一、引言
文本内容有点多,如果有写错或者不好地方,还请多多指教~~~~~~~
二、倔强青铜
2.1 多线程一定快吗?
我们先来看下面一段代码,有两个方法对各自a、b属性进行累加操作,其中concurrency方法是采用多线程进行操作,结果如下:
public class ConcurrencyTest {
// 累加次数
private static final long count = 10000L;
public static void main(String[] args) throws InterruptedException {
concurrency();
serial();
}
/**
* 多线程累加
*
* @throws InterruptedException
*/
private static void concurrency() throws InterruptedException {
long start = System.currentTimeMillis();
// 启动新线程执行运行操作
Thread thread = new Thread(new Runnable() {
@Override
public void run() {
int a = 0;
for (int i = 0; i < count; i++) {
a += 5;
}
}
});
thread.start();
int b = 0;
for (int i = 0; i < count; i++) {
b--;
}
// 等线程执行完
thread.join();
long end = System.currentTimeMillis() - start;
System.out.println("concurrency 总共耗时" + end);
}
/**
* 单线程累加
*/
private static void serial() {
long start = System.currentTimeMillis();
int a = 0;
for (int i = 0; i < count; i++) {
a += 5;
}
int b = 0;
for (int i = 0; i < count; i++) {
b--;
}
long end = System.currentTimeMillis() - start;
System.out.println("serial 总共耗时" + end);
}
}
那这边的答案是"不一定"的,小编测试了几组数据如下(抽取部分结果):
多线程与单线程效率测试
| 循环次数 | 单线程执行 | 多线程执行 | 效率 |
|---|---|---|---|
| 1万 | 0 | 1 | 慢 |
| 1万 | 0 | 0 | 相等 |
| 十万 | 2 | 2 | 相等 |
| 十万 | 1 | 1 | 相等 |
由以上的结果可以明确我们的答案是正确的,那为什么多线程在某些情况下会比单线程还要慢呢? 这是因为多线程有创建和上下文切换的开销。
2.2 上下文切换
那什么是上下文切换呢?
目前来说即使是单核处理器也支持多线程执行代码,CPU通过给个线程分配CPU时间片来实现这个机制。时间片是CPU分配给各个线程的时间,因为时间片一般是几十毫秒,所以CPU需要通过不停地切换线程来执行。 假设当我们线程A获得CPU分配的时间片等于10毫秒,执行10毫秒之后,CPU需要切换到线程B去执行程序。等线程B的时间片执行完事了,又切回线程A继续执行。
显然易见,我们CPU相当于是循环的切换上下文,来达到同时执行的效果。当前执行完一个时间片后会切换下一个任务。但是在切换前会保存当前任务的状态,方便下次切换会这个任务的时候,可以恢复这个任务之前的状态。 所以任务从保存到再次被加载的过程就是一次上下文切换。
2.3 测试上下文切换次数
这里我们需要使用一个命令叫做:"vmstat 1",这个命令是linux系统上的,可对操作系统的进程、虚拟内存、CPU活动进行监控。看下图CS(Content Switch) 表示上下文切换的次数,从图可见系统一般CS的值维持在600~800之间,当我们一直在运行ConcurrencyTest程序时,很明细发现CS飙升到1000以上。

2.4 Java内存模型
在我们学习sync原理之前,我们需要搞清楚Java内存模型的一个概念知识。很重要、很重要、很重要
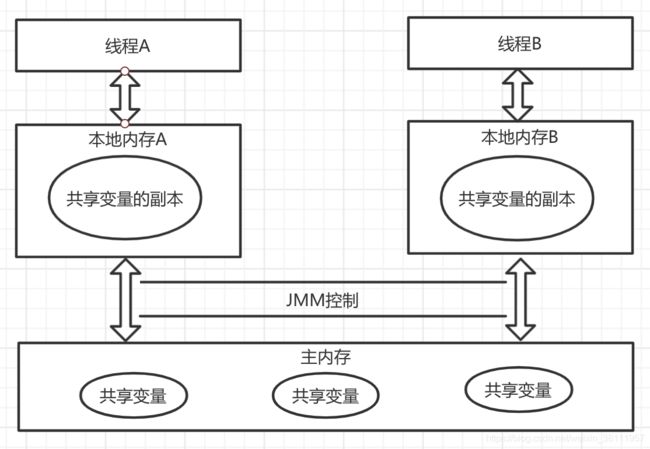
Java内存模型全称:Java Memory Model ,简称Java内存模型或者JMM,Java线程之间的通信由JMM来控制,JMM决定一个线程对共享变量的写入,何时对另外一个线程可见。我们由图可见,线程之间的共享变量是存储在主内存当中,每一个线程都有一个属于自己的本地内存(也可以叫做工作内存),这个本地内存中存储了主内存当中的共享变量。就相当于把主内存的共享变量copy了一份给自己。为了提供效率,线程是不会直接与主内存进行打交道,而是通过本地内存来进行数据的读取。
如果线程A与线程B之间要通信,需要经历下面两个步骤:
1 )线程A把本地内存A中更新过的共享变量,刷新到主内存当中去。
2 )线程B到主内存中重新读取更新后的共享变量。
2.5 主内存与工作内存之间的数据交互过程
那么主内存与工作内存之间的交互经过了哪些步骤呢?
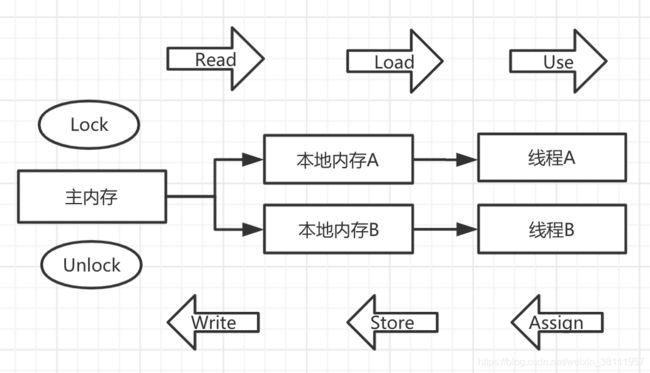
lock(锁定):作用于主内存的变量,把一个变量标识为一条线程独占状态。
unlock(解锁):作用于主内存的变量,把一个处于锁定状态的变量释放出来,释放之后的变量才可以被其他线程锁定。
read(读取):作用于主内存的变量,读取主内存变量的值。
load(载入):作用于主内存的变量,把read操作从主内存中得到的变量值放入到线程本地内存的变量副本中。
use(使用):作用于工作内存的变量,把工作内存中的一个变量传递给执行引擎。
assign(赋值):作用域工作内存的变量,它把一个从执行引擎接收到的值赋值给工作内存的变量。
store(存储):作用域工作内存的变量,把工作内存中的一个变量值传输到主内存中,以便随后的write操作。
write(写入):作用域工作内存的变量,把stroe操作从工作内存中一个变量的值传送到主内存的变量中去。
上个笔记图: 更加详细的解释如上几个步骤

JMM是一种规范,其中定义几条规则,小编挑选出相对本文比较重要的:
1、如果想要把一个变量从主内存复制到工作内存,就需要按照顺序执行read和load操作,如果把变量从工作内存同步到主内存中,就要按照顺序执行store和write操作。但Java内存模型只要求上述操作必须按照顺序执行,而没有保证必须是连续执行。
2、程序中如果有同步操作才会有lock和unlock操作,一个变量在同一个时刻只允许一条线程对其进行lock操作,但lock操作可以被同一条线程重复执行多次,执行多次后,必须执行相对应次数但unlock操作,变量才会被解锁。lock和unlock必须成对出现。
3、如果对一个变量执行lock操作,将会清空工作内存中此变量的值,在执行引擎使用这个变量前需要重新执行load或者assign操作初始化变量但值。
4、java内存模型同步规则小编暂时提到这么多,感兴趣的小伙伴可以自行去了解一下
三、秩序白银
3.1 多线程带来的可见性问题
什么是可见性问题呢?
所谓可见性:一个线程对主内存的修改可以及时被其他线程观察到。
当一个共享属性,被线程二修改了,但是线程一无法获得最新的值,导致死循环。原因Java内存模型也说清楚了,线程是和本地内存做交互的。
1、线程一把falg属性读取到线程私有的本地内存中,值为true。
2、线程二把falg属性修改为false,并且刷新到主内存当中,但是线程一它是不知道falg被修改了。
public class SyncExample5 {
static boolean falg = true;
// 锁对象
static Object lock = new Object();
public static void main(String[] args) throws InterruptedException {
// 线程一
new Thread(new Runnable() {
@Override
public void run() {
while (falg) {
// 默认不可见,死循环,放开以下注释即可解决不可见操作
// 方式一,加上sycn操作即可解决可见性问题
// synchronized (lock){}
// 方式二, println 方法实现加上了同步机制,保证每次输出都是最新值
// System.out.println(falg);
}
}
}).start();
// 睡眠两秒
Thread.sleep(2000L);
// 线程二
new Thread(new Runnable() {
@Override
public void run() {
falg = false;
System.out.println("falg 值已修改");
}
}).start();
}
}
sync怎么解决可见性问题呢?
这个就涉及到本地内存与工作内存交互的步骤了,还记得文本上面有讲的8个步骤吗?
如果程序中有加同步的机制,则会有Lock、Unlock操作,Lock操作会使本地内存中的属性失效,从而去主内存中重新读取数据。
3.2 多线程带来的原子性问题
什么是原子性问题呢?
所谓原子性:提供了互斥访问,同一个时刻只能有一个线程来对它进行操作。
这里一次任务累加1千次,同时启动5个线程进行累加,最后的结果正常应该是5000才对,但由于多线程会造成不一样的结果。
public class SyncExample6 {
static int index = 0;
static Object lock = new Object();
public static void main(String[] args) throws InterruptedException {
// index 累加 1000次,使用lambda表达式
Runnable task = () -> {
// 不加sync则不能保证原子操作
// synchronized (lock) {
for (int i = 0; i < 1000; i++) {
index++;
}
// }
};
// 启动五个线程来执行任务
for (int i = 0; i < 5; i++) {
Thread thread = new Thread(task);
thread.start();
}
// 为了代码直观直接睡眠等待结果,实际需要调用线程的join方法等待线程结束
Thread.sleep(2000L);
System.out.println("index = " + index);
}
}
我们使用java命令来编译以上代码:
javac SyncExample6.java
javap -p -v SyncExample6.class ,这样我们就能看到sync到底在底层做了什么事。
编译代码之后找到“lambda0”,因为我们同步机制是写在main方法中,用lambda表达式所写。
private static void lambda$main$0();
descriptor: ()V
flags: ACC_PRIVATE, ACC_STATIC, ACC_SYNTHETIC
Code:
stack=2, locals=3, args_size=0
0: iconst_0
1: istore_0
2: iload_0
3: sipush 1000
6: if_icmpge 39
9: getstatic #18 // Field lock:Ljava/lang/Object;
12: dup
13: astore_1
14: monitorenter
15: getstatic #14 // Field index:I
18: iconst_1
19: iadd
20: putstatic #14 // Field index:I
23: aload_1
24: monitorexit
25: goto 33
28: astore_2
造成原子性的问题的原因是什么?
这个就涉及到文章一开始所讲的上下文切换的知识点,index ++ 一共涉及到4条指令,如下
15: getstatic #14 // 步骤一:获取index值
18: iconst_1 // 步骤二:准备常量1
19: iadd // 步骤三:相加操作
20: putstatic #14 // 步骤四:重新赋值
以上这4条指令就是index ++ 的四个步骤,假设我们线程一进来,执行到步骤三,这个时候CPU切换线程。切换到线程二,线程二执行步骤一,这个时候index的值还是等于0,因为线程一并没有执行步骤四就被切换上下文了。 等线程二执行完成,又切回到线程一,线程一会接着执行步骤三,并不会重新获取index的值,这就导致计算结果不正确了。
sync怎么解决原子性问题呢?
14: monitorenter
15: getstatic #14 // Field index:I
18: iconst_1
19: iadd
20: putstatic #14 // Field index:I
23: aload_1
24: monitorexit
当我们加上了sync同步机制之后, 会插入monitorenter、monitorexit两条指令。
又到了假设环节:假设线程一执行到步骤三,被切换到线程二,当我们线程二执行monitorenter这个指令会发现,这个对象已经被其他线程占用了,所以就只能等待着不会进行操作。现在又切回到线程一,线程一操作完整个步骤执行monitorexit来释放锁。这个时候线程二才可以获得锁。 这样一操作就能保证同一个时刻只能有一个线程来对它进行操作,从而保证原子性。
monitorenter指令是在编译后插入到同步代码块到开始位置,而monitorexit是插入到同步代码块结束位置和异常位置。JVM需要保障每个monitorenter必须有对应的monitorexit。任何一个对象都会有一个monitor来关联,当且一个monitor被持有后,它就处理锁定状态。当线程执行到monitorenter指令的时候,将会尝试获取对象所对应的monitor的所有权,即尝试获取锁对象。
3.3 多线程带来的有序性问题
什么是有序性问题呢?
有序性,指的是程序中代码的执行顺序,Java在编译时和运行时会对代码进行优化,会导致程序最终的执行顺序不一定就是我们编写代码时的顺序。
// 指定使用并发测试
@JCStressTest
// 预测的结果与类型,附加描述信息,如果1,4 则是ok,如果结果有为0也能勉强接受
@Outcome(id = {"1", "4"}, expect = Expect.ACCEPTABLE, desc = "ok")
@Outcome(id = {"0"}, expect = Expect.ACCEPTABLE_INTERESTING, desc = "denger")
// 标注需要测试的类
@State
public class TestJMM {
int num = 0;
boolean ready = false;
@Actor
public void actor1(I_Result r) {
if (ready) {
r.r1 = num + num;
} else {
r.r1 = 1;
}
}
@Actor
public void actor2(I_Result r) {
num = 2;
ready = true;
}
}
是时候贴一段代码凑文章字数了,这里代码用了Jcstress高并发测试框架,目的是为了能够演示有序性所导致到问题。
小伙伴可以先仔细看以上代码,假设actor1、actor2 各有一个线程进来,想想 r.r1 的值会产生几种情况。
小编告诉你吧,其实答案有三种,分别是:1、4、0
出现1的情况:
1)假设 actor1先获得执行权,ready = false ,则 r.r1 = 1;
2)假设 actor2先获得执行权,执行到num = 2, 线程切换到actor1,ready还是为false,r.r1 = 1;
出现4的情况:
1)假设actor2先获得执行权,执行完,此时ready = true,num = 2 ,等到在执行actor1时,结果为4;
出现0的情况:
1)这里就是重点了,假设actor2获得执行权,由于指令重排序导致actor2代码顺序更换。
这个时候执行到ready = true,线程切换到actor1,这个时候ready已经等于true了,但是num还是0,所以就出现了0的情况。
@Actor
public void actor2(I_Result r) {
// 由于指令重排序,导致下面代码更换了顺序,如下:
ready = true;
num = 2;
}
我们用压测来执行以下代码吧,使用maven 执行 clean install,会生成一个jar包,直接用命令启动jar包就行了,Jcstress使用方式小编就不多说了,感兴趣的小伙伴可以自行学习下, 执行的结果也符合我们预期的值。

sync怎么解决有序性问题呢?
这个时候只需要在actor1和actor2分别加上锁操作,由于它们的锁对象都是同一个,哪怕由于指令重排序执行到actor2的ready = true,这个时候线程切换到actor1,但是有加锁所以actor1也只能等着。 等到actor2 把 num = 2 执行完,actor1 才可以拿到锁对象。
// 指定使用并发测试
@JCStressTest
// 预测的结果与类型,附加描述信息
@Outcome(id = {"1"}, expect = Expect.ACCEPTABLE, desc = "ok")
// 因为sync解决有序性问题,不会有0的出现,为了方便观察结果,我们把4设置成能勉强接受的值
@Outcome(id = {"4"}, expect = Expect.ACCEPTABLE_INTERESTING, desc = "denger")
@Outcome(id = {"0"}, expect = Expect.ACCEPTABLE_INTERESTING, desc = "denger")
// 标注需要测试的类
@State
public class TestJMM {
int num = 0;
boolean ready = false;
Object lock = new Object();
@Actor
public void actor1(I_Result r) {
synchronized (lock) {
if (ready) {
r.r1 = num + num;
} else {
r.r1 = 1;
}
}
}
@Actor
public void actor2(I_Result r) {
synchronized (lock) {
num = 2;
ready = true;
}
}
}
测试结果如下:

四、荣耀黄金
4.1 sync可重入特性
什么是可重入呢?
即一个线程可以多次执行synchronzied重复获取同一把锁。 sync底层锁对象中包含了一个计数器(recursions 变量),会记录线程获得了几次锁。 当我们同一个线程获得了锁,计数器则会+1,执行完同步代码块,计数器-1。 直到计数器的数量为0,就释放这个锁对象。
public class SyncExample8 {
public static void main(String[] args) {
new MyThread().start();
}
}
class MyThread extends Thread {
@Override
public void run() {
synchronized (MyThread.class) {
System.out.println(getName() + "进入了同步代码块1");
synchronized (MyThread.class) {
System.out.println(getName() + "进入了同步代码块2");
}
}
}
}
运行结果如下,我们可以很明细的看出在输出“同步代码块1”之后,不需要等待锁释放,即可进入第二个同步代码块。这样的一个特性可以避免死锁的发生,也可以更好的封装代码(即:同步代码块中的代码,可以分成多个方法来写)。
输入结果如下:
Thread-0进入了同步代码块1
Thread-0进入了同步代码块2
4.2 sync不可中断特性
不可中断只指,线程二在等待线程一释放锁的时候,是不可被中断的。
当一个线程获得锁之后,另外一个线程一直处于堵塞或者等待状态,前一个线程不释放锁,后一个线程会一直被阻塞或等待,所以sync是不可中断锁。
public class SyncExample9 {
private static Object lock = new Object();
public static void main(String[] args) throws InterruptedException {
Runnable run = () -> {
synchronized (lock) {
String name = Thread.currentThread().getName();
System.out.println(name + "进入同步代码块");
try {
// 让线程一持有锁
Thread.sleep(888888L);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
};
// 创建线程一先执行同步代码快
Thread t1 = new Thread(run);
t1.start();
// 主线程睡眠一下,保证上面线程先执行
Thread.sleep(1000L);
// 后开启线程取执
Thread t2 = new Thread(run);
t2.start();
System.out.println("开始中断线程二");
// 强行线程二中断
t2.interrupt();
System.out.println("线程一状态" + t1.getState());
System.out.println("线程二状态" + t2.getState());
}
}
当我们线程一进入同步代码之后,一直持有锁,并且睡眠了(也证实了sleep方法睡眠不会释放锁对象)。
此时线程二启动去尝试获取锁,获取失败之后就变成堵塞状态,哪怕我们强行中断线程二,最后看到线程二的状态仍是堵塞的。
Thread-0进入同步代码块
开始中断线程二
线程一状态TIMED_WAITING
线程二状态BLOCKED
4.3 反汇编学习sync原理
使用javap反汇编java代码,引入monitor概念。
public class SyncExample10 {
private static Object lock = new Object();
public static void main(String[] args) throws InterruptedException {
synchronized (lock) {
System.out.println("1");
}
}
public synchronized void test() {
System.out.println("1");
}
}
我们使用javac、javap 两个命令对SyncExample10来进行编译
javac SyncExample10.java
javap -v -p SyncExample10.class
编译后的指令就如下啦,我们主要看main方法里面的内容,着重看 monitorenter、monitorexit 两个指令
public static void main(java.lang.String[]) throws java.lang.InterruptedException;
descriptor: ([Ljava/lang/String;)V
flags: ACC_PUBLIC, ACC_STATIC
Code:
stack=2, locals=3, args_size=1
0: getstatic #2
3: dup
4: astore_1
5: monitorenter // 这里
6: getstatic #3
9: ldc #4
11: invokevirtual #5
14: aload_1
15: monitorexit // 这里
16: goto 24
19: astore_2
20: aload_1
21: monitorexit // 这里
22: aload_2
23: athrow
24: return
monitorenter 指令
当我们进入同步代码块的时候会先执行monitorenter指令,每一个对象都会和一个monitor监视器关联,监视器被占用时会被锁住,其他线程无法来获取该monitor。当其他线程执行monitorente指令时,它会尝试去获取当前对象对应的monitor的所有权。
monitor里面有两个很重要成员变量:
owner: 当一个线程获取到该对象的锁,就把线程当前赋值给owner。
recursions:会记录线程拥有锁的次数,重复获取锁当前变量也会+1,当一个线程拥有monitor后,其他线程只能等待。
monitorenter执行流程如下:
1)若monitor的进入次数为0时,线程可以进入monitor,并将monitor进入的次数(recursions)+1,当前线程成为montiro的owner(所有者);
2)若线程已拥有monitor的所有权,允许它重入monitor,进入一次次数+1 (可重复特性);
3)若其他线程已经占有monitor,那么当前尝试获取monitor的线程会被阻塞,一直到monitor进入次数为变0,才能重新被再次获取。
monitorexit 指令
既然我们同步代码块进入时计数器会执行+1操作,那么我们退出的时候,计数器当然要执行-1;
要注意,能够执行monitorexit指令的线程,一定是拥有当前对象的monitor所有权的线程。 当我们执行monitorexit指令计数器减到为0时,当前线程就不再拥有monitor所有权。其他被阻塞的线程即可再一次去尝试获取这个monitor的所有权。
大家仔细看看上面编译出来的指令,其实monitoreexit是有两个的,为什么呢?
因为需要保证如果同步代码块执行抛出了异常,则也需要释放锁对象。等到下次面试官问你,synchronized如果抛异常了,会不会释放锁对象,答案是:会的。
ACC_SYNCHRONIZED 修饰
刚刚我们所看到的是mian方法中同步代码块所编译后的指令,以下是同步方法编译后指令
可以看到同步方法在反汇编后,会增加ACC_SYNCHRONIZED修饰,会隐式调用monitorenter、mointorexit,在执行同步方法前会调用monitorenter,在方法结束之后会调用monitorexit。
public synchronized void test();
descriptor: ()V
flags: ACC_PUBLIC, ACC_SYNCHRONIZED
Code:
stack=2, locals=1, args_size=1
0: getstatic #3 // Field java/lang/System.out:Ljava/io/PrintStream;
3: ldc #4 // String 1
5: invokevirtual #5 // Method java/io/PrintStream.println:(Ljava/lang/String;)V
8: return
LineNumberTable:
line 19: 0
line 20: 8
五、尊贵铂金
5.1 montior 监视器锁
刚刚上文有提到每一个对象都会和一个monitor监视器关联,真正的锁都是靠monitor监视器来完成,
那monitor到底是个啥玩意呢? 小编偷偷告诉你,其实monitor是用C++所写。
http://hg.openjdk.java.net/jdk8/jdk8/hotspot/ 网址都给你们找好了,点击左边zip、gz下载都行。 网速不好的同学可以在网上“hotspot 源码下载” ,下载之后文件如下图:
下载之后为了方便浏览,小编建议你们可以去下载一个CLion工具来看代码,或者直接用文本编辑器打开也行。
java对象怎么和monitor关联的呢?
这里就牵扯到另外一个知识点,我们每一个对象在内存中分为三块区域:对象头(Header)、实例数据(Instance Data)、对齐填充(Padding)。而这个对象头就包含了一个monitor的引用地址,指向了一个具体的monitor对象。
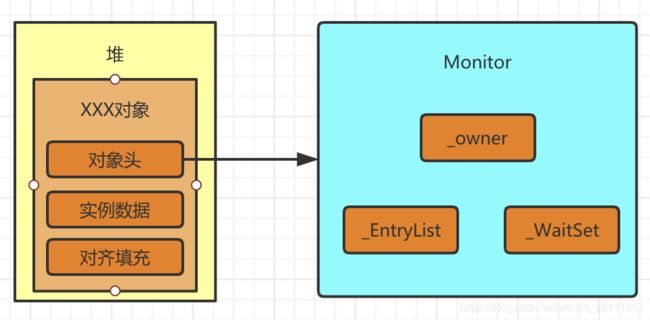
monitor里面包含了什么?
我们先找到monitor对象对应的源文件:/src/share/vm/runtime/objectMonitor.hpp,往下翻可以看到ObjectMonitor的构造方法,里面有一系列成员属性。
ObjectMonitor() {
_header = NULL;
_count = 0;
_waiters = 0,
_recursions = 0; // 记录线程的重入次数
_object = NULL;
_owner = NULL; // 标识拥有该monitor的线程
_WaitSet = NULL; // 存储正处于wait状态的线程
_WaitSetLock = 0 ;
_Responsible = NULL ;
_succ = NULL ;
_cxq = NULL ; // 存放竞争失败线程的单向链表
FreeNext = NULL ;
_EntryList = NULL ; // 存储等待锁block状态的线程
_SpinFreq = 0 ;
_SpinClock = 0 ;
OwnerIsThread = 0 ;
_previous_owner_tid = 0;
}
挑几个比较重要的来说一下:
_recursions:这个在上文讲monitorenter指令的时候有提到,就是记录线程线程获取锁的次数,获取到锁该属性则会+1,退出同步代码块则-1;
_owner:当一个线程获得了monitor的所有权,则该对象会保存到_owner中。
_WaitSet:当线程入wait状态,则会存储到_WaitSet当中。
_cxq :当线程之间开始竞争锁,如果锁竞争失败后,则会加入_cxq链表中。
_EntryList:当新线程进来尝试去获取锁对象,又没有获取到对象的时候,则会存储到_EntryList当中。
5.2 monitor 竞争
什么情况下会竞争?
当多个线程执行同步代码块的时候,这个时候就会出现锁竞争。
当线程执行同步代码块时,先执行monitorenter指令, 这个时候会调用interpreterRuntime.cpp中的函数
源文件如下:src/share/vm/interpreter/interpreterRuntime.cpp,搜索:monitorenter
IRT_ENTRY_NO_ASYNC(void, InterpreterRuntime::monitorenter(JavaThread* thread, BasicObjectLock* elem))
// 代码省略
// 是否用偏向锁
if (UseBiasedLocking) {
// Retry fast entry if bias is revoked to avoid unnecessary inflation
ObjectSynchronizer::fast_enter(h_obj, elem->lock(), true, CHECK);
} else {
// 重量级锁
ObjectSynchronizer::slow_enter(h_obj, elem->lock(), CHECK);
}
// 代码省略
IRT_END
线程之间如何竞争锁的?
对于重量级锁,monitorenter函数中会调用 :ObjectSynchronizer::slow_enter,
最终调用到这个函数上:ObjectMonitor::enter,源码位于:/src/share/vm/runtime/objectMonitor.cpp
void ATTR ObjectMonitor::enter(TRAPS) {
// The following code is ordered to check the most common cases first
// and to reduce RTS->RTO cache line upgrades on SPARC and IA32 processors.
Thread * const Self = THREAD ;
void * cur ;
// 1、通过CAS操作尝试把monitor的_owner设置成当前线程
cur = Atomic::cmpxchg_ptr (Self, &_owner, NULL) ;
if (cur == NULL) {
assert (_recursions == 0 , "invariant") ;
assert (_owner == Self, "invariant") ;
return ;
}
// 2、重入锁
if (cur == Self) {
// 重入锁计数器也需要+1
_recursions ++ ;
return ;
}
// 3、如果是当前线程第一次进入该monitor
if (Self->is_lock_owned ((address)cur)) {
assert (_recursions == 0, "internal state error");
// 计数器+1
_recursions = 1 ;
// 把当前线程设置赋值给_owner
_owner = Self ;
OwnerIsThread = 1 ;
return ;
}
// TODO-FIXME: change the following for(;;) loop to straight-line code.
for (;;) {
jt->set_suspend_equivalent();
// 4、获取锁失败,则等待锁释放
EnterI (THREAD) ;
if (!ExitSuspendEquivalent(jt)) break ;
_recursions = 0 ;
_succ = NULL ;
exit (false, Self) ;
jt->java_suspend_self();
}
}
此处省略了锁的自旋优化等操作,文章后面会讲到
以上代码具体的操作流程如下:
1)通过CAS尝试把monitor的_owner属性设置为当前线程
2)如果之前设置的owner等于当前线程,说明当前线程再次进入monitor,即重入锁,执行_recursions ++ ; 记录重入次数。
3)如果当前线程是第一次进入monitor,设置_recursions = 1,_owner = 当前线程,该线程成功获得锁并返回。
4、如果获取锁失败,等待锁释放
5.3. monitor 等待
上文有提到,如果锁竞争失败后,会调用EnterI (THREAD) 函数,还是在objectMonitor.cpp源码中搜索:::EnterI
以下代码小编省略了部分:
void ATTR ObjectMonitor::EnterI (TRAPS) {
Thread * Self = THREAD ;
assert (Self->is_Java_thread(), "invariant") ;
assert (((JavaThread *) Self)->thread_state() == _thread_blocked , "invariant") ;
// 尝试获取锁
if (TryLock (Self) > 0) {
assert (_succ != Self , "invariant") ;
assert (_owner == Self , "invariant") ;
assert (_Responsible != Self , "invariant") ;
return ;
}
// 自旋操作尝试获取锁
if (TrySpin (Self) > 0) {
assert (_owner == Self , "invariant") ;
assert (_succ != Self , "invariant") ;
assert (_Responsible != Self , "invariant") ;
return ;
}
// 当前线程封装成ObjectWaiter对象node,状态设置成ObjectWaiter::TS_CXQ
ObjectWaiter node(Self) ;
Self->_ParkEvent->reset() ;
node._prev = (ObjectWaiter *) 0xBAD ;
node.TState = ObjectWaiter::TS_CXQ ;
// 通过CAS把node节点push到_cxq队列中
ObjectWaiter * nxt ;
for (;;) {
node._next = nxt = _cxq ;
if (Atomic::cmpxchg_ptr (&node, &_cxq, nxt) == nxt) break ;
// Interference - the CAS failed because _cxq changed. Just retry.
// As an optional optimization we retry the lock.
// 再次尝试获取锁
if (TryLock (Self) > 0) {
assert (_succ != Self , "invariant") ;
assert (_owner == Self , "invariant") ;
assert (_Responsible != Self , "invariant") ;
return ;
}
}
// 挂起线程
for (;;) {
// 挂起之前再次尝试获取锁
if (TryLock (Self) > 0) break ;
assert (_owner != Self, "invariant") ;
if ((SyncFlags & 2) && _Responsible == NULL) {
Atomic::cmpxchg_ptr (Self, &_Responsible, NULL) ;
}
// park self
if (_Responsible == Self || (SyncFlags & 1)) {
TEVENT (Inflated enter - park TIMED) ;
Self->_ParkEvent->park ((jlong) RecheckInterval) ;
// Increase the RecheckInterval, but clamp the value.
RecheckInterval *= 8 ;
if (RecheckInterval > 1000) RecheckInterval = 1000 ;
} else {
TEVENT (Inflated enter - park UNTIMED) ;
// 通过park将当前线程挂起,等待锁释放
Self->_ParkEvent->park() ;
}
// 尝试获取锁
if (TryLock(Self) > 0) break ;
}
return ;
}
以上代码具体流程概括如下:
1)进入EnterI后,先会再次尝试获取锁对象
2)把当前线程封装成ObjectWaiter对象node,状态设置成ObjectWaiter::TS_CXQ ;
3)在for循环中,通过CAS把node节点push到_cxq(上文有提到这个属性)列表中,同一时刻可能有多个线程把自己到node节点push到_cxq列表中。
4)node节点push到_cxq 列表之后,通过自旋尝试获取锁,如果还是没有获取到锁,则通过park将当前线程挂起,等待唤醒。
5)当前线程被唤醒时,会从挂起到点继续执行,通过TryLock再次尝试锁。
5.4 monitor 释放
什么时候会释放monitor?
当线程执行完同步代码块时,调用monitorexit指令释放锁,这个时候锁就会被释放。
还是在objectMonitor.cpp源码中搜索:::exit
释放monitor过程是什么?
exit函数代码如下,当然小编也有大部分的删减,留下比较主要的代码部分。
void ATTR ObjectMonitor::exit(bool not_suspended, TRAPS) {
// 判断计数器,不等于0则执行-1
if (_recursions != 0) {
_recursions--; // this is simple recursive enter
TEVENT (Inflated exit - recursive) ;
return ;
}
// w = 最后被唤醒的线程
ObjectWaiter * w = NULL ;
int QMode = Knob_QMode ;
// QMode == 2,会绕过EntryList队列,从cxq队列中获取线程用于竞争锁
if (QMode == 2 && _cxq != NULL) {
w = _cxq ;
assert (w != NULL, "invariant") ;
assert (w->TState == ObjectWaiter::TS_CXQ, "Invariant") ;
// 唤醒线程
ExitEpilog (Self, w) ;
return ;
}
// QMode还有还好几种策略,小编就不一一列举了
// 最后拿到了要被唤醒的线程
w = _EntryList ;
if (w != NULL) {
guarantee (w->TState == ObjectWaiter::TS_ENTER, "invariant") ;
// 唤醒线程
ExitEpilog (Self, w) ;
return ;
}
}
观察以上代码,都需要调用ExitEpilog函数来唤醒线程, 还是在objectMonitor.cpp源码中搜索:::ExitEpilog
void ObjectMonitor::ExitEpilog (Thread * Self, ObjectWaiter * Wakee) {
assert (_owner == Self, "invariant") ;
_succ = Knob_SuccEnabled ? Wakee->_thread : NULL ;
ParkEvent * Trigger = Wakee->_event ;
Wakee = NULL ;
// Drop the lock
OrderAccess::release_store_ptr (&_owner, NULL) ;
OrderAccess::fence() ; // ST _owner vs LD in unpark()
if (SafepointSynchronize::do_call_back()) {
TEVENT (unpark before SAFEPOINT) ;
}
DTRACE_MONITOR_PROBE(contended__exit, this, object(), Self);
// 最重要的时候这里,调用unpark来进行唤醒
Trigger->unpark() ;
// Maintain stats and report events to JVMTI
if (ObjectMonitor::_sync_Parks != NULL) {
ObjectMonitor::_sync_Parks->inc() ;
}
}
以上代码具体流程概括如下:
1)退出同步代码块时会让_recursions - 1,当_recursions的值等于0的时候,说明线程释放了锁。
2)根据不同的策略(由QMode来指定),最终获取到需要被唤醒的线程(代码中是:w)
3)最后调用ExitEpilog函数中,最终由unpark来执行唤醒操作。
六、永恒钻石
6.1 CAS 介绍
CAS的英文单词CompareAndSwap的缩写,比较并替换。CAS需要有3个操作数:内存地址V、旧的预期值A、即将要更新的目标值B。
CAS指令执行时,当内存地址V的值与预期值A相等时,将目标值B保存到内存当中,否则就什么都不做。 整个比较并替换的操作是一个原子操作。
CAS是乐观锁技术,当多个线程尝试使用CAS同时更新同一个变量时,只有其中一个线程能更新变量的值,而其他线程都失败,失败的线程并不会挂起,而是被告知这次竞争失败,并可以再次尝试。
优点:可以避免优先级倒置和死锁等危险,竞争比较便宜,协调发生在更细的力度级别,允许更高程度的并行机制等等。
缺点:
1、循环时间长开销很大,如果CAS失败,会一直进行尝试,如果CAS长时间一直不成功,可能会给CPU带来很大的开销。
2、只能保证一个共享的原子操作,我们可以使用循环CAS的方式来保证原子操作,但是对多个共享变量操作时,循环CAS就无法保证操作的原子性,这个时候就可以用锁来保证原子性。
3、ABA问题,如果内存地址V初次读取的值是A,并且在准备赋值的时候检查仍然为A,那我们就能说它的值没有被其他线程改变过吗?
如果在这段期间它的值曾被改成了B,后来又被改回A,那CAS就会误认为它从来没有被改变过,这个漏洞称之为CAS操作的ABA问题。Java并发包为了解决这个问题,提供了一个带有标记的原子引用类 “AtomicStampendReference”,它可以通过控制变量值的版本来保证CAS的正确性。
因此,在使用CAS前要考虑清楚“ABA”问题是否会影响程序并发性的正确性,如果需要解决ABA问题,改用传统的互斥同步可能比原子类更高效
介绍完CAS,那么肯定就多多少少介绍以下实现原理,我们以AtomicInteger为例,它是JDK中提供能够保障原子性操作的类。
/**
* Atomically increments by one the current value.
*
* @return the updated value
*/
public final int incrementAndGet() {
return unsafe.getAndAddInt(this, valueOffset, 1) + 1;
}
我们点进去看它里面的方法,拿incrementAndGet方法为例子,这个方法是在原有值的基础上进行+1操作,它的实现调用Unfafe类的方法,我们再点进去看。
public final int getAndAddInt(Object var1, long var2, int var4) {
int var5;
do {
var5 = this.getIntVolatile(var1, var2);
} while(!this.compareAndSwapInt(var1, var2, var5, var5 + var4));
return var5;
}
Unfafe类使Java拥有了像C语言的指针一样操作内存空间的能力,同时也带来了指针问题,过度的使用Unsafe类会使得出错的几率变大。因此Java官方不建议使用的,Unsafe对象也不能直接调用,只能通过放射来获取。
小编这里说一下getandAddInt方法的执行流程,
var1:传进来的是this,也就是AtomicInteger实例对象;
var2:偏移量,通过结合var1就能够获得在内存中的最新值;
var4:要进行累加的值,也就是 1 ;
先通过var1+var2 获取到内存中最新的值,然后再调用compareAndSwapInt方法,这个方法又会通过var1+var2参数获取内存中最新的值,与var5的值进行比较,如果比较成功,这把var5+var4的结果更新到内存中去。如果不成功,则继续循环操作。也就是我们刚刚介绍CAS所说,比较并替换。
6.2 sync 锁升级过程
在JDK1.5以前,sync是一个重量级的锁,在1.6以后,对sync做了大量的各种优化,包含偏向锁、轻量级锁、适应性自旋、锁消除、锁粗化等等,这些技术都是为了线程之间更加高效的共享数据,以及解决竞争问题,从而达到程序的执行效率。
当然锁肯定升级的过程:无锁 —— 偏向锁 —— 轻量级锁 —— 重量级锁。
每个不同的锁都有不同的使用藏场景,在了解各种锁的特性之前,我们还需要搞清楚对象在内存中的布局!
6.3 对象的布局
我们每一个对象在内存中分为三块区域:对象头(Header)、实例数据(Instance Data)、对齐填充(Padding)。
对象头:
当一个线程尝试访问sync修饰的代码块时,它先要获得锁,这个锁对象是存在对象头中的。
以Hotspot虚拟机为例,对象头里面主要包含了Mark Word(字段标记)、Klass Pointer (指针类型),如果对象是数组类型,还包含了数组的长度。
怎么又扯到Hotspot虚拟机呢? 小伙伴可以这样理解,JVM可以理解为一套规范,而Hotspot是具体的虚拟机产品。 就好比如你们要找女朋友、或者男朋友,既然找朋友是不是就要有一定的要求或者规范,JVM就可以看作这个规范,而Hotspot就是具体的男朋友或者女朋友了。
你不信? System.out.println(System.getProperties()); 运行这个代码吧,找找你们java.vm.name等于什么。
java.vm.name=Java HotSpot(TM) 64-Bit Server VM
Mark Word :里默认存储对象的HashCode、分代年龄和锁位标记。 这个也是sync锁实现的重要部分了,在运行期间,Mark Word 里存储的数据会随着锁标位置的变化而变化。 在64位虚拟机下,Mark Word是64bit大小的,其存储结构如图:
Mark Word 64位虚拟机存储结构
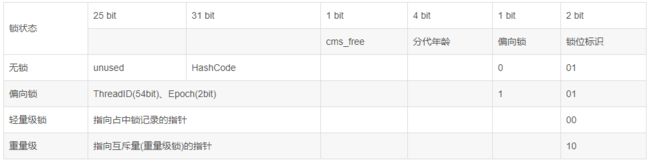
以上这个表格数据不能乱来对不对,我们可以查看源码:src/share/vm/oops/markOop.hpp
里面注释写的很清楚了,对照以下注释反映出上面的表格,更加直观。
// 32 bits:
// --------
// hash:25 ------------>| age:4 biased_lock:1 lock:2 (normal object)
// JavaThread*:23 epoch:2 age:4 biased_lock:1 lock:2 (biased object)
// size:32 ------------------------------------------>| (CMS free block)
// PromotedObject*:29 ---------->| promo_bits:3 ----->| (CMS promoted object)
//
// 64 bits:
// --------
// unused:25 hash:31 -->| unused:1 age:4 biased_lock:1 lock:2 (normal object)
// JavaThread*:54 epoch:2 unused:1 age:4 biased_lock:1 lock:2 (biased object)
// PromotedObject*:61 --------------------->| promo_bits:3 ----->| (CMS promoted object)
// size:64 ----------------------------------------------------->| (CMS free block)
**Klass Pointer **:用于存储对象的类型指针,该指针指向它的类元数据,JVM通过这个指针确定是哪个对象的实例。
对象头 = Mark Word + Klass Point 在未开启指针压缩对情况下所占大小:
以64位系统为例:Mark Word = 8 bytes,指针类型 = 8 bytes ,对象头 = 16 bytes = 128bits;
实例数据:
类中定义的成员变量
对齐填充:
对齐填充并不是必然存在的,也没有什么特殊的意义,它仅仅只是占位符的作用。由于HotPort VM的自动内存管理系统要求对象起始地址必须是8字节的整倍数,当对象的实例数据部分没有对齐时,就需要通过对齐填充来不补齐。
说了这么多,都是概念性的东西,说谁不会说对不对,接下来我们尝试在把一个对象在内存中都布局输出看下:
先引入这个jar包,它能够提供我们想要看到的东西,使用方式如下:
org.openjdk.jol
jol-core
0.10
public class SyncExample4 {
static Apple apple = new Apple();
public static void main(String[] args) {
// 这里使用ClassLayout来查看
System.out.println(ClassLayout.parseInstance(apple).toPrintable());
}
}
class Apple {
private int count;
private boolean isMax;
}
以下内容就是我们Java对象内存分布所查看到的内容,我们能直接看到内容有object header 翻译过来就是对象头呀, 再往下看就是loss due to the next object alignment,这个就是对齐填充,由于Apple 有一个boolean的属性,占了一个字节,所以计算机为了提高执行效率和GC垃圾回收的效率,进行了7个字节的填充(这里涉及到CPU运行小编就不多扯了)。
com.example.concurrency.sync.Apple object internals:
OFFSET SIZE TYPE DESCRIPTION VALUE
0 4 (object header) 01 00 00 00 (00000001 00000000 00000000 00000000) (1)
4 4 (object header) 00 00 00 00 (00000000 00000000 00000000 00000000) (0)
8 4 (object header) 43 c0 00 f8 (01000011 11000000 00000000 11111000) (-134168509)
12 4 int Apple.count 0
16 1 boolean Apple.isMax false
17 7 (loss due to the next object alignment)
Instance size: 24 bytes
Space losses: 0 bytes internal + 7 bytes external = 7 bytes total
看到这里我们确实能够确定对象头的存在,那么对象头里面不是说用31 bit存储了HashCode吗? 怎么没看见
我们再来执行一段代码, 计算一下apple的HashCode是多少,看运行结果可知,本次运行apple的HashCode是7ea987ac,我们再看看对应VALUE值也发生了改变。这里有一个概念,由于存在大小端存储方式,我们需要从后往前看。
public class SyncExample4 {
static Apple apple = new Apple();
public static void main(String[] args) {
// 查看HashCode
System.out.println(Integer.toHexString(apple.hashCode()));
System.out.println(ClassLayout.parseInstance(apple).toPrintable());
}
}
class Apple {
private int count;
private boolean isMax;
}
7ea987ac
# WARNING: Unable to attach Serviceability Agent. You can try again with escalated privileges. Two options: a) use -Djol.tryWithSudo=true to try with sudo; b) echo 0 | sudo tee /proc/sys/kernel/yama/ptrace_scope
com.example.concurrency.sync.Apple object internals:
OFFSET SIZE TYPE DESCRIPTION VALUE
0 4 (object header) 01 ac 87 a9 (00000001 10101100 10000111 10101001) (-1450726399)
4 4 (object header) 7e 00 00 00 (01111110 00000000 00000000 00000000) (126)
8 4 (object header) 43 c0 00 f8 (01000011 11000000 00000000 11111000) (-134168509)
12 4 int Apple.count 0
16 1 boolean Apple.isMax false
17 7 (loss due to the next object alignment)
Instance size: 24 bytes
Space losses: 0 bytes internal + 7 bytes external = 7 bytes total
细心一点的小伙伴就会发现,上文不是说了对象头一共占了16个字节吗? 这里三个object header 才12个字节也不对呀?
这里JVM默认会开启指针压缩,我们可以通过参数把它关掉:

在打印看结果,就是16个字节。
OFFSET SIZE TYPE DESCRIPTION VALUE
0 4 (object header) 01 00 00 00 (00000001 00000000 00000000 00000000) (1)
4 4 (object header) 00 00 00 00 (00000000 00000000 00000000 00000000) (0)
8 4 (object header) 80 68 f5 1f (10000000 01101000 11110101 00011111) (536176768)
12 4 (object header) 02 00 00 00 (00000010 00000000 00000000 00000000) (2)
最后总结以下: Java对象有三个部分组成:对象头、实例数据、对齐填充,其中对象头又包含Mark Word、Klass Pointer(如果对象是数组类型,还包含了数组的长度)。
七、至尊星耀
Mark Word 64位虚拟机存储结构
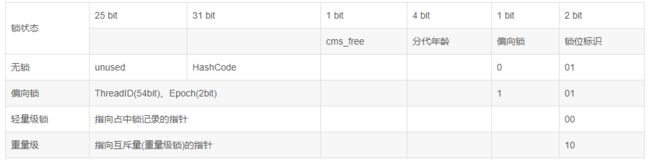
7.1 偏向锁
偏向锁的原理
在大多数情况下,锁不仅不存在多线程竞争,而且总是由同一个线程多次获得。为了让线程获得的锁的代价更低,从而引入偏向锁的。
我们对照Mark Word存储结构来看,当一个线程访问同步代码快之后,会把Mark Word中的偏向锁标识由0改为1,并且存储当前线程的ID,以后该线程进入和退出同步代码的的时候,则不需要进行CAS操作来加锁和解锁。只需要简单的测试一下对象头里是否存储着指向当先线程的偏向锁,如果结果成功,表示线程已经获得了锁。如果失败,需要再查看Mark Word中的偏向锁标识是否设置成1,如果没有,则使用CAS竞争锁。
我们可以使用代码来观察下:
偏向锁在Java 6 和Java 7中默认是开启的,但是他在应用程序启动几秒钟之后才激活,我们需要先来关闭延迟启动。

public class SyncExample4 {
public static void main(String[] args) {
Apple apple = new Apple();
apple.start();
}
}
class Apple extends Thread {
private Object lock = new Object();
@Override
public void run() {
synchronized (lock) {
System.out.println(ClassLayout.parseInstance(lock).toPrintable());
}
}
}
OFFSET SIZE TYPE DESCRIPTION VALUE
0 4 (object header) 05 d8 86 22 (00000101 11011000 10000110 00100010) (579262469)
4 4 (object header) 9c 7f 00 00 (10011100 01111111 00000000 00000000) (32668)
8 4 (object header) e5 01 00 f8 (11100101 00000001 00000000 11111000) (-134217243)
12 4 (loss due to the next object alignment)
Instance size: 16 bytes
Space losses: 0 bytes internal + 4 bytes external = 4 bytes total
由于大小端存储,原本偏向锁和锁位标识是在最后的,现在我们需要看最前8位数:00000101
第一个1 代表是偏向锁,并且锁标识01,和我们的表格也能够对应上。
偏向锁的撤销
偏向锁使用了一种等到竞争出现了才释放锁的机制,所以当其他线程来进行争夺锁的时候,持有偏向锁的线程才会释放锁。但是偏向锁的撤销的时候,需要等到一个全局安全点,也就是在这个时间点上没有正在执行的字节码。 它首先会暂停所有线程(包括拥有偏向锁的线程),然后在判断当前是不是偏向锁,如果偏向锁标识等于1,就撤销回0;
偏向锁的好处
偏向锁的好处也很显而易见,只有同一个线程来访问同步代码块的时候,效率是很高的,只需要判断当先线程和Mark Word里面存储的线程是否是一致就行了。如果程序中大多数的锁都是不同的线程来进行访问,那么这个时候偏向锁就是多余的了。
我们可以通过JVM参数来关闭偏向锁:-XX:-UseBiasedLocking
7.2 轻量级锁
什么是轻量级锁
轻量级锁是在JDK6中加入的新型锁机制,引入轻量级锁的目的是为了,在多线程交替执行同步代码块的情况下,尽量避免重量级锁引起的性能消耗,但是如果多线程在同一时刻进入临界区,会导致轻量级锁膨胀升级为重量级锁,所以轻量级锁的出现并非代替重量级锁。
栈桢
我们在JVM虚拟中,有堆和栈,而在栈中还包含了我们对象的各种方法,一个方法就相当于一个“栈桢”。其中方法中也是可以存储内容的,其中就包含了Displaced Mark Word,这个有什么作用呢? 接着往下看

轻量级锁原理
线程在执行同步代码快之前,JVM会现在当前线程的栈桢中创建用于存储锁记录的空间,并将对象头中的Mark Word 复制到锁记录当中。这个就是我们刚刚所说Displaced Mark Word了。JVM利用CAS操作尝试将对象的Mark Word更新为指向锁记录的指针。如果成功,当先线程获得锁并且将锁位标识改为00,如果失败了则需要判断当前对象的Mark Word是否指向当前线程的指针,如果是则表示当线程已经持有对象的锁,执行同步代码快。如果不是只能说明该锁对象被其他线程占用,这时的轻量级需要膨胀到重量级锁,锁位标识改为10,后面的线程进入阻塞状态。
轻量级锁的释放
解锁的时候,会使用CAS操作将Displaced Mark Word替换回到对象头,如果成功,则表示没有竞争发生。如果失败,表示当前锁存在竞争,锁就会膨胀成重量级锁。
7.3 自旋锁
自旋锁是在JDK1.4中就已经引入了,默认是关闭的,在JDK1.6中默认几句开启了。
为什么要用自旋锁呢?自旋锁通俗易懂的来说,就是循环去获取锁。 因为在我们锁升级的过程中,如果线程竞争锁失败,就立即被挂起,然后等待被唤醒,其实这个时候性能开销是比较大的。可能线程还正在被挂起的时候,锁已经被释放掉了,所以就有了自旋锁的操作。
当线程竞争锁失败之后,先自旋来尝试获取锁,如果锁被占用的时间很短,自旋等待的效果就非常好。反之,如果锁被占用的时间很长,那么自旋的线程只会拜拜消耗处理器资源,而不会有任何的作用。自旋默认的默认值是10次,可使用参数-XX:PreBlockSpin来更改。
适应性自选锁
由于我们自旋锁可能回带来一定的性能消耗,但是我们又不清楚设置自旋次数多少合适,所以这个时候适应性自选锁就来了。适应性自选就意味着自旋的时间不再固定了,而是由前一次在同一个锁的自旋时间及所得拥有者的状态来决定。假设在同一个同步代码块上自旋10次就能获得锁,那么虚拟机就会认为这次也能够获得锁,还允许自旋的时间稍微长一点。 那么再假设一个同步代码块从来都没有自旋成功过,那么虚拟机就可能省略自旋的过程,以免浪费性能。
光说还不如来点实际的代码,源码路径:src/share/vm/runtime/objectMonitor.cpp ,搜索::TrySpin_VaryDuration
int ObjectMonitor::TrySpin_VaryDuration (Thread * Self) {
// 固定自旋次数
int ctr = Knob_FixedSpin ;
if (ctr != 0) {
while (--ctr >= 0) {
if (TryLock (Self) > 0) return 1 ;
SpinPause () ;
}
return 0 ;
}
// 适应式自旋
for (ctr = Knob_PreSpin + 1; --ctr >= 0 ; ) {
if (TryLock(Self) > 0) {
// 成功后,修改自旋的时间
int x = _SpinDuration ;
if (x < Knob_SpinLimit) {
if (x < Knob_Poverty) x = Knob_Poverty ;
_SpinDuration = x + Knob_BonusB ;
}
return 1 ;
}
SpinPause () ;
}
}
7.4 消除锁
我们先来看以下代码:
public String getContent() {
return new StringBuffer().append("a").append("b").append("c").toString();
}
@Override
public synchronized StringBuffer append(String str) {
toStringCache = null;
super.append(str);
return this;
}
StringBuffer中的append是同步的,但是我们这个getContent这个方法,每次都是新new一个对象来进行操作。所以不同的线程进来,锁住的对象也是不同的,所以就根本不会造成线程上的问题。 这个时候虚拟机即使编译器(JIT)在运行时,对一些代码上的要求同步,但是被检测到不可能存在共享数据竞争的锁进行消除,这个就是锁消除。
7.5 锁粗化
什么是锁粗化呢? JVM会探测一连串细小的操作都是用同一个对象加锁,将同步代码块的范围放大,放到这串操作的外面,这样只需要加一次锁即可。
public static void main(String[] args) {
StringBuffer sb = new StringBuffer();
for (int i = 0; i < 100; i++) {
sb.append("a");
}
}
@Override
public synchronized StringBuffer append(String str) {
toStringCache = null;
super.append(str);
return this;
}
看上面代码,StringBuffer的append的方法里面是有加同步关键字的,然而我们在外面循环了100次,就要进入锁和退出锁各100次,所以这个时候JVM就会把锁粗化。 把append方法同步关键字去掉,扩大在外面来,就只需要进入和退出1次即可。
public static void main(String[] args) {
StringBuffer sb = new StringBuffer();
synchronized (sb) {
for (int i = 0; i < 100; i++) {
sb.append("a");
}
}
}
八、最强王者
终章:平时写代码如何对synchroized优化
终于打上王者了,不要以为打上王者就行啦,还有一些日常操作我们还需要注意到的。
减少sync的同步代码块的范围:
同步代码块精简,执行就会更快,可能轻量级锁、自旋锁就搞定了,不会升级为重量级锁。
public static void main(String[] args) {
StringBuffer sb = new StringBuffer();
synchronized (sb) {
System.out.println("a");
}
}
降低sync锁的粒度:
锁的对象也是有讲究的,假设test01和02本身没有任何业务相关的代码,但是锁的对象越是同一个,这样岂不是并发效率就很低了。
public class SyncExample4 {
public void test01(){
synchronized (SyncExample4.class){}
}
public void test02(){
synchronized (SyncExample4.class){}
}
}
读写分离:
我们尽量可以做到,读的时候不加锁,写入和删除的时候加锁,这样就可以保证多个线程同时来读取数据。
举个例子:
HashTable容器竞争激烈的并发环境下,效率低是因为多个线程竞争同一把锁,假如容器有多把锁,每一把锁用于锁住容器中一部分数据,那么多线程访问容器里面不同的数据段的数据时,线程间不会存在锁竞争,从而有效提高并发访问率。这就是ConcurrentHashMap的锁分段技术,将数据分成一段一段的存储,然后把每一段数据分配一把锁,当一个线程占用锁访问其中一段数据的时候,其他段段数据也能被其他线程访问。
作者:IT贱男
原文链接:https://jiannan.blog.csdn.net/article/details/104902100