创建基于内容的电影推荐
我们这个模型将使用基于内容的过滤方法,将推荐的电影提供给用户,并根据他们各自的偏好向他们介绍相似的电影。
制作推荐引擎时,我们会选择一种过滤技术来对数据进行分类以进行预测。 推荐引擎主要使用两种主要的过滤技术:
1、协同过滤:假设有两个相似的用户U1和U2。 U1购买了I手机,然后他/她也购买了耳机,现在U2购买了I手机,因此也推荐使用与U2相同的耳机。 综上所述, 协同过滤 是一种可以根据相似用户的'反馈'过滤出用户可能喜欢的项目 的技术。
2、基于内容的过滤:假设有两个用户U1和U2,并且用户U1看过电影M1(动作),M2(冒险)和M3(动作),并将其分别评为5星,4星和3星。 现在,让我们假设U2看过电影M4(动作),M2(冒险),我们将推荐U2电影M1,这是一部收视率最高的动作电影。 总结一下: 基于内容的过滤是一种 系统,旨在预测用户对某项商品的“评价”或“偏好”。
导入库和数据集
import pandas as pd
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics.pairwise import sigmoid_kernel
credits = pd.read_csv(r'D:\credits.csv')
movies = pd.read_csv(r'D:\tmdb_5000_movies.csv')
合并数据集:
credits.head()
movies.head()
如果同时查看这两个数据集,我们可以清楚地看到,信用数据集上的“ Movies_id”列与“电影”数据集上的“ id”列相同,并且具有相同的值,如图所示:
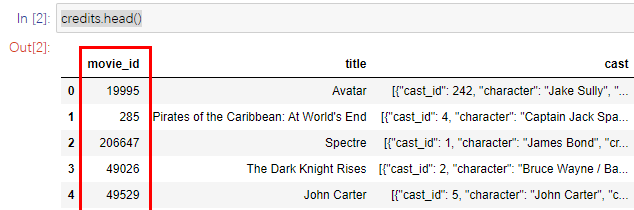
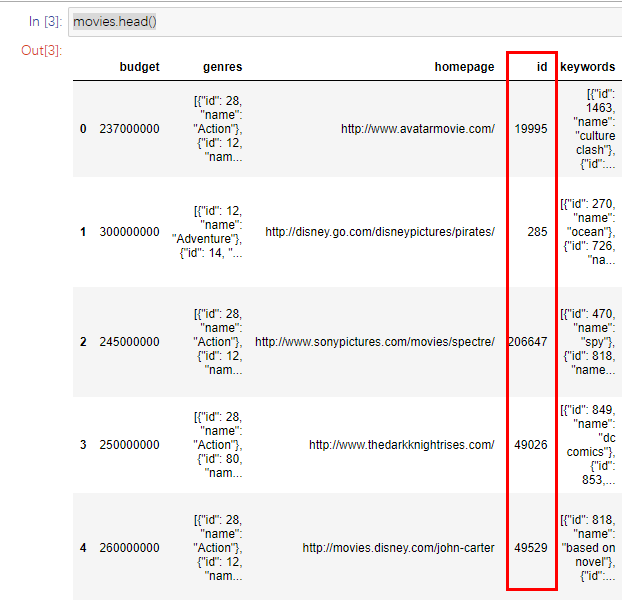
因此我们可以将“ Movie_id”列重命名为“ id”积分数据集并合并“ id”列上的两个数据集:
credits_column_renamed = credits.rename(index=str, columns={"movie_id": "id"})
movies_merged = movies.merge(credits_column_renamed, on="id")
movies_merged.head()
数据清理:
删除数据集中所有对预测无用的列,其中几乎包括除“概述”,“ orignal_title”,“ Id”,“流派”和“ orignal_language”之外的所有列:
movies_cleaned = movies_merged.drop(columns=['title_x', 'title_y', 'production_countries', 'homepage'])
movies_cleaned.head()

创建矩阵向量:
现在,我们将使用overview列(情节摘要)来挑选关键字,以推荐用户使用类似情节的电影。 概述列将包含我们将提取的内容以提出建议。 创建推荐引擎时,必须为每个电影创建矩阵向量。 在这种情况下,我们将使用tfidfvectorizer进行操作:
tfv = TfidfVectorizer(min_df=3, max_features= None,
strip_accents = 'unicode', analyzer='word', token_pattern=r'\w{1,}',
ngram_range=(1,3),
stop_words = 'english' )
补充:
Tfidfvectorizer 是NLP概念,用于将文本转换为矢量。 我们将从sklearn.feature_extraction.text导入它。 它将创建此列的文档矩阵。 此功能具有3个主要功能,它们是:
1、ngram_range:此功能将帮助模型将总览列的1-3个相似词分组。
2、stop_words =“ english”:此功能将删除所有重复的单词,例如代词,文章等。
3、strip_accents,token_pattern,分析器:这些功能将帮助摆脱标点符号和该列中的所有连词。
由于上述步骤,总览列中将出现许多nan值,我们将使用.fillna('')将其替换为空白值:
movies_cleaned['overview']= movies_cleaned['overview'].fillna('')
将其转换为稀疏矩阵:
现在,我们将使用fit_transform函数将此列转换为稀疏矩阵。 稀疏矩阵是具有许多零值和一些非零值的矩阵。 由于tfidfvectorizer,将使用等式给出该矩阵中的非零值。 所有非零项的值将在0到1之间———这步是为了之后能应用到函数Sigmoid。
tfv_matrix= tfv.fit_transform(movies_cleaned['overview'])
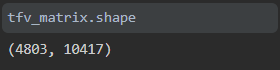
在看到矩阵的形状时,我们发现使用ngram_range创建的单词组合超过4500条记录和10000列以上。
查找不同电影之间的相似性:
我们在开始时从sklearn.metrics.pairwise导入一个名为sigmoid_kernel的库。 该库基本上将输入值转换为S型函数。 S形函数是其值在0到1之间的函数。它是通过下图给出的简单公式转换的:
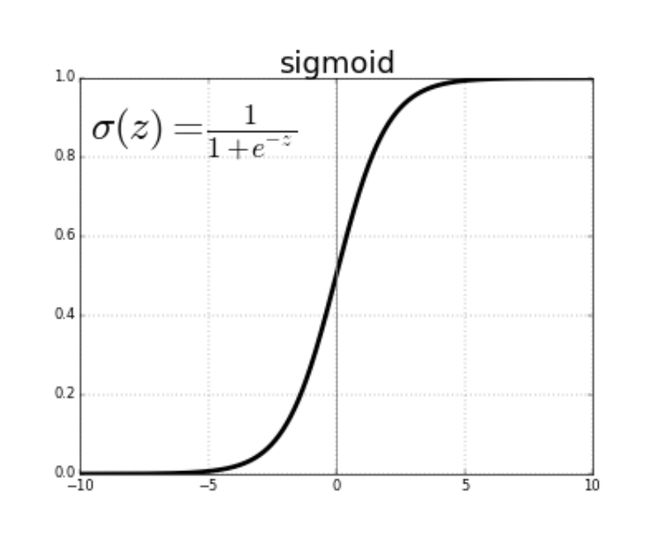
应用Sigmoid可以查看一部电影的overview相对于另一部电影的overview的相似性,将其通过S形时,我们将看到一个介于0和1之间的相似值,该值越高相似之处更多。 因此,在应用S形内核的代码中,我们将必须提供相同的矩阵 ,以便获得不同电影之间的相似性。( 相似度将基于向量值进行计算)
sig = sigmoid_kernel(tfv_matrix, tfv_matrix)

这里的sig [0]表示overview 1相对于所有其他电影的概述的相似性。
创建索引:
我们将为数据集中的所有电影创建索引,并删除所有重复的标题,这将为数据集中的每个电影标题提供唯一的索引值。
indices = pd.Series(movies_cleaned.index, index=movies_cleaned['original_title']).drop_duplicates()
结果如下:

获得建议:
我们这里定义了一个函数,其功能是可以预测所有相似的电影,现在我们知道它的工作原理。 该函数将获取电影标题,模型将从该电影标题中找到其索引值(使用索引)。 然后,它将通过一个Sigmoid对象传递该对象,该对象将提供一定范围的值,该模型将使用list(enumerate(sig []))属性将这些值转换为列表。 然后,将使用sorted()属性以降序排列列表。 然后,我们将获取前10个相似度得分,并使用movie_indices来获取电影的原始标题。
print("根据以下电影进行推荐")
a_str = input("moviename:")
def give_reccomendation(title, sig=sig):
# index to corresponding title
idx = indices[title]
# similarity score
sig_scores = list(enumerate(sig[idx]))
# sortingmovies
sig_scores = sorted(sig_scores, key=lambda x: x[1], reverse=True)
# score of 10 most similar movies
sig_scores = sig_scores[1:11]
# movie indices
movie_indices = [i[0] for i in sig_scores]
# tope recommended movies
return movies_cleaned['original_title'].iloc[movie_indices]
print(give_reccomendation(a_str))
运行结果 :
根据我们的模型,将显示相似度最高的前10部电影。

注:可以通过修改 sig_scores = sig_scores[1:11]的参数来改变推荐相似度前几的数目。
代码和数据集:
代码和数据集详见码云:https://gitee.com/chiantisun/sunchuanyi/tree/master/Movie%20Recommendation
或者可以直接从kaggle https://www.kaggle.com/tmdb/tmdb-movie-metadata导入数据集;一共有两个数据集: 分别是Credits 、Movies。
参考: https://medium.com/swlh/movie-recommendation-system-dc00430af6ec