文字是传递信息最常用的载体,随着海量文本的涌现,信息超载和数据过剩等问题日益凸显,当大段大段的文字摆在面前,已经很少有人耐心、认真把它读完,人们急需一种更高效的信息接收方式,从视觉的角度出发,文本可视化正是解药良方。所谓一图胜千言,其实就是文本可视化的一种表现。
因此,文本可视化技术将文本中复杂的或者难以通过文字表达的内容和规律以视觉符号的形式表达出来,使人们能够利用与生俱来的视觉感知的并行化处理能力,快速获取文本中所蕴含的关键信息。
文本可视化的流程
文本可视化依赖于自然语言处理,因此词袋模型、命名实体识别、关键词抽取、主题分析、情感分析等是较常用的文本分析技术。文本分析的过程主要包括特征提取,通过分词、抽取、归一化等操作提取出文本词汇级的内容,利用特征构建向量空间模型并进行降维,以便将其呈现在低维空间,或者利用主题模型处理特征,最终以灵活有效的形式表示这些处理过的数据,以便进行可视化呈现。下图(来源:网络)是一个文本可视化的基本流程图:
文本可视化类型,除了包含常规的图表类,如柱状图、饼图、折线图等的表现形式,在文本领域用的比较多的可视化类型有:
(1)基于文本内容的可视化。
基于文本内容的可视化研究包括基于词频的可视化和基于词汇分布的可视化,常用的有词云、分布图和 Document Cards 等。
(2)基于文本关系的可视化。
基于文本关系的可视化研究文本内外关系,帮助人们理解文本内容和发现规律。常用的可视化形式有树状图、节点连接的网络图、力导向图、叠式图和 Word Tree 等。
(3)基于多层面信息的可视化
基于多层面信息的可视化主要研究如何结合信息的多个方面帮助用户从更深层次理解文本数据,发现其内在规律。其中,包含时间信息和地理坐标的文本可视化近年来受到越来越多的关注。常用的有地理热力图、ThemeRiver、SparkClouds、TextFlow 和基于矩阵视图的情感分析可视化等。
动手实战文本可视化
词云
具体过程是分词、去停用词和统计词频,然后绘制 Wordcloud 词云,这里提供下面两种方式。
得到的词云如下图所示:

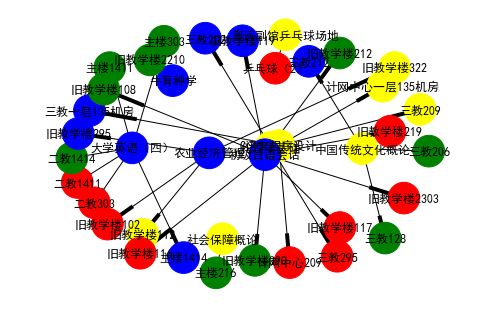
关系图
关系图法,是指用连线图来表示事物相互关系的一种方法。最常见的关系图是数据库里的 E-R 图,表示实体、关系、属性三者之间的关系。在文本可视化里面,关系图也经常被用来表示有相互关系、原因与结果和目的与手段等复杂关系,下面我们来看看如何用 Python 实现关系图制作。
基本步骤:
安装 Matplotlib、NetworkX;
解决 Matplotlib 无法写中文问题。
我们需要知道 NetworkX 绘制关系图的数据组织结构,节点和边都是 list 格式,边的 list 里面是成对的节点。下面我们看一个真实的例子,学生课程和上课地点的关系图。
classes= df['class'].values.tolist()
classrooms=df['classroom'].values.tolist()
nodes = list(set(classes + classrooms))
weights = [(df.loc[index,'class'],df.loc[index,'classroom'])for index in df.index]
weights = list(set(weights))
# 设置matplotlib正常显示中文
plt.rcParams['font.sans-serif']=['SimHei'] # 用黑体显示中文
plt.rcParams['axes.unicode_minus']=False
colors = ['red', 'green', 'blue', 'yellow']
#有向图
DG = nx.DiGraph()
#一次性添加多节点,输入的格式为列表
DG.add_nodes_from(nodes)
#添加边,数据格式为列表
DG.add_edges_from(weights)
#作图,设置节点名显示,节点大小,节点颜色
nx.draw(DG,with_labels=True, node_size=1000, node_color = colors)
plt.show()
得到的关系图如下图所示:
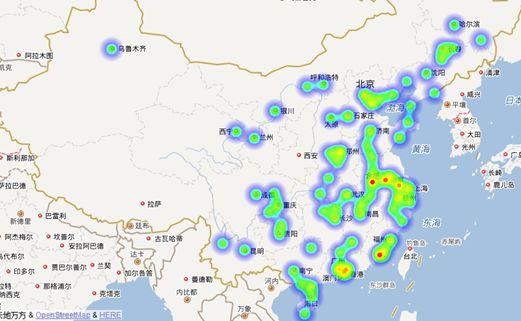
地理热力图
地理热力图,是以特殊高亮的形式显示用户的地理位置,借助热力图,可以直观地观察到用户的总体情况和偏好。
基本步骤:
- 安装 Folium;
- 将地理名词通过百度转换成经纬度。
在通过分词得到城市名称后,将地理名词通过百度转换成经纬度。首先注册密钥,使用百度 Web 服务 API 下的 Geocoding API 接口来获取你所需要地址的经纬度坐标,并转化为 JSON 结构的数据(个人接口,百度每天限制调用6000次),接下来定义经纬度获取函数:
#经纬度转换
def getlnglat(address):
url = 'http://api.map.baidu.com/geocoder/v2/'
output = 'json'
ak = 'sqGDDvCDEZPSz24bt4b0BpKLnMk1dv6d'
add = quote(address) #由于本文城市变量为中文,为防止乱码,先用quote进行编码
uri = url + '?' + 'address=' + add + '&output=' + output + '&ak=' + ak
req = urlopen(uri)
res = req.read().decode() #将其他编码的字符串解码成unicode
temp = json.loads(res) #对json数据进行解析
return temp
转换后数据格式:
北京,116.39564503787867,39.92998577808024,840
成都,104.06792346330406,30.679942845419564,291
重庆,106.53063501341296,29.54460610888615,261
昆明,102.71460113878045,25.049153100453157,238
潍坊,119.14263382297052,36.71611487305138,214
济南,117.02496706629023,36.68278472716141,212
然后,使用 Folium 库进行热力图绘制地图:
lat = np.array(cities["lat"][0:num]) # 获取维度之维度值
lon = np.array(cities["lng"][0:num]) # 获取经度值
pop = np.array(cities["count"][0:num],dtype=float) # 获取人口数,转化为numpy浮点型
data1 = [[lat[i],lon[i],pop[i]] for i in range(num)] #将数据制作成[lats,lons,weights]的形式
map_osm = folium.Map(location=[35,110],zoom_start=5) #绘制Map,开始缩放程度是5倍
HeatMap(data1).add_to(map_osm) # 将热力图添加到前面建立的map里
file_path = dir + "heatmap.html"
map_osm.save(file_path)
得到的地图热力图如下图所示:
上面列举了三种典型的文本可视化方式,当然还有更多漂亮的方式。个人在开发过程中,觉得采用前端技术实现的可视化效果最好,但是这次课程仅限于 Pyhton,所以就不讲前端知识了。
最后,我推荐三个前端可视化学习网站,第一个是百度的 Echarts,基于 Canvas,适合刚入门的新手,遵循了数据可视化的一些经典范式,只要把数据组织好,就可以轻松得到很漂亮的图表;第二个推荐 D3.js,基于 SVG 方便自己定制,D3 V4 支持 Canvas+SVG,D3.js 比 Echarts 稍微难点,适合有一定开发经验的人;第三个 three.js,是一个基于 WebGL 的 3D 图形的框架,可以让用户通过 JavaScript 搭建 WebGL 项目。