# 第11题:查询至少有一门课与学号为“01”的学生所学课程相同的学生的学号和姓名
SELECT stu.s_id 学号,s_name 姓名 FROM student stu JOIN (
SELECT DISTINCT s_id
FROM score s RIGHT JOIN (SELECT c_id FROM score WHERE s_id = "01") a ON s.c_id= a.c_id
WHERE s.s_id<>"01")b ON stu.s_id = b.s_id;
/* 以上是自己的解法,此题思路是先找出学号为01的学生所学的课程,然后把结果当成主表与score表
以c_id相等为条件进行外连接,这样就把所有有相同课程的人给找出来了。
在多表进行联合查询的时候,若查询的字段在两个表都有的情况下,这些字段前必须加上表名。
比如此题的stu.s_id 前必须加上stu 而s_name则无需加上stu
*/
#第11题老师的写法如下:
SELECT a.s_id,a.s_name FROM student AS a
INNER JOIN(
SELECT DISTINCT s_id FROM score
WHERE c_id IN (
SELECT c_id FROM score
WHERE s_id ="01"
)AND s_id !="01"
)AS b ON a.s_id=b.s_id;
# 第12题:查询与学号为“01”的学生所学课程完全相同的学生的学号和姓名
SELECT stu.s_id 学号,s_name 姓名 FROM student stu JOIN (
SELECT s.s_id FROM score s
LEFT JOIN (SELECT c_id FROM score WHERE s_id = "01") a
ON s.c_id= a.c_id
WHERE s.s_id<>"01" AND a.c_id IS NOT NULL
GROUP BY s.s_id
HAVING COUNT( DISTINCT s.c_id)= (SELECT COUNT(c_id) FROM score WHERE s_id = "01" )
)b ON stu.s_id = b.s_id
/* 以上是自己的解法,此题思路与第11题大致类似,先找出学号为01的学生所学的课程,然后把此结果当成从表与
主表score以c_id相等为条件进行外连接(那么此时会行成一个表,大致为:凡是与01号学生所学课程相同的那一行数据,从表的
c_id列都会有该课程的id,其余为null),所以只需要把01号学升自己排除且把从表的c_id字段为null的行排除后,按照s_id进行
分组,然后统计课程数(需要使用distinct,用于排重)与01号学生学的课程一样就行了。
我在做这题的时候,有2个没考虑周全的问题。
1:count()是按照*、s.c_id来的,没有对s.c_id去重
2:没有排除a.c_id 为null的数据,这样会带入脏数据。比如有个学生学的课程id是7 8 9,也就意味着该学生有3行a.c_id列为null的
数据,统计时会把该学生统计进去。
总结:这题我感觉还是蛮麻烦的,很多细节点。
*/
# 第12题:老师的写法(他貌似第一次也写错了,考虑的不周全)
SELECT * FROM student
WHERE s_id IN (
SELECT s_id FROM score
WHERE s_id!="01"
GROUP BY s_id HAVING COUNT(DISTINCT c_id)=(SELECT COUNT(DISTINCT c_id) FROM score WHERE s_id="01")
)
AND s_id NOT IN (
SELECT DISTINCT s_id FROM score
WHERE c_id NOT IN(
SELECT c_id FROM score
WHERE s_id="01")
)
# 第13、14题这边没看到题目,所以就没贴了。为了保证与其同步后面好复习,我也就直接跳到15题了
# 第15题:查询2门及以上不及格(score<60)的同学的学号、姓名及其平均成绩
SELECT s.s_id 学号, stu.s_name 姓名, AVG(s_score)平均成绩
FROM score s JOIN student stu
ON s.s_id = stu.s_id
WHERE s_score< 60
GROUP BY s.s_id
HAVING COUNT(DISTINCT s.c_id)>=2;
/* 这题比较简单,就是先联合查询,然后筛选出哪些课的成绩是小于60的,然后再按照id进行分组,
再利用count统计结果,count内用distinct是为了排重,有可能某个人的一门课有2次成绩,当然这个
要看设计表时如何设计的,我就根据自己的习惯加上了。
*/
# 第15题老师的做法
SELECT a.s_id,a.s_name,AVG(s_score) FROM student AS a
INNER JOIN score AS b
ON a.s_id = b.s_id
WHERE a.s_id IN (
SELECT s_id FROM score
WHERE s_score<60
GROUP BY s_id HAVING COUNT(DISTINCT c_id)>=2
)
GROUP BY s_id,s_name;
# 第16题: 检索“01”课程分数小于60,按分数降序排列的学生信息
SELECT s.s_id 学号,s_name 性名,s_sex 性别,s_birth 出生日期,c_id 课程,s_score 分数
FROM score s JOIN student stu
ON s.s_id = stu.s_id
WHERE c_id = "01" AND s_score<60
ORDER BY s_score DESC;
# 第17题 :按平均成绩从高到低显示所有学生的所有课程的成绩以及平均成绩
SELECT s.s_id 学号,s.c_id 课程,s.s_score 成绩, a.平均成绩 平均成绩
FROM score s LEFT JOIN (SELECT s_id,AVG(s_score) 平均成绩 FROM score GROUP BY s_id) a
ON s.s_id = a.s_id
ORDER BY 平均成绩 DESC,成绩 DESC;
我的写法看起来不舒服,不符合日常需求。如下:
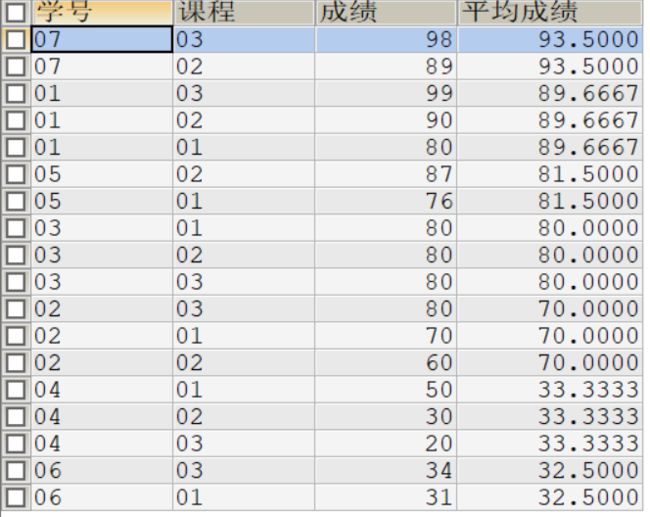
# 第17题老师的写法,这种方法我觉得还是很6的
SELECT s_id 学号
,MAX(CASE WHEN c_id="01" THEN s_score ELSE NULL END) 语文
,MAX(CASE WHEN c_id="02" THEN s_score ELSE NULL END) 数学
,MAX(CASE WHEN c_id="03" THEN s_score ELSE NULL END) 英语
,AVG(s_score) 平均成绩
FROM score
GROUP BY s_id
ORDER BY 平均成绩 DESC;
执行结果如下:

/*
老师这种方法我觉得还是很6的,
巧用了case when then 与 max()
该题注意的点是,使用 group by后select后必须是被分组的字段或者是聚合函数,
具体讲解见:https://blog.csdn.net/qq403580298/article/details/90756352
因按照s_id分组后,每个c_id其实只有一个值,所以使用max/min/avg等聚合函数都OK
最后取得数都是一样的
对了 在使用case when 的时候 经常漏掉后面的end
*/
# 第18题: 查询各科成绩最高分、最低分、平均分、及格率,中等率,优良率,优秀率:及格>=60,中等为[70,80),优良为:[80,90),优秀为>=90
SELECT s.c_id 课程id
,c_name 课程名
,MAX(s_score) 最高分
,MIN(s_score) 最低分
,AVG(s_score) 平均分
,SUM(CASE WHEN s_score>=60 THEN 1 ELSE 0 END)/COUNT(s_score) 及格率
,SUM(CASE WHEN s_score>=70 AND s_score<80 THEN 1 ELSE 0 END)/COUNT(s_score) 中等率
,SUM(CASE WHEN s_score>=80 AND s_score<90 THEN 1 ELSE 0 END)/COUNT(s_score) 优良率
,SUM(CASE WHEN s_score>=90 THEN 1 ELSE 0 END)/COUNT(s_score) 优秀率
FROM score s JOIN course c
ON s.c_id = c.c_id
GROUP BY s.c_id;
执行结果如下:

/*
此题主要难点是在求各个课程的及格率、中等率..上
思路与17题类似 巧用了 case when then else与 sum()。
即设定一个条件,当分数满足这个条件时+1,不满足时+0。
另外补充一个把小数转换成百分数的方法:
select concat(0.6667*100,'%') 得出的结果为:66.6700%
此时会觉得保留小数后两位比较好,那么可以这样写:select concat(round(0.6667*100,2),'%')
所以针对上面的SQL可以写成如下(看起来比较绕):
*/
SELECT s.c_id 课程id
,c_name 课程名
,MAX(s_score) 最高分
,MIN(s_score) 最低分
,ROUND(AVG(s_score),2) 平均分
,CONCAT(ROUND(SUM(CASE WHEN s_score>=60 THEN 1 ELSE 0 END)/COUNT(s_score)*100,2),'%')及格率
,CONCAT(ROUND(SUM(CASE WHEN s_score>=70 AND s_score<80 THEN 1 ELSE 0 END)/COUNT(s_score)*100,2),'%') 中等率
,CONCAT(ROUND(SUM(CASE WHEN s_score>=80 AND s_score<90 THEN 1 ELSE 0 END)/COUNT(s_score)*100,2),'%') 优良率
,CONCAT(ROUND(SUM(CASE WHEN s_score>=90 THEN 1 ELSE 0 END)/COUNT(s_score)*100,2),'%') 优秀率
FROM score s JOIN course c
ON s.c_id = c.c_id
GROUP BY s.c_id;
改进后执行如下:

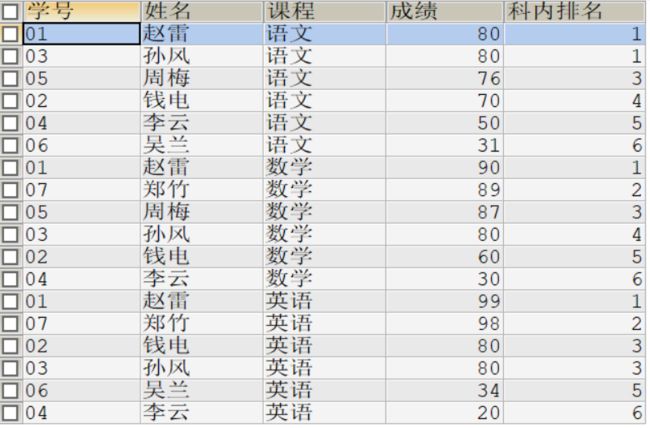
# 第19题 :按各科成绩进行排序,并显示排名
#rank()over()的使用
SELECT s.s_id 学号,s_name 姓名,c_name 课程,s_score 成绩
,rank()over(PARTITION BY s.c_id ORDER BY s_score DESC) 科内排名
FROM student stu
JOIN score s ON stu.s_id = s.s_id
JOIN course c ON s.c_id = c.c_id;
#执行结果如下
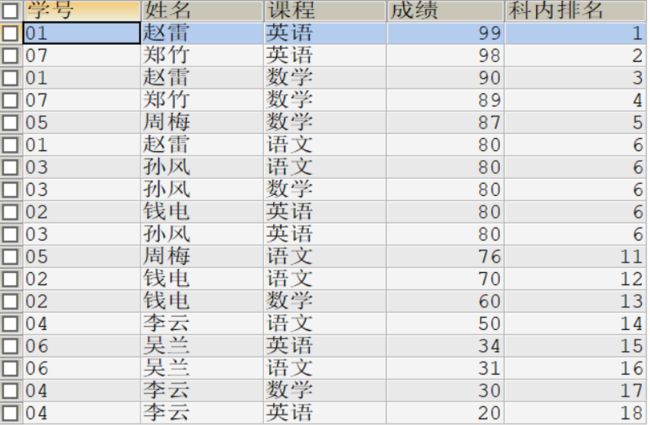
#rank()over()的使用,不使用partition by的效果
SELECT s.s_id 学号,s_name 姓名,c_name 课程,s_score 成绩
,rank()over(ORDER BY s_score DESC) 科内排名
FROM student stu
JOIN score s ON stu.s_id = s.s_id
JOIN course c ON s.c_id = c.c_id;
#执行结果如下
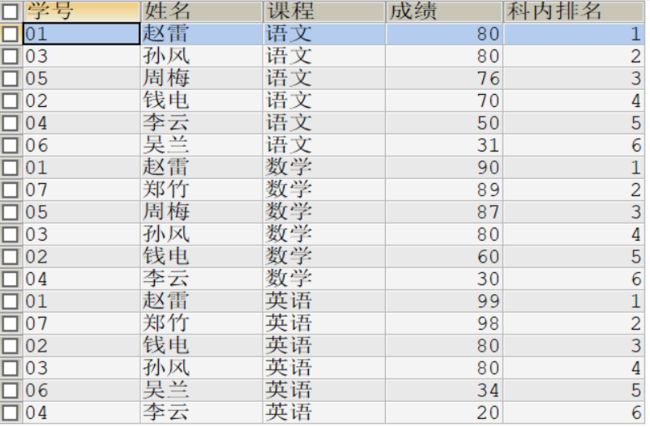
#row_number()over()的使用
SELECT s.s_id 学号,s_name 姓名,c_name 课程,s_score 成绩
,row_number()over(PARTITION BY s.c_id ORDER BY s_score DESC) 科内排名
FROM student stu
JOIN score s ON stu.s_id = s.s_id
JOIN course c ON s.c_id = c.c_id;
#执行结果如下
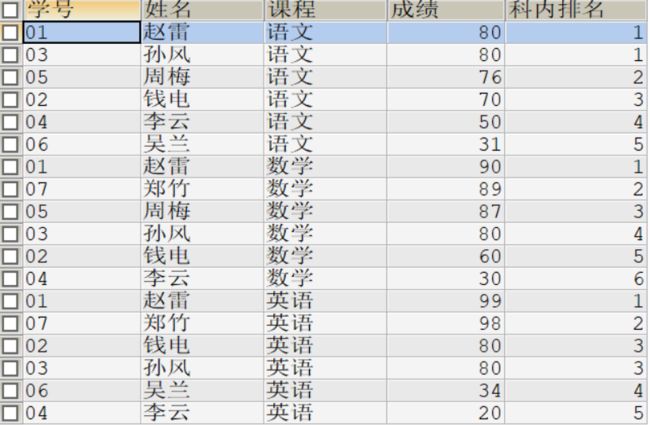
#dense_rank()over()的使用
SELECT s.s_id 学号,s_name 姓名,c_name 课程,s_score 成绩
,dense_rank()over(PARTITION BY s.c_id ORDER BY s_score DESC) 科内排名
FROM student stu
JOIN score s ON stu.s_id = s.s_id
JOIN course c ON s.c_id = c.c_id;
#执行结果如下
/*
总结:
row_number()over(partition by字段1 order by 字段2) 的结果是每一行记录生成一个序号,依次排序且排序的序号不会重复
rank()over(partition by字段1 order by 字段2) 的结果会考虑排序字段值相同的情况,若排序字段的值相同则其序号是一样的,
后续不同字段值的序号为(前一行序号+N,其中N为前一个字段值重复的行数),比如 1 1 3 4 4 4 7。
dense_rank()over(partition by字段1 order by 字段2) 的结果也会考虑排序字段值相同的情况,即排序字段的值相同那么他们的序号是一样的,但是与rank()的区别是后续不同字段值的序号为(前一行序号+1),比如 1 1 2 2 3 4 5
另外:over(partition by字段1 order by 字段2)中的partition by 字段1 是可以省略的但是order by 字段2 不可省略
*/
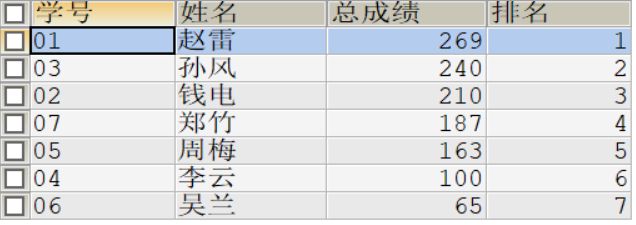
#第20题:对学生总成绩从大到小排序
SELECT stu.s_id 学号, stu.s_name 姓名
,SUM(s.s_score) 总成绩,rank () over (ORDER BY SUM(s.s_score) DESC) 排名
FROM student stu
JOIN score s ON stu.s_id = s.s_id
GROUP BY stu.s_id;
#执行结果如下