第3课: TensorFlow中的线性和逻辑回归
CS20si课程资料和代码Github地址
- 第3课: TensorFlow中的线性和逻辑回归
- 线性回归: 根据出生率预测平均寿命
- 问题描述
- 数据描述
- 方法
- 控制流: Huber loss
- tf.data
tf.data真的表现更好吗?- 优化器(Optimizers)
- optimizer列表
- 逻辑回归(Logistic Regression)和MNIST
- 线性回归: 根据出生率预测平均寿命
线性回归: 根据出生率预测平均寿命
让我们从一个简单的线性回归开始,我们将会建立一个十分简单的神经网络,它只有一层来表示自变量X和因变量Y之间的线性关系。
问题描述
我最近对可视化世界各国的出生率和平均寿命之间的关系很着迷,基本上你有越多的孩子,你的死亡年龄越小!你可以在这儿查看世界银行的统计。

问题是,能否量化这种关系?换句话说,如果出生率是X平均寿命是Y,我们能否找到线性函数f使Y=f(X)?如果我们知道这种关系,那么给定出生率就可以预测平均年龄。
关于这个问题,我们将会用世界银行的世界发展指标数据集中的2010年的相关数据,你可以从这个GitHub地址下载它。
数据描述
- Name:Birth rate - life expectancy in 2010
- X = 出生率 Type:float
- Y = 平均寿命 Type:float
- 数据个数:190
方法
首先假设出生率和平均寿命之间的关系是线性的,即能找到w和b使得Y=wX+b。
为了找到w和b,我们将要在一层的神经网络上进行反向传播(Back Propagation),损失函数使用均方误差。
import tensorflow as tf
import utils
DATA_FILE = "data/birth_life_2010.txt"
# Step 1: read in data from the .txt file
# data is a numpy array of shape (190, 2), each row is a datapoint
data, n_samples = utils.read_birth_life_data(DATA_FILE)
# Step 2: create placeholders for X (birth rate) and Y (life expectancy)
X = tf.placeholder(tf.float32, name='X')
Y = tf.placeholder(tf.float32, name='Y')
# Step 3: create weight and bias, initialized to 0
w = tf.get_variable('weights', initializer=tf.constant(0.0))
b = tf.get_variable('bias', initializer=tf.constant(0.0))
# Step 4: construct model to predict Y (life expectancy from birth rate)
Y_predicted = w * X + b
# Step 5: use the square error as the loss function
loss = tf.square(Y - Y_predicted, name='loss')
# Step 6: using gradient descent with learning rate of 0.01 to minimize loss
optimizer = tf.train.GradientDescentOptimizer(learning_rate=0.001).minimize(loss)
with tf.Session() as sess:
# Step 7: initialize the necessary variables, in this case, w and b
sess.run(tf.global_variables_initializer())
# Step 8: train the model
for i in range(100): # run 100 epochs
for x, y in data:
# Session runs train_op to minimize loss
sess.run(optimizer, feed_dict={X: x, Y:y})
# Step 9: output the values of w and b
w_out, b_out = sess.run([w, b])
在训练了100个epoch之后,我们得到的均方损失为30.04,这时的w=-6.07,b=84.93。这说明出生率和平均年龄负相关,但并不是说多要一个孩子减寿6年。

你可以在X和Y的关系上做其他假设,比如加入二次项:\(Y_{predicted} = wX^2 + uX + b\)
# Step 3: create variables: weights_1, weights_2, bias. All are initialized to 0
w = tf.get_variable('weights_1', initializer=tf.constant(0.0))
u = tf.get_variable('weights_2', initializer=tf.constant(0.0))
b = tf.get_variable('bias', initializer=tf.constant(0.0))
# Step 4: predict Y (number of theft) from the number of fire
Y_predicted = w * X * X + X * u + b
# Step 5: Profit!
控制流: Huber loss
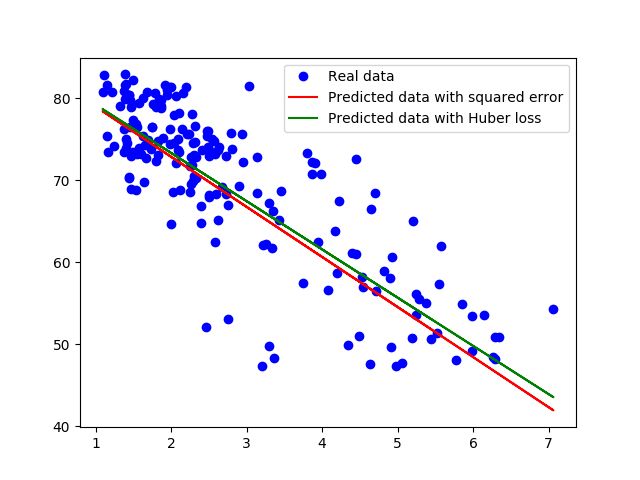
看看输出的图片,我们看到在下方中间的位置有一些离群点(噪声):它们有低出生率但是也有低平均寿命。这些点将拟合线拉向它们,使模型表现得比较差,一种削弱离群点影响的方法是用Huber损失。直观上,平方损失的缺点是给离群点过大的权重,而Huber损失被设计为给予利群点更少的权重:
[图片上传失败...(image-bf4174-1533217266248)]
为了在Tensorflow中实现它,我们可能想用一些Python语言的东西,比如:
if tf.abs(Y_predicted - Y) <= delta:
# do something
然而,这种方法只在TensorFlow的eager execution(下一节课会涉及)开启时才奏效。如果我们在当前情况下使用,TensorFlow会立即报错:“TypeError: Using atf.Tensoras a Pythonboolis not allowed.”。我们需要用TensorFlow定义的控制流运算,你可以在这里找到完整的api。
| Control Flow Ops | tf.count_up_to, tf.cond, tf.case, tf.while_loop, tf.group ... |
| Comparison Ops | tf.equal, tf.not_equal, tf.less, tf.greater, tf.where, ... |
| Logical Ops | tf.logical_and, tf.logical_not, tf.logical_or, tf.logical_xor |
| Debugging Ops | tf.is_finite, tf.is_inf, tf.is_nan, tf.Assert, tf.Print, ... |
为了实现Huber损失,我们可以用tf.greater,tf.less或者tf.cond,这里将会用tf.cond因为它最具一般性。
tf.cond(
condition,
true_fn=None,
false_fn=None,
...)
基本的意思是如果condition为True就使用true_fn,反之使用false_fn。
def huber_loss(labels, predictions, delta=14.0):
residual = tf.abs(labels - predictions)
def f1(): return 0.5 * tf.square(residual)
def f2(): return delta * residual - 0.5 * tf.square(delta)
return tf.cond(residual < delta, f1, f2)
使用Huber损失,我们得到了w: -5.883589, b: 85.124306,它和平方损失的对比图如下:
tf.data
根据Derek Murray对tf.data的介绍,使用placeholder和feed_dicts的好处是可以将数据处理放在TensorFlow外面,这样可以简单的用Python打乱,分批和生成随机数据等等。坏处是这种机制可能潜在的拖慢你的程序,用户常常在一个线程中处理他们的数据,从而导致数据瓶颈,从而降低执行速度。
TensorFlow也提供了队列作为另一种处理数据的方式。它允许你处理数据流水化、线程化并减少加载数据到placeholder的时间来提高性能。然而,队列以难以使用并容易奔溃而闻名。(译者:如果学过操作系统的知识会好一些)
注意在我们的线性回归中,我们的输入数据存储在一个名叫data的numpy数组中,每一行是一个数值对(x,y),对应一个样本点。为了将data灌入我们的TensorFlow模型,我们创建了两个placeholder名叫x和y,然后在一个for循环中将数据灌入。我们当然可以用分批数据代替单个数据,但是关键是这种灌数据到TensorFlow的方式很慢,而且可能妨碍其它运算的执行。
# Step 1: read in data from the .txt file
# data is a numpy array of shape (190, 2), each row is a datapoint
data, n_samples = utils.read_birth_life_data(DATA_FILE)
# Step 2: create placeholders for X (birth rate) and Y (life expectancy)
X = tf.placeholder(tf.float32, name='X')
Y = tf.placeholder(tf.float32, name='Y')
...
with tf.Session() as sess:
...
# Step 8: train the model
for i in range(100): # run 100 epochs
for x, y in data:
# Session runs train_op to minimize loss
sess.run(optimizer, feed_dict={X: x, Y:y})
使用tf.data代替在非TensorFlow对象中存储数据,我们可以使用数据创建一个Dataset:
tf.data.Dataset.from_tensor_slices((x, y))
x,y都应该是tensor,但是记住这是因为TensorFlow和Numpy是无缝集成的,它们可以是Numpy数组。
dataset = tf.data.Dataset.from_tensor_slices((data[:,0], data[:,1]))
将dataset输入的类型和形状打印出来:
print(dataset.output_types) # >> (tf.float32, tf.float32)
print(dataset.output_shapes) # >> (TensorShape([]), TensorShape([]))
你也可以用TensorFlow的文件格式分析器将数据从文件灌入一个tf.data.Dataset,它们全部都和老的DataReader有惊人的相似性。
-
tf.data.TextLineDataset(filenames):文件中的每一行作为一个输入。(csv) -
tf.data.FixedLengthRecordDataset(filenames):dataset中的每条数据都相同的长度。(CIFAR,ImageNet) -
tf.data.TFRecordDataset(filenames):如果你的数据以tfrecord格式存储可以用这个。
例子:
dataset = tf.data.FixedLengthRecordDataset([file1, file2, file3, ...])
在我们将数据导入神奇的Dataset对象后,可以通过一个迭代器遍历Dataset中的样本,可以在这里了解迭代器。
iterator = dataset.make_one_shot_iterator()
X, Y = iterator.get_next() # X is the birth rate, Y is the life expectancy
每一次我们执行运算X,Y,我们会得到一个新的样本数据。
with tf.Session() as sess:
print(sess.run([X, Y])) # >> [1.822, 74.82825]
print(sess.run([X, Y])) # >> [3.869, 70.81949]
print(sess.run([X, Y])) # >> [3.911, 72.15066]
现在我们可以像你之前用placeholder做的那样用X和Y计算Y_predicted和损失。不同的是当你执行计算图时不再需要向feed_dict中灌数据。
for i in range(100): # train the model 100 epochs
total_loss = 0
try:
while True:
sess.run([optimizer])
except tf.errors.OutOfRangeError:
pass
我们不得不捕捉OutOfRangeError异常是因为TensorFlow竟然没有自动为我们处理它。如果我们运行这个代码,我们会在第一个epoch获得非0的loss而在后面的epoch中loss总是为0。这是因为dataset.make_one_shot_iterator()只能使用一次,在一个epoch之后迭代器到达了数据的最后,你不能重新初始化它来进行下一个epoch。
为了在多个epoch上使用迭代器,我们使用dataset.make_initializable_iterator()创建迭代器,然后在每个epoch开始时重新初始化迭代器。
iterator = dataset.make_initializable_iterator()
...
for i in range(100):
sess.run(iterator.initializer)
total_loss = 0
try:
while True:
sess.run([optimizer])
except tf.errors.OutOfRangeError:
pass
使用tf.data.Dataset你分别只需要一条命令就可以对数据进行分批、打乱、重复等操作。你也可以映射你dataset中的每个元素来将它们用指定的方法进行变形从而创建新的dataset。
dataset = dataset.shuffle(1000)
dataset = dataset.repeat(100)
dataset = dataset.batch(128)
dataset = dataset.map(lambda x: tf.one_hot(x, 10))
# convert each element of dataset to one_hot vector
tf.data真的表现更好吗?
为了比较tf.data和placeholder的性能,我将每个模型跑了100次然后计算每个模型的平均用时。在我的Macbook Pro 2.7Ghz Intel Core I5 cpu上,placeholder平均用时为9.0527秒,tf.data平均用时为6.1228秒。tf.data比placeholder的性能提高了32.4%
优化器(Optimizers)
在前面的代码中,还有两行没有解释。
optimizer = tf.train.GradientDescentOptimizer(learning_rate=0.001).minimize(loss)
sess.run([optimizer])
我记得第一次运行类似代码时非常困惑:
- 为什么optimizer在
tf.Session.run()中? - TensorFlow怎样知道哪些参数需要更新?
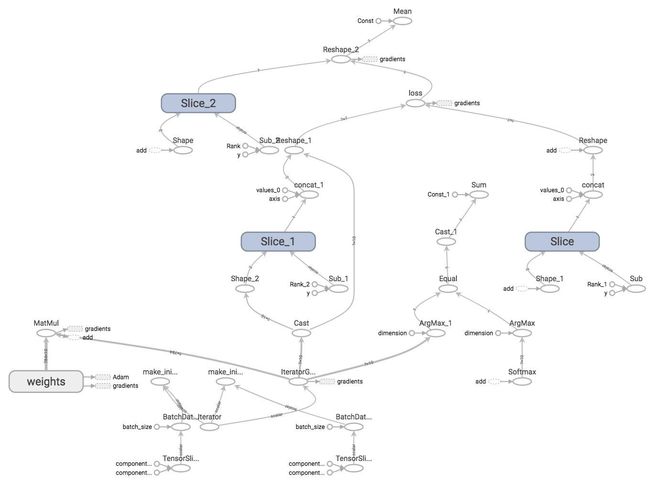
optimizer是一个用来最小化loss的运算,为了执行这个运算我们需要将它传入tf.Session.run()中。当TensorFlow执行optimizer时它会执行在计算图中optimizer运算依赖的部分,而我们可以看到optimizer依赖loss,然后loss依赖输入X和Y以及两个变量w和b。

从计算图上你可以看到一个巨大的节点GradientDescentOptimizer,它依赖三个节点:weights,bias和gradients。
GradientDescentOptimizer的意思是我们的参数更新策略为梯度下降,TensorFlow自动的为我们计算梯度并更新w和b的值来最小化loss。
默认情况下,optimizer训练它的目标函数依赖的所有可训练的变量,如果有些变量你不想训练,你可以在声明变量时设置关键字trainable=False。一个不需要训练变量的例子是global_step,它是一个在很多TensorFlow模型中用来跟踪模型运行了多少次的常见变量。
global_step = tf.Variable(0, trainable=False, dtype=tf.int32)
learning_rate = 0.01 * 0.99 ** tf.cast(global_step, tf.float32)
increment_step = global_step.assign_add(1)
optimizer = tf.train.GradientDescentOptimizer(learning_rate) # learning rate can be a tensor
你也可以让你的optimizer计算指定变量的梯度,你也可以修改optimizer计算的梯度,然后让optimizer用修改过的梯度进行优化。
# create an optimizer.
optimizer = tf.train.GradientDescentOptimizer(learning_rate=0.1)
# compute the gradients for a list of variables.
grads_and_vars = optimizer.compute_gradients(loss, )
# grads_and_vars is a list of tuples (gradient, variable). Do whatever you
# need to the 'gradient' part, for example, subtract each of them by 1.
subtracted_grads_and_vars = [(gv[0] - 1.0, gv[1]) for gv in grads_and_vars]
# ask the optimizer to apply the subtracted gradients.
optimizer.apply_gradients(subtracted_grads_and_vars)
你还可以用tf.stop_gradient来阻止特定的tensor对关于特定loss的导数计算的贡献。
stop_gradient( input, name=None )
在训练中需要冻结指定参数的时候这个方法十分有用,这里有一些TensorFlow官方文档中的例子。
- 当你训练一个GAN(生成对抗网络,Generative Adversarial Network)时对抗样本生成过程中没有BP发生。
- EM算法中M阶段不应该对E阶段的输出进行BP。
optimizer类自动的计算你的计算图中的梯度,但是你也可以用tf.gradients显式的计算特定的梯度。
tf.gradients(
ys,
xs,
grad_ys=None,
name='gradients',
colocate_gradients_with_ops=False,
gate_gradients=False,
aggregation_method=None,
stop_gradients=None
)
这个方法计算xs中ys相对于每个x的偏导数的和。ys和xs分别是一个tensor或一组tensor,grad_ys是一组持有ys接受到的梯度的tensor,长度必须和ys一致。
技术细节:这个方法在只训练模型的一部分时非常有用,例如我们可以用tf.gradients()来计算loss相对于中间层的导数G。然后我们用一个optimizer去最小化中间层输出M和M+G之间的差异,这样只更新网络的前半部分。
optimizer列表
TensorFlow支持的optimizer列表在这里查看。
- tf.train.Optimizer
- tf.train.GradientDescentOptimizer
- tf.train.AdadeltaOptimizer
- tf.train.AdagradOptimizer
- tf.train.AdagradDAOptimizer
- tf.train.MomentumOptimizer
- tf.train.AdamOptimizer
- tf.train.FtrlOptimizer
- tf.train.ProximalGradientDescentOptimizer
- tf.train.ProximalAdagradOptimizer
- tf.train.RMSPropOptimizer
这里有一篇对比这些优化算法的博客以及墙内翻译。
TL;DR:使用AdamOptimizer
逻辑回归(Logistic Regression)和MNIST
让我们在TensorFlow中构建一个逻辑回归模型来解决MNIST数据分类。
MNIST(Mixed National Institute of Standards and Technology database)是一个用来训练大量图像处理的流行的数据集,它是一个手写数字的数据集。

每张图片含有28X28个像素,你可以将它们拉伸成大小为784的一维tensor,每张图片有一个0到9的标签。
TF Learn(TensorFlow的简化接口)有一个脚本让你从杨立昆(Yann Lecun)的网站上加载MNIST数据集,然后划分成训练集、验证集和测试集。
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets('data/mnist', one_hot=True)
这里input_data.read_data_sets('data/mnist', one_hot=True)返回一个learn.datasets.base.Datasets,它包含三个数据集:55000条训练集(mnist.train),10000条测试集(mnist.test)和5000条验证集(mnist.validation)。你可以调用next_batch(batch_size)来读取这些数据。
然而在现实生活中我们不可能都用这种现成的数据解析,很可能只能自己写数据解析。我已经在utils.py中编写了下载和解析MNIST数据到numpy数组的代码。
mnist_folder = 'data/mnist'
utils.download_mnist(mnist_folder)
train, val, test = utils.read_mnist(mnist_folder, flatten=True)
我们设置flatten=True是因为我们希望将图片拉伸为1维tensor,train、val和test中的每条数据都是一个Numpy元组(tuple),第一项是图片数组(image),第二项是标签(label)。
train_data = tf.data.Dataset.from_tensor_slices(train)
# train_data = train_data.shuffle(10000) # if you want to shuffle your data
test_data = tf.data.Dataset.from_tensor_slices(test)
逻辑回归模型的建造和线性回归模型十分相似,现在我们有一大堆数据,这里我们使用mini-batch GD:
train_data = train_data.batch(batch_size)
test_data = test_data.batch(batch_size)
下一步是建立迭代器从两个数据集中获取样本,办法是建立一个迭代器然后在要拉取数据时用相应的数据集初始化它。
iterator = tf.data.Iterator.from_structure(train_data.output_types, train_data.output_shapes)
img, label = iterator.get_next()
train_init = iterator.make_initializer(train_data) # initializer for train_data
test_init = iterator.make_initializer(test_data) # initializer for test_data
with tf.Session() as sess:
...
for i in range(n_epochs): # train the model n_epochs times
sess.run(train_init) # drawing samples from train_data
try:
while True:
_, l = sess.run([optimizer, loss])
except tf.errors.OutOfRangeError:
pass
# test the model
sess.run(test_init) # drawing samples from test_data
try:
while True:
sess.run(accuracy)
except tf.errors.OutOfRangeError:
pass
和线性回归相似,你可以从课程的GitHub地址中的examples/03_logreg_starter.py下载示例代码。
Note:打乱数据可以提高性能。
现在让我们看看TensorBoard: