原文链接:http://tecdat.cn/?p=21978
本文将介绍如何在R中用rstan和rjags做贝叶斯回归分析,R中有不少包可以用来做贝叶斯回归分析,比如最早的(同时也是参考文献和例子最多的)R2WinBUGS包。这个包会调用WinBUGS软件来拟合模型,后来的JAGS软件也使用与之类似的算法来做贝叶斯分析。然而JAGS的自由度更大,扩展性也更好。近来,STAN和它对应的R包rstan一起进入了人们的视线。STAN使用的算法与WinBUGS和JAGS不同,它改用了一种更强大的算法使它能完成WinBUGS无法胜任的任务。同时Stan在计算上也更为快捷,能节约时间。
例子
设Yi为地区i=1,…,ni=1,…,n从2012年到2016年选举支持率增加的百分比。我们的模型
![]()
式中,Xji是地区i的第j个协变量。所有变量均中心化并标准化。我们选择σ2∼InvGamma(0.01,0.01)和α∼Normal(0100)作为误差方差和截距先验分布,并比较不同先验的回归系数。
加载并标准化选举数据
# 加载数据
load("elec.RData")
Y <- Y[!is.na(Y+rowSums(X))]
X <- X[!is.na(Y+rowSums(X)),]
n <- length(Y)
p <- ncol(X) ## [1] 3111 p ## [1] 15 X <- scale(X)
# 将模型拟合到大小为100的训练集,并对剩余的观测值进行预测
test <- order(runif(n))>100
table(test) ## test
## FALSE TRUE
## 100 3011 Yo <- Y[!test] # 观测数据
Xo <- X[!test,]
Yp <- Y[test] # 为预测预留的地区
Xp <- X[test,] 选举数据的探索性分析
boxplot(X, las = 3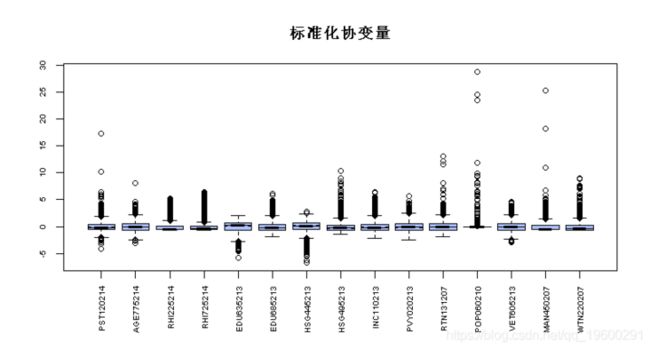
image(1:p, 1:p, main = "预测因子之间的相关性") 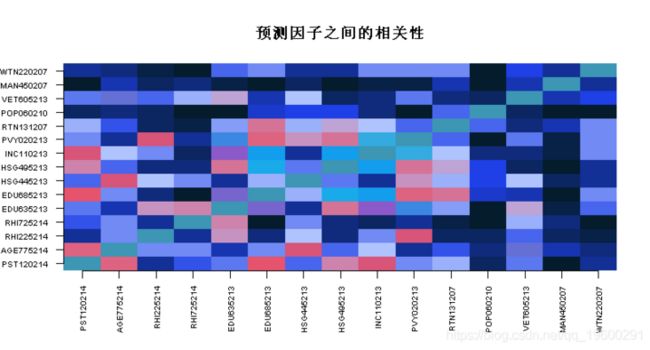
rstan中实现
统一先验分布
如果模型没有明确指定先验分布,默认情况下,Stan将在参数的合适范围内发出一个统一的先验分布。注意这个先验可能是不合适的,但是只要数据创建了一个合适的后验值就可以了。
data {
int n; // 数据项数
int k; // 预测变量数
matrix[n,k] X; // 预测变量矩阵
vector[n] Y; // 结果向量
}
parameters {
real alpha; // 截距
vector[k] beta; // 预测变量系数
real sigma; // 误差 rstan_options(auto_write = TRUE)
#fit <- stan(file = 'mlr.stan', data = dat) print(fit)
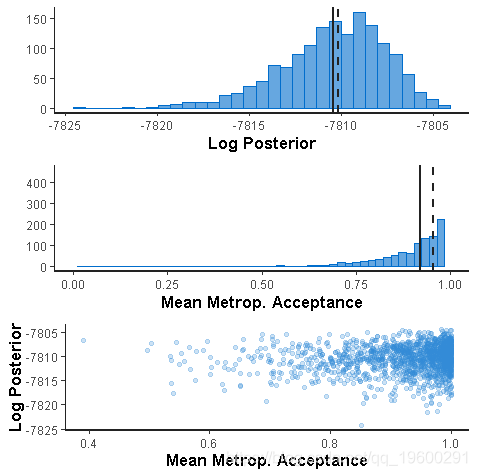
hist(fit, pars = pars)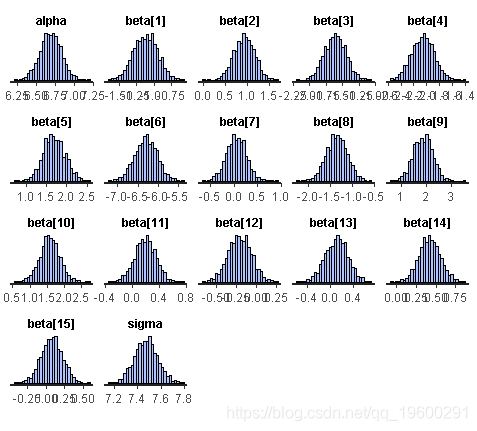
dens(fit)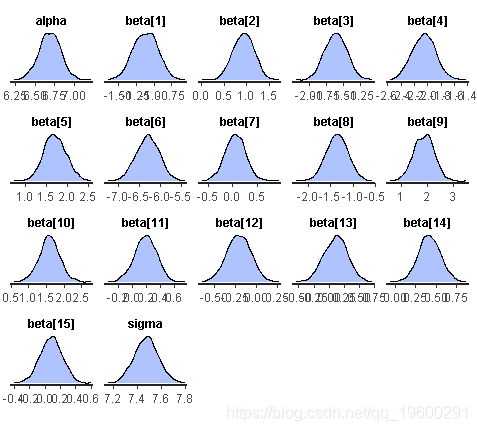
traceplot(fit)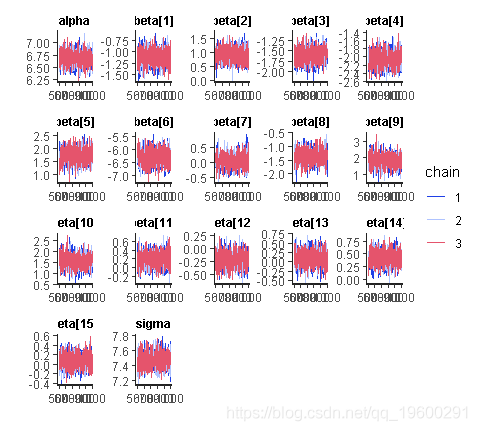
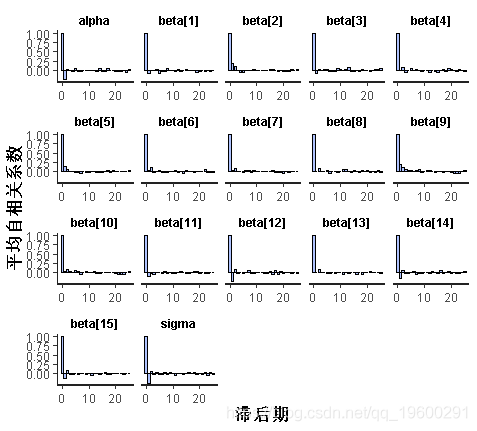

rjags中实现
用高斯先验拟合线性回归模型
library(rjags)
model{
# 预测
for(i in 1:np){
Yp[i] ~ dnorm(mup[i],inv.var)
mup[i] <- alpha + inprod(Xp[i,],beta[])
# 先验概率
alpha ~ dnorm(0, 0.01)
inv.var ~ dgamma(0.01, 0.01)
sigma <- 1/sqrt(inv.var) 在JAGS中编译模型
# 注意:Yp不发送给JAGS
jags.model(model,
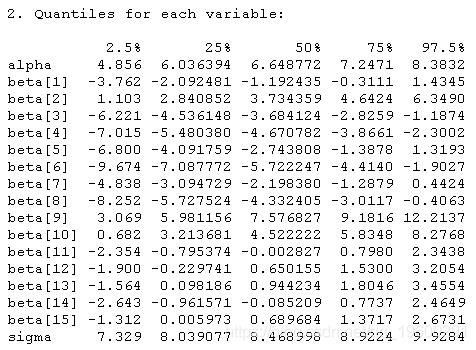
data = list(Yo=Yo,no=no,np=np,p=p,Xo=Xo,Xp=Xp)) coda.samples(model,
variable.names=c("beta","sigma","Yp","alpha"), 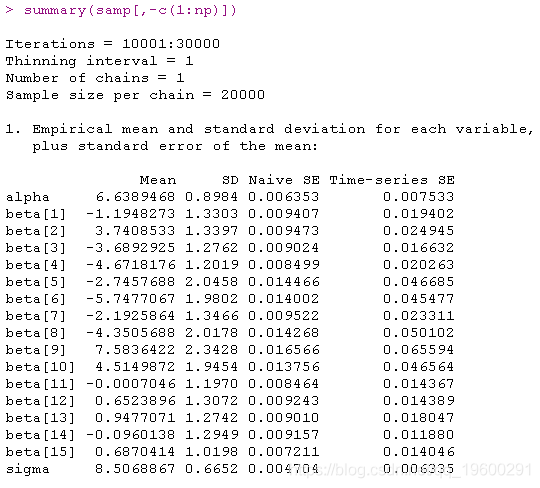
从后验预测分布(PPD)和JAGS预测分布绘制样本
#提取每个参数的样本
samps <- samp[[1]]
Yp.samps <- samps[,1:np]
#计算JAGS预测的后验平均值
beta.mn <- colMeans(beta.samps)
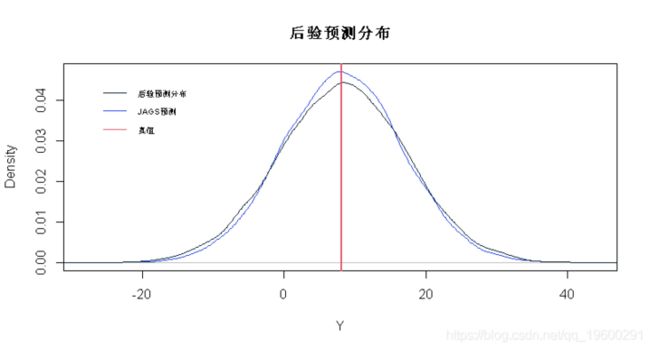
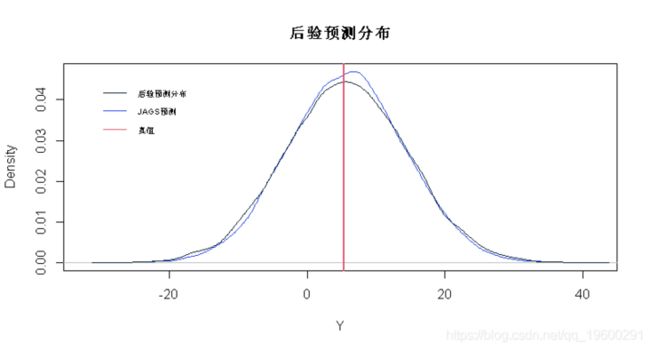
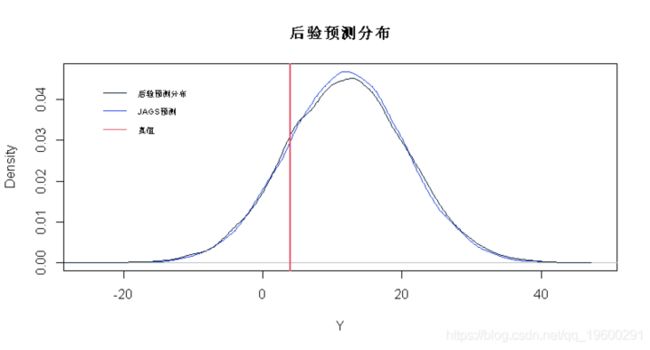
# 绘制后验预测分布和JAGS预测
for(j in 1:5)
# JAGS预测
y <- rnorm(20000,mu,sigma.mn)
plot(density(y),col=2,xlab="Y",main="PPD")
# 后验预测分布
lines(density(Yp.samps[,j]))
# 真值
abline(v=Yp[j],col=3,lwd=2) 
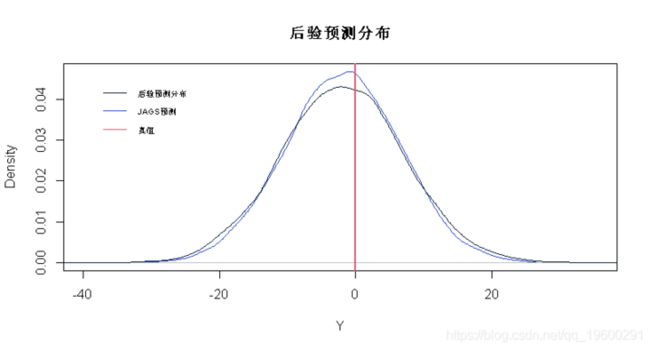
# 95% 置信区间
alpha.mn+Xp%*%beta.mn - 1.96*sigma.mn
alpha.mn+Xp%*%beta.mn + 1.96*sigma.mn ## [1] 0.9452009 # PPD 95% 置信区间
apply(Yp.samps,2,quantile,0.025)
apply(Yp.samps,2,quantile,0.975) ## [1] 0.9634673 请注意,PPD密度比JAGS预测密度略宽。这是考虑β和σ中不确定性的影响,它解释了JAGS预测的covarage略低的原因。但是,对于这些数据,JAGS预测的覆盖率仍然可以。

最受欢迎的见解
4.R语言中的block Gibbs吉布斯采样贝叶斯多元线性回归