摘要:使用Spark SQL进行ETL任务,在读取某张表的时候报错:“IOException: totalValueCount == 0”,但该表在写入时,并没有什么异常。
本文分享自华为云社区《你的Parquet该升级了:IOException: totalValueCount == 0问题定位之旅》,原文作者:wzhfy 。
1. 问题描述
使用Spark SQL进行ETL任务,在读取某张表的时候报错:“IOException: totalValueCount == 0”,但该表在写入时,并没有什么异常。
2. 初步分析
该表的结果是由两表join后生成。经分析,join的结果产生了数据倾斜,且倾斜key为null。Join后每个task写一个文件,所以partition key为null的那个task将大量的null值写入了一个文件,null值个数达到22亿。
22亿这个数字比较敏感,正好超过int最大值2147483647(21亿多)。因此,初步怀疑parquet在写入超过int.max个value时有问题。
【注】本文只关注大量null值写入同一个文件导致读取时报错的问题。至于该列数据产生如此大量的null是否合理,不在本文讨论范围之内。
3. Deep dive into Parquet (version 1.8.3,部分内容可能需要结合Parquet源码进行理解)
入口:Spark(Spark 2.3版本) -> Parquet
Parquet调用入口在Spark,所以从Spark开始挖掘调用栈。
InsertIntoHadoopFsRelationCommand.run()/SaveAsHiveFile.saveAsHiveFile() -> FileFormatWriter.write()
这里分几个步骤:
- 启动作业前,创建outputWriterFactory: ParquetFileFormat.prepareWrite()。这里会设置一系列与parquet写文件有关的配置信息。其中主要的一个,是设置WriteSupport类:ParquetOutputFormat.setWriteSupportClass(job, classOf[ParquetWriteSupport]),ParquetWriteSupport是Spark自己定义的类。
- 在executeTask() -> writeTask.execute()中,先通过outputWriterFactory创建OutputWriter (ParquetOutputWriter):outputWriterFactory.newInstance()。
- 对于每行记录,使用ParquetOutputWriter.write(InternalRow)方法依次写入parquet文件。
- Task结束前,调用ParquetOutputWriter.close()关闭资源。
3.1 Write过程

在ParquetOutputWriter中,通过ParquetOutputFormat.getRecordWriter构造一个RecordWriter(ParquetRecordWriter),其中包含了:
- prepareWrite()时设置的WriteSupport:负责转换Spark record并写入parquet结构
- ParquetFileWriter:负责写入文件
ParquetRecordWriter中,其实是把write操作委托给了一个internalWriter(InternalParquetRecordWriter,用WriteSupport和ParquetFileWriter构造)。
现在让我们梳理一下,目前为止的大致流程为:
SingleDirectoryWriteTask/DynamicPartitionWriteTask.execute
-> ParquetOutputWriter.write -> ParquetRecordWriter.write -> InternalParquetRecordWriter.write
接下来,InternalParquetRecordWriter.write里面,就是三件事:

(1)writeSupport.write,即ParquetWriteSupport.write,里面分三个步骤:
- MessageColumnIO.MessageColumnIORecordConsumer.startMessage;
- ParquetWriteSupport.writeFields:写入一行中各个列的值,null值除外;
- MessageColumnIO.MessageColumnIORecordConsumer.endMessage:针对第二步中的missing fields写入null值。
ColumnWriterV1.writeNull -> accountForValueWritten:
1) 增加计数器valueCount (int类型)
2) 检查空间是否已满,需要writePage - 检查点1

(2)增加计数器recordCount(long类型)
(3)检查block size,是否需要flushRowGroupToStore - 检查点2

由于写入的值全是null,在1、2两个检查点的memSize都为0,所以不会刷新page和row group。导致的结果就是,一直在往同一个page里增加null值。而ColumnWriterV1的计数器valueCount是int类型,当超过int.max时,溢出,变为了一个负数。
因此,只有当调用close()方法时(task结束时),才会执行flushRowGroupToStore:
ParquetOutputWriter.close -> ParquetRecordWriter.close
-> InternalParquetRecordWriter.close -> flushRowGroupToStore
-> ColumnWriteStoreV1.flush -> for each column ColumnWriterV1.flush
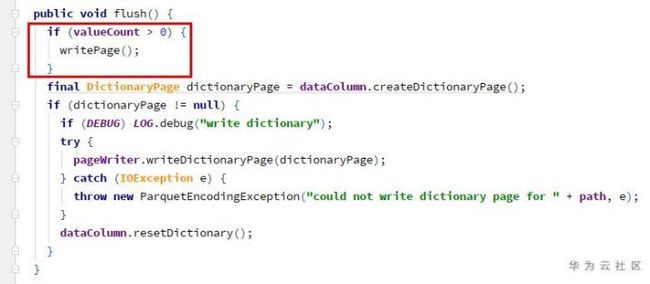
由于valueCount溢出为负,此处也不会写page。
因为未调用过writePage,所以此处的totalValueCount一直为0。
ColumnWriterV1.writePage -> ColumnChunkPageWriter.writePage -> 累计totalValueCount
在write结束时,InternalParquetRecordWriter.close -> flushRowGroupToStore -> ColumnChunkPageWriteStore.flushToFileWriter -> for each column ColumnChunkPageWriter.writeToFileWriter:
- ParquetFileWriter.startColumn:totalValueCount赋值给currentChunkValueCount
- ParquetFileWriter.writeDataPages
- ParquetFileWriter.endColumn:currentChunkValueCount(为0)和其他元数据信息构造出一个ColumnChunkMetaData,相关信息最终会被写入文件。
3.2 Read过程
同样以Spark为入口,进行查看。
初始化阶段:ParquetFileFormat.BuildReaderWithPartitionValues -> VectorizedParquetRecordReader.initialize -> ParquetFileReader.readFooter -> ParquetMetadataConverter.readParquetMetadata -> fromParquetMetadata -> ColumnChunkMetaData.get,其中包含valueCount(为0)。
读取时:VectorizedParquetRecordReader.nextBatch -> checkEndOfRowGroup:
1) ParquetFileReader.readNextRowGroup -> for each chunk, currentRowGroup.addColumn(chunk.descriptor.col, chunk.readAllPages())

由于getValueCount为0,所以pagesInChunk为空。
2)构造ColumnChunkPageReader:

由于page列表为空,所以totalValueCount为0,导致在构造VectorizedColumnReader时报了问题中的错误。

4. 解决方法:Parquet升级(version 1.11.1)
在新版本中,ParquetWriteSupport.write ->
MessageColumnIO.MessageColumnIORecordConsumer.endMessage ->
ColumnWriteStoreV1(ColumnWriteStoreBase).endRecord:

在endRecord中增加了每个page最大记录条数(默认2w条)的属性和检查逻辑,超出限制时会writePage,使得ColumnWriterV1的valueCount不会溢出(每次writePage后会清零)。
而对比老版本1.8.3中,ColumnWriteStoreV1.endRecord为空函数。

附:Parquet中的一个小trick
Parquet中为了节约空间,当一个long类型的值,在一定范围内时,会使用int来存储,其方法如下:
- 判断是否可以用int存储:

- 如果可以,用IntColumnChunkMetaData代替LongColumnChunkMetaData,构造时转换:

- 使用时,再转回来,IntColumnChunkMetaData.getValueCount -> intToPositiveLong():

普通的int范围是 -2^31 ~ (2^31 - 1),由于元数据信息(如valueCount等)都是非负整数,那么实际只能存储0 ~ (2^31 - 1) 范围的数。而用这种方法,可以表示0 ~ (2^32 - 1) 范围的数,表达范围也大了一倍。
附件:可用于复现的测试用例代码(依赖Spark部分类,可置于Spark工程中运行)
测试用例代码.txt 1.88KB