Introduction
之前方法的主要问题:
- 注意力机制只关注模态间的相互影响(object to word)
- 目前的模型都太小可能无法完全理解 visual object 之间的复杂关系
- region-based visual features 可能无法涵盖图中所有的 object,不足的视觉表达导致无法产生精准的 caption
针对前两点:
- 使用MT(Multimodal Transformer)model for image captioning,与CNN-RNN
captioning 模型不同,MT不使用RNN,完全依赖注意力机制,使用深度 encoder-decoder来同时获得每个模态的 self-attention 和跨模态的 co-attention
针对最后一点:
- 使用 multi-view feature learning 以适应对齐和非对齐的 multi-view visual features
Multimodal Transformer
The Transformer Model
Transformer的核心构成是scaled dot-product attention
点积attention包含一个query和keys与values的集合,计算query与所有keys的点积,再除以维度d的开方,然后使用softmax得到attention weights作用于values上
在实现中,keys和values是两个的矩阵和,m个query由的矩阵表示,attention function表示为:
的矩阵表示的attended features
multi-head attention(MHA)
multi-head attention可以使模型关注不同representation子空间的不同信息
multi-head包含h个平行的head,每一个对应一个独立的scaled点积attention function,multi-head attention functions的attended features F表示为:
其中的是第个head的投影矩阵,的是各heads的信息相加的output投影矩阵。是各head输出的features的维度,为了防止模型过大,被设置为
feed-forward networks(FFN)
FFN的输入来自MHA,使用两个包含ReLU激活函数和dropout的线性层进一步transforming:
Transformer是一个深度端到端架构,以encoder-decoder的策略堆积attention blocks:

L是堆叠的attention blocks的数量,encode和 decoder中的blocks数量相同
MHA学习考虑两个输入特征之间相互作用的attended features,FFN对attended features进一步非线性处理。在encoder中,每个attention block是self-attentional的,queries、keys和values来自于同一个输入特征,而decoder中的attention block包含一个self-attention层和一个guided-attention层,用encoder最后一个attention block的输出来guide attention learning
为了便于优化,跳层连接和layer normalization被用于MHA和FFN
Multimodal Transformer for Image Captioning
MT架构被描述为由image encoder和textual decoder组成
image encoder输入一张图像,使用预训练的Faster R-CNN提取region-based visual features,然后送入encoder通过self-attention learning获得attended visual representation
decoder输入attended visual features和previous word,循环预测next word
MT架构的流程图:

图中[s]是caption开始或结束的界定符
Image Encoder
输入图像先经过在Visual Genome数据集上预训练的Faster R-CNN提取一组visual features。然后根据检测到的目标的置信度降序排序,并取前m个目标。每个目标区域的卷积特征再经过一个mean-pooling得到一个维的feature vector。最终,这个图像由的特征矩阵表示。
输入进一个全连接层调整维度,使之与encoder匹配,再输入进个attention blocks的encoder。第个attention block 将第个attention block的输出作为输入,然后输入:
每个包含独立权重的MHA和FFN
Caption Decoder
输入caption首先进行tokenized,并限制到最大长度为n个词,每个词由300维的词向量表示,词向量使用在大规模语料库上预训练的300-D GloVe word embedding得到
一个caption句子由的特征矩阵表示,对于小于16个词的captions使用0-padding填充至最大尺寸
word embeddings输入一层有个hidden units的LSTM,得到的caption representations为的矩阵
训练阶段
caption decoder的输入来自image encoder和caption representations
给定attended image features 以及caption input features ,包含个attention blocks的caption decoder使用和encoder类似的策略学习去预测attended word features:
其中每个包含两个MHA和一个FFN,第一个MHA在caption words上进行self-attentions的modeling,第二个MHA在caption words上学习image-guided attention
需要注意的是self-attention只能attend输出句子中较早的位置,并且是通过在计算self-attention的softmax步骤之前masking后续位置来实现的,因此会产生一个的三角mask矩阵M。
输出特征输入到一个线性word embedding层,将features transform到维空间,是词库的大小。随后,在每个词计算下一个词的可能性的时候都使用softmax交叉熵损失。
测试阶段
caption通过word-by-word的序列方式生成。当生成第个词时,输入特征表示为 ∈ 维空间,其中0对应0-padded feature。input caption features和image features输入模型得到词库中可能性最大的词。预测得到的词随后被整合进inputs,进行循环生成新的inputs 。
为了增加生成captions的多样性,在test阶段还引入了beam search策略
Image Encoder with Multi-view Visual Representation
使用region-based local multi-view features来表示图像,每个object detector都被当做是one single view
不同detectors提取到的objects是unaligned的,为了能够在不同的views中学习相关性,前述image encoder模型进一步演化出了两个multi-view image encoder模型,Aligned Multi-View(AMV)image encoder和Unaligned Multi-View(UMV)image encoder
Aligned Multi-View Image Encoder
AMV使用一个简单的策略从不同的detectors中获得aligned multi-view features:两阶段特征提取网络
给出M个预训练的Faster R-CNN,首先选出一个检测器作为primary模型来生成对于所有views的unified bboxes,不同primary模型的选择对于生成特征的质量有一定的影响,这里直接选择了表现最好的模型来作为primary
随后,unified bboxes输入进不同的Faster R-CNN模型提取特征。实际上这些Faster R-CNN模型以及退化到各自的Fast R-CNN版本,以pre-computed bboxes作为输入,输出的multi-view features就是aligned的,这样每对multi-view features就与图像中的一个object相对应
假设生成了m个unified bboxes,第个view提取的features可以被表示为的矩阵,是features的维度。通过在列方向上的concatenate就可以得到的multi-view features X。这些aligned multi-view features可以代替前面提到的single-view feature,并且可以无缝输入至image encoder。AMV的流程如图:

其中的AMV Image Encoder和之前提到的image encoder是一样的
但是AMV使用unified bboxes的策略可能对multi-view features的多样性不利,对encoded image features的representation 能力会造成限制。此外,AMV隐式约束了每个view的目标检测器为Faster R-CNN,既可以使用pre-computed 的bboxes也可以使用built-in的RPN。这限制RetinaNet或YOLO等一阶段模型的使用。
Unaligned Multi-View Image Encoder
为了解决AMV的限制,提出了更generalized的UMV,可以直接整合不同目标检测器的unaligned multi-view features:
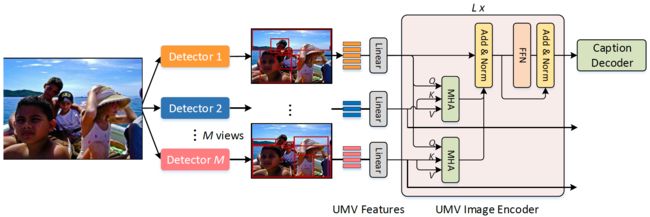
第个view的visual features可以由的矩阵表示,是features的数量,是feature的维度,不同的view可以有不同的和。Unaligned multi-view features将送入一个encoder同时进行aligned和fused。这里将同样选择其中一个view作为primary,primary输出的features将guide其他views的attention learning。其他views的attended features将被整合进primary view的features来输出output features。
给出multi-view features ,它们先线性映射至统一的维度d,变换后的representations为。假设是primary view的features,这里有M-1个MHA模块去对和之间的相互作用进行modeling:
同有相同的大小的是第个view的attended output features,并且可以通过element-wise summation与进行整合。这里的MHA可以被理解为从其他views的image features上学习image-guided attention。
最后所有的和整合在一起得到,再Normalize之后输入FFN,得到transformed representations
值得注意的是,还可以对UMV模型进行深度叠加,以了解不同views之间更准确的相互作用,从而输出更具鉴别性的视觉特征。
Experiments
Datasets
提取bottom-up attention的视觉特征的目标检测器使用Visual Genome数据集预训练。
MSCOCO
原本的83k training images,40k validation images 和 83k test images 使用 Karpathy splits分为113k training images,5k validation images 和 5k test images
Visual Genome
使用object和attribute annotations 预训练 bottom-up-attention 模型,同样使用Karpathy splits分为98k training images,5k validation images 和 5k test images。由于Visual Genome中部分数据与MSCOCO中重叠,validation 和 test splits中的内容需要仔细检查,避免影响。同时数据进行清理和筛选后使用1600个object类和400个attributes进行训练。
Implementation Details
captions将进行一系列预处理:caption sentences首先转化为小写然后tokenized为包含空格的words,丢弃预训练GloVe词库中出现次数少于5次或不存在的稀有词之后得到9343个words。通过GloVe词库,将caption中的每个word表示为word embedding vector。词库之外的words被表示为全零向量。
预训练的bottom-up-attention模型用于检测object,并从检测到的object中抽取视觉特征。对于M=3时的multi-view image representation,分别训练三个不同backbone(ResNet-101,ResNet-152和ResNeXt-101)的Faster R-CNN模型。在每个模型中,每张图像由置信度最高的100个object表示,每个object又由detected region的最后卷积特征经过mean-pooling得到的向量表示。
输入的image feature维度和输入的caption feature维度分别是2048和512。MHA中latent的维度为512,head的数量为8,每个head的latent维度。encoder和decoder中attention block的数量。
训练MT模型时使用Adam solver和大小为10的batch size。初始学习率为,是从1开始的当前epoch数。在6个epochs之后,学习率每3个epochs减半。所有模型现使用交叉熵损失训练15个epochs,然后使用self-critical损失继续训练10个epochs以减轻交叉熵优化的exposure bias。