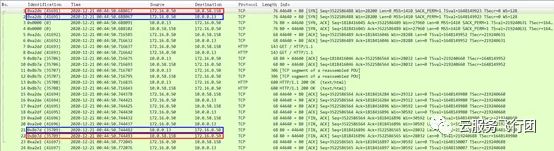
可以发现客户端172.16.0.50先给service IP 10.0.58.158发了一个包,然后又给pod IP 10.0.0.13发了一个包,两个包的ID,内容等完全一致。而最后回包时,pod 10.0.0.13给客户端回了一个包,然后service IP 10.0.58.158也给客户端回了一个ID和内容完全相同的包。这是什么原因导致的呢?
通过之前的介绍,我们知道service将客户端请求转发至后端pod,在这个过程中客户端请求的是service的IP,然后service会做DNAT(根据目的IP做NAT转发),将请求转发至后端的pod IP。虽然我们抓包看到的是客户端发了两次包,分别发给service和pod,实际上客户端并没有重新发包,而是由service完成了目的地址转换。而pod回包时,也是将包回给service,然后再由service转发给客户端。因为是相同节点内请求,这一过程应该是在节点的内部虚拟网络中完成,所以我们在pod使用的eth1网卡上并没有抓到和客户端交互的任何数据包。再结合pod维度的抓包,我们可以看到针对client抓包时抓到的http get请求包在对pod的抓包中也能抓到,也验证了我们的分析。


那么pod是通过哪个网络接口进行收发包的呢?执行命令netstat -rn查看node A上的网络路由,我们有了如下发现:

在节点内,所有访问10.0.0.13的路由都指向了cni34f0b149874这个网络接口。很显然这个接口是CNI网络插件创建的虚拟网络设备。为了验证pod所有的流量是否都通过该接口收发,我们再次在客户端请求service地址,在node A以客户端维度和pod维度抓包,但是这次以pod维度抓包时,我们不再使用-i any参数,而是替换为-i cni34f0b149874。抓包后分析对比,发现如我们所料,客户端对pod的所有请求包都能在对cni34f0b149874的抓包中找到,同时对系统中除了cni34f0b149874之外的其他网络接口抓包,均没有抓到与客户端交互的任何数据包。因此可以证明我们的推断正确。
综上所述,在客户端请求转发至pod所在节点时,数据通路如下图所示:

接下来我们探究最为关心的问题2场景,修改NAT/LB子网路由到service的下一跳指向新建节点node B,如图所示
这次我们需要在node B和node A上同时抓包。在客户端还是使用curl方式请求service地址。在转发节点node B上,我们先执行命令tcpdump -i eth0 host 10.0.58.158抓取service维度的数据包,发现抓取到了客户端到service的请求包,但是service没有任何回包,如图所示:

各位童鞋可能会有疑惑,为什么抓取的是10.0.58.158,但抓包中显示的目的端是该节点名?实际上这与service的实现机制有关。在集群中创建service后,集群网络组件会在各个节点上都选取一个随机端口进行监听,然后在节点的iptables中配置转发规则,凡是在节点内请求service IP均转发至该随机端口,然后由集群网络组件进行处理。所以在节点内访问service时,实际访问的是节点上的某个端口。如果将抓包导出为cap文件,可以看到请求的目的IP仍然是10.0.58.158,如图所示:

这也解释了为什么clusterIP只能在集群内的节点或者pod访问,因为集群外的设备没有K8s网络组件创建的iptables规则,不能将请求service地址转为请求节点的端口,即使数据包发送至集群,由于service的clusterIP在节点的网络中实际是不存在的,因此会被丢弃。(奇怪的姿势又增长了呢)
回到问题本身,在转发节点上抓取service相关包,发现service没有像转发到pod所在节点时给客户端回包。我们再执行命令tcpdump -i any host 172.16.0.50 -w /tmp/fwd-node-client.cap以客户端维度抓包,包内容如下:

我们发现客户端请求转发节点node B上的service后,service同样做了DNAT,将请求转发到node A上的10.0.0.13。但是在转发节点上没有收到10.0.0.13回给客户端的任何数据包,之后客户端重传了几次请求包,均没有回应。
那么node A是否收到了客户端的请求包呢?pod又有没有给客户端回包呢?我们移步node A进行抓包。在node B上的抓包我们可以获悉node A上应该只有客户端IP和pod IP的交互,因此我们就从这两个维度抓包。根据之前抓包的分析结果,数据包进入节点内之后,应该通过虚拟设备cni34f0b149874与pod交互。而node B节点访问pod应该从node A的弹性网卡eth1进入节点,而不是eth0,为了验证,首先执行命令tcpdump -i eth0 host 172.16.0.50和tcpdump -i eth0 host 10.0.0.13,没有抓到任何数据包。
说明数据包没有走eth0。再分别执行tcpdump -i eth1 host 172.16.0.50 -w /tmp/dst-node-client-eth1.cap和tcpdump -i cni34f0b149874 host 172.16.0.50 -w /tmp/dst-node-client-cni.cap抓取客户端维度数据包,对比发现数据包内容完全一致,说明数据包从eth1进入Node A后,通过系统内路由转发至cni34f0b149874。数据包内容如下:

可以看到客户端给pod发包后,pod给客户端回了包。执行tcpdump -i eth1 host 10.0.0.13 -w /tmp/dst-node-pod-eth1.cap和tcpdump -i host 10.0.0.13 -w /tmp/dst-node-pod-cni.cap抓取pod维度数据包,对比发现数据包内容完全一致,说明pod给客户端的回包通过cni34f0b149874发出,然后从eth1网卡离开node A节点。数据包内容也可以看到pod给客户端返回了包,但没有收到客户端对于返回包的回应,触发了重传。

那么既然pod的回包已经发出,为什么node B上没有收到回包,客户端也没有收到回包呢?查看eth1网卡所属的pod子网路由表,我们恍然大悟!
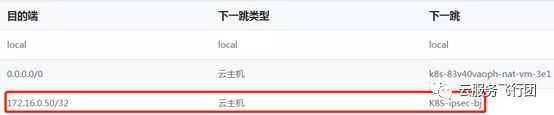
由于pod给客户端回包是从node A的eth1网卡发出的,所以虽然按照正常DNAT规则,数据包应该发回给node B上的service端口,但是受eth1子网路由表影响,数据包直接被“劫持”到了K8s-ipsec-bj这个主机上。而数据包到了这个主机上之后,由于没有经过service的转换,回包的源地址是pod地址10.0.0.13,目的地址是172.16.0.50,这个数据包回复的是源地址172.16.0.50,目的地址10.0.58.158这个数据包。相当于请求包的目的地址和回复包的源地址不一致,对于K8s-ipsec-bj来说,只看到了10.0.0.13给172.16.0.50的reply包,但是没有收到过172.16.0.50给10.0.0.13的request包,云平台虚拟网络的机制是遇到只有reply包,没有request包的情况会将request包丢弃,避免利用地址欺骗发起网络攻击。所以客户端不会收到10.0.0.13的回包,也就无法完成对service的请求。在这个场景下,数据包的通路如下图所示:
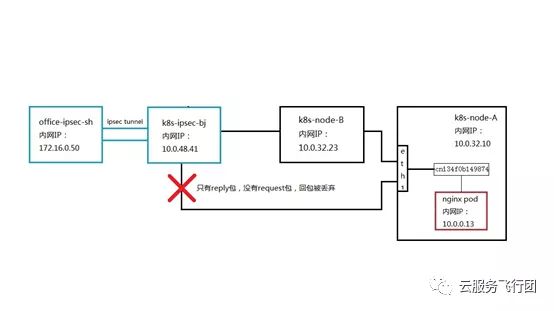
此时客户端可以成功请求pod的原因也一目了然 ,请求pod的数据通路如下:
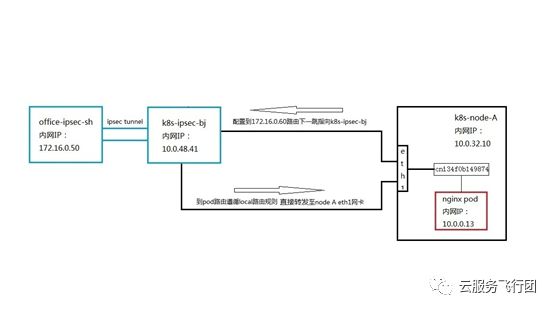
请求包和返回包的路径一致,都经过K8s-ipsec-bj节点且源目IP没有发生改变,因此pod可以连通。
看到这里,机智的童鞋可能已经想到,那修改eth1所属的pod子网路由,让去往172.16.0.50的数据包下一跳不发送到K8s-ipsec-bj,而是返回给K8s-node-B,不就可以让回包沿着来路原路返回,不会被丢弃吗?是的,经过我们的测试验证,这样确实可以使客户端成功请求服务。但是别忘了,用户还有一个需求是客户端可以直接访问后端pod,如果pod回包返回给node B,那么客户端请求pod时的数据通路是怎样的呢?
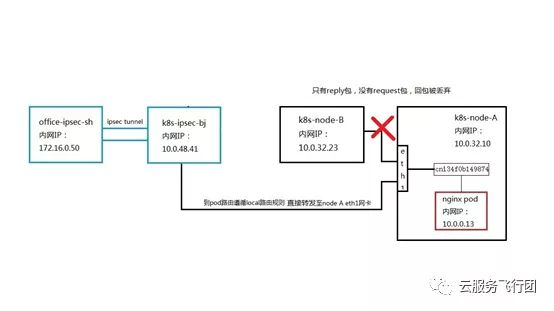
如图所示,可以看到客户端对Pod的请求到达K8s-ipsec-bj后,由于是同一vpc内的地址访问,所以遵循local路由规则直接转发到node A eth1网卡,而pod给客户端回包时,受eth1网卡路由控制,发送到了node B上。node B之前没有收到过客户端对pod的request包,同样会遇到只有reply包没有request包的问题,所以回包被丢弃,客户端无法请求pod。
至此,我们搞清楚了为什么客户端请求转发至service后端pod不在的节点上时无法成功访问service的原因。那么为什么在此时虽然请求service的端口失败,但是可以ping通service地址呢?攻城狮推断,既然service对后端的pod起到DNAT和负载均衡的作用,那么当客户端ping service地址时,ICMP包应该是由service直接应答客户端的,即service代替后端pod答复客户端的ping包。为了验证我们的推断是否正确,我们在集群中新建一个没有关联任何后端的空服务,如图所示:

然后在客户端ping 10.0.62.200,结果如下:
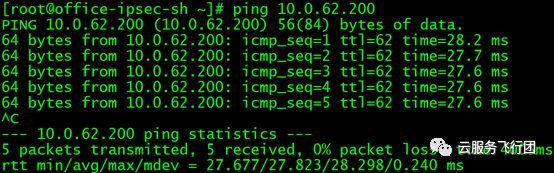
果不其然,即使service后端没有任何pod,也可以ping通,因此证明ICMP包均为service代答,不存在实际请求后端pod时的问题,因此可以ping通。
第五部分:天无绝人之路
既然费尽周折找到了访问失败的原因,接下来我们就要想办法解决这个问题。事实上只要想办法让pod跨节点给客户端回包时隐藏自己的IP,对外显示的是service的IP,就可以避免包被丢弃。原理上类似于SNAT(基于源IP的地址转换)。可以类比为没有公网IP的局域网设备有自己的内网IP,当访问公网时需要通过统一的公网出口,而此时外部看到的客户端IP是公网出口的IP,并不是局域网设备的内网IP。实现SNAT,我们首先会想到通过节点操作系统上的iptables规则。我们在pod所在节点node A上执行iptables-save命令,查看系统已有的iptables规则都有哪些。


敲黑板,注意啦
可以看到系统创建了近千条iptables规则,大多数与K8s有关。我们重点关注上图中的nat类型规则,发现了有如下几条引起了我们的注意:

首先看红框部分规则
-A KUBE-SERVICES -m comment --comment "Kubernetes service cluster ip + port for masquerade purpose" -m set --match-set KUBE-CLUSTER-IP src,dst -j KUBE-MARK-MASQ
该规则表示如果访问的源地址或者目的地址是cluster ip +端口,出于masquerade目的,将跳转至KUBE-MARK-MASQ链,masquerade也就是地址伪装的意思!在NAT转换中会用到地址伪装。
接下来看蓝框部分规则
-A KUBE-MARK-MASQ -j MARK --set-xmark 0x4000/0x4000
该规则表示对于数据包打上需要做地址伪装的标记0x4000/0x4000。
最后看黄框部分规则
-A KUBE-POSTROUTING -m comment --comment "kubernetes service traffic requiring SNAT" -m mark --mark 0x4000/0x4000 -j MASQUERADE
该规则表示对于标记为0x4000/0x4000需要做SNAT的数据包,将跳转至MASQUERADE链进行地址伪装。
这三条规则所做的操作貌似正是我们需要iptables帮我们实现的,但是从之前的测试来看显然这三条规则并没有生效。这是为什么呢?是否是K8s的网络组件里有某个参数控制着是否会对访问clusterIP时的数据包进行SNAT?
这就要从负责service与pod之间网络代理转发的组件——kube-proxy的工作模式和参数进行研究了。我们已经知道service会对后端pod进行负载均衡和代理转发,要想实现该功能,依赖的是kube-proxy组件,从名称上可以看出这是一个代理性质的网络组件。它以pod形式运行在每个K8s节点上,当以service的clusterIP+端口方式访问时,通过iptables规则将请求转发至节点上对应的随机端口,之后请求由kube-proxy组件接手处理,通过kube-proxy内部的路由和调度算法,转发至相应的后端Pod。最初,kube-proxy的工作模式是userspace(用户空间代理)模式,kube-proxy进程在这一时期是一个真实的TCP/UDP代理,类似HA Proxy。由于该模式在1.2版本K8s开始已被iptables模式取代,在此不做赘述,有兴趣的童鞋可以自行研究下。
1.2版本引入的iptables模式作为kube-proxy的默认模式,kube-proxy本身不再起到代理的作用,而是通过创建和维护对应的iptables规则实现service到pod的流量转发。但是依赖iptables规则实现代理存在无法避免的缺陷,在集群中的service和pod大量增加后,iptables规则的数量也会急剧增加,会导致转发性能显著下降,极端情况下甚至会出现规则丢失的情况。
为了解决iptables模式的弊端,K8s在1.8版本开始引入IPVS(IP Virtual Server)模式。IPVS模式专门用于高性能负载均衡,使用更高效的hash表数据结构,为大型集群提供了更好的扩展性和性能。比iptables模式支持更复杂的负载均衡调度算法等。托管集群的kube-proxy正是使用了IPVS模式。
但是IPVS模式无法提供包过滤,地址伪装和SNAT等功能,所以在需要使用这些功能的场景下,IPVS还是要搭配iptables规则使用。等等,地址伪装和SNAT,这不正是我们之前在iptables规则中看到过的?这也就是说,iptables在不进行地址伪装和SNAT时,不会遵循相应的iptables规则,而一旦设置了某个参数开启地址伪装和SNAT,之前看到的iptables规则就会生效!于是我们到kubernetes官网查找kube-proxy的工作参数,有了令人激动的发现:

好一个蓦然回首!攻城狮的第六感告诉我们,--masquerade-all参数就是解决我们问题的关键!
第六部分:真·方法比困难多
我们决定测试开启下--masquerade-all这个参数。kube-proxy在集群中的每个节点上以pod形式运行,而kube-proxy的参数配置都以configmap形式挂载到pod上。我们执行kubectl get cm -n kube-system查看kube-proxy的configmap,如图所示:

红框里的就是kube-proxy的配置configmap,执行kubectl edit cm kube-proxy-config-khc289cbhd -n kube-system编辑这个configmap,如图所示

找到了masqueradeALL参数,默认是false,我们修改为true,然后保存修改。
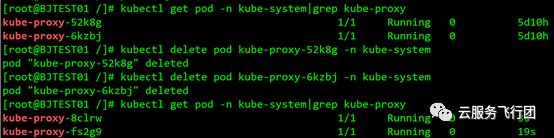
要想使配置生效,需要逐一删除当前的kube-proxy pod,daemonset会自动重建pod,重建的pod会挂载修改过的configmap,masqueradeALL功能也就开启了。如图所示:
期待地搓手手
接下来激动人心的时刻到来了,我们将访问service的路由指向node B,然后在上海客户端上执行paping 10.0.58.158 -p 80观察测试结果(期待地搓手手):
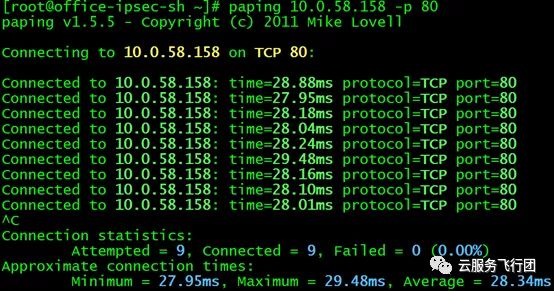
此情此景,不禁让攻城狮流下了欣喜的泪水……
再测试下curl http://10.0.58.158 同样可以成功!奥力给~
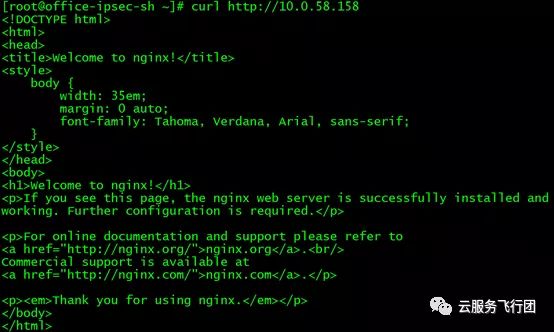
再测试下直接访问后端Pod,以及请求转发至pod所在节点,都没有问题。至此客户的需求终于卍解,长舒一口气!
大结局:知其所以然
虽然问题已经解决,但是我们的探究还没有结束。开启masqueradeALL参数后,service是如何对数据包做SNAT,避免了之前的丢包问题呢?还是通过抓包进行分析。
首先分析转发至pod不在的节点时的场景,客户端请求服务时,在pod所在节点对客户端IP进行抓包,没有抓到任何包。

说明开启参数后,到后端pod的请求不再是以客户端IP发起的。
在转发节点对pod IP进行抓包可以抓到转发节点的service端口与pod之间的交互包。
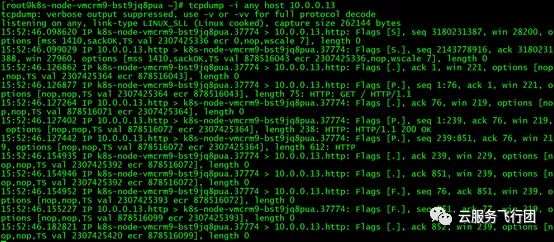
说明pod没有直接回包给客户端172.16.0.50。这样看来,相当于客户端和pod互相不知道彼此的存在,所有交互都通过service来转发。
再在转发节点对客户端进行抓包,包内容如下:

同时在pod所在节点对pod进行抓包,包内容如下:

可以看到转发节点收到序号708的curl请求包后,在pod所在节点收到了序号相同的请求包,只不过源目IP从172.16.0.50/10.0.58.158转换为了10.0.32.23/10.0.0.13。这里10.0.32.23是转发节点的内网IP,实际上就是节点上service对应的随机端口,所以可以理解为源目IP转换为了10.0.58.158/10.0.0.13。而回包时的流程相同,pod发出序号17178的包,转发节点将相同序号的包发给客户端,源目IP从10.0.0.13/10.0.58.158转换为了10.0.58.158/172.16.0.50
根据以上现象可以得知,service对客户端和后端都做了SNAT,可以理解为关闭了透传客户端源IP的负载均衡,即客户端和后端都不知道彼此的存在,只知道service的地址。该场景下的数据通路如下图:

对Pod的请求不涉及SNAT转换,与masqueradeALL参数不开启时是一样的,因此我们不再做分析。
当客户端请求转发至pod所在节点时,service依然会进行SNAT转换,只不过这一过程均在节点内部完成。通过之前的分析我们也已经了解,客户端请求转发至pod所在节点时,是否进行SNAT对访问结果没有影响。
总结
至此对于客户的需求,我们可以给出现阶段最优的方案。当然在生产环境,为了业务安全和稳定,还是不建议用户将clusterIP类型服务和pod直接暴露在集群之外。同时masqueradeALL参数开启后,对集群网络性能和其他功能是否有影响也没有经过测试验证,在生产环境开启的风险是未知的,还需要谨慎对待。通过解决客户需求的过程,我们对K8s集群的service和pod网络机制有了一定程度的了解,并了解了kube-proxy的masqueradeALL参数,对今后的学习和运维工作还是受益匪浅的。
在此感谢各位童鞋阅读,如果能够对大家有所帮助,欢迎点赞转发,并关注我们的公众号,更多精彩内容会持续放送!
推荐阅读
欢迎点击【京东科技】,了解开发者社区
更多精彩技术实践与独家干货解析
欢迎关注【京东科技开发者】公众号
