R作图-使用circlize绘制样本物种丰度关联弦状图
circlize图也即是弦图能较好展示样本物种丰度关联关系,先前从lyao222lll博客下载过该教程,但是最近刘老师关闭了博客,现有链接无法访问。根据刘老师的教程,只需要替换对应的文本即可以画出该图。更多知识分享请到 https://zouhua.top/。
文件准备
首先准备3个表格,分别为:
物种分类信息文件(phylum_count.csv)。第一列为物种ID(此处为OTU,在circos图的中间区域展示),第二列为OTU的“门水平”分类信息(用于绘制circos外圈OTU分类),第三列为OTU分类详细信息(用于在图例中展示)。此外在后面的绘图过程中,会使用该文件确定OTU的排列顺序,所以请事先根据想要展示的顺序给该文件中的OTU进行排序。
样本分组信息文件(phenotype.csv)。第一列为样本ID(此处为Case1、Control2等共计6个样本,在circos图的中间区域展示),第二列为样本分组信息(用于绘制circos外圈样本分组,此处共计2个分组Case、Control)。此外在后面的绘图过程中,会使用该文件确定样本的排列顺序,所以请事先根据想要展示的顺序给该文件中的样本进行排序。
物种丰度表格文件(family_count.csv)。每一列为样本,每一行为物种(此处为OTU),交叉区为个OTU在各样本中的丰度(用于计算)。因OTU及样本的绘图顺序由前述2个文件确定,所以在该文件中无需纠结样本或OTU的排序。
load data
library(dplyr)
library(tibble)
library(circlize)
phen <- read.csv("phenotype.csv")
phylum <- read.csv("phylum_count.csv") %>%
column_to_rownames("tax")
family <- read.csv("family_count.csv") %>%
column_to_rownames("tax")
head(phen)
## SampleID Group
## 1 Case1 Case
## 2 Case2 Case
## 3 Case3 Case
## 4 Case4 Case
## 5 Case5 Case
## 6 Case6 Case
head(phylum)
## Case1 Case2 Case3 Case4 Case5 Case6 Control1 Control2 Control3 Control4 Control5 Control6
## p_Actinobacteriota 557 361 250 323 365 809 176 195 175 357 311 275
## p_Bacteroidota 9672 21555 24904 32516 13872 11036 31353 33061 33657 33529 15822 30801
## p_Campilobacterota 111 438 48 177 325 89 888 363 161 341 139 176
## p_Cyanobacteria 34 30 201 15 34 6 22 13 48 32 104 36
## p_Deferribacterota 0 5 0 0 0 0 0 0 0 7 8 0
## p_Desulfobacterota 103 231 87 130 90 99 168 679 287 255 224 310
head(family)
## Case1 Case2 Case3 Case4 Case5 Case6 Control1
## p_Actinobacteriota.c_Actinobacteria.o_Bifidobacteriales.f_Bifidobacteriaceae 6 0 30 30 0 0 2
## p_Actinobacteriota.c_Actinobacteria.o_Micrococcales.f_Micrococcaceae 0 3 0 0 4 7 0
## p_Actinobacteriota.c_Coriobacteriia.o_Coriobacteriales.f_Atopobiaceae 109 12 25 23 72 21 39
## p_Actinobacteriota.c_Coriobacteriia.o_Coriobacteriales.f_Coriobacteriaceae 92 27 10 35 41 161 55
## p_Actinobacteriota.c_Coriobacteriia.o_Coriobacteriales.f_Eggerthellaceae 254 306 185 139 196 605 61
## p_Actinobacteriota.c_Coriobacteriia.o_Coriobacteriales.f_uncultured 96 13 0 96 50 0 19
## Control2 Control3 Control4 Control5 Control6
## p_Actinobacteriota.c_Actinobacteria.o_Bifidobacteriales.f_Bifidobacteriaceae 3 6 0 11 6
## p_Actinobacteriota.c_Actinobacteria.o_Micrococcales.f_Micrococcaceae 0 0 0 0 0
## p_Actinobacteriota.c_Coriobacteriia.o_Coriobacteriales.f_Atopobiaceae 27 14 35 50 22
## p_Actinobacteriota.c_Coriobacteriia.o_Coriobacteriales.f_Coriobacteriaceae 15 45 125 70 50
## p_Actinobacteriota.c_Coriobacteriia.o_Coriobacteriales.f_Eggerthellaceae 133 75 162 160 169
## p_Actinobacteriota.c_Coriobacteriia.o_Coriobacteriales.f_uncultured 17 35 35 20 28
get 5 most abundant phylum
num <- 5
merge_phy <- inner_join(phen %>% select(SampleID, Group),
phylum %>% t() %>%
data.frame() %>%
rownames_to_column("SampleID"),
by = "SampleID")
merge_phy_top <- merge_phy %>%
select(-c("SampleID", "Group")) %>%
summarise_each(mean) %>%
tidyr::gather(key="tax", value="value") %>%
arrange(desc(value)) %>%
slice(c(1:num)) %>%
mutate(tax=as.character(tax))
head(merge_phy_top)
## tax value
## 1 p_Firmicutes 39684.5000
## 2 p_Bacteroidota 24314.8333
## 3 p_Spirochaetota 4497.5833
## 4 p_Proteobacteria 950.1667
## 5 p_Actinobacteriota 346.1667
group information
group_info <- phen %>% select(SampleID, Group)
head(group_info)
## SampleID Group
## 1 Case1 Case
## 2 Case2 Case
## 3 Case3 Case
## 4 Case4 Case
## 5 Case5 Case
## 6 Case6 Case
function: get profile and circos
### get tax: taxname;phylum;detail and tax profile(rowname:tax, colnames:sampleid)
get_tax_prf <- function(prof=family, num=20, class=4){
# prof=family
# num=20
# class=4
prf <- prof %>% rownames_to_column("tax") %>%
group_by(tax) %>%
mutate(phylum=unlist(strsplit(tax, ".", fixed = TRUE))[1],
otu=unlist(strsplit(tax, ".", fixed = TRUE))[class]) %>%
ungroup()
prf_cln <- prf %>% filter(phylum%in%merge_phy_top$tax) %>%
slice(-grep("uncultured", otu)) #%>%
# slice(-grep("_$", otu))
mdat <- inner_join(phen %>% select(SampleID, Group),
prf_cln %>% select(-c("tax", "phylum")) %>%
column_to_rownames("otu") %>%
t() %>% data.frame() %>%
rownames_to_column("SampleID"),
by = "SampleID")
mdat_mean <- mdat %>%
select(-c("SampleID", "Group")) %>%
summarise_each(mean) %>%
tidyr::gather(key="tax", value="value") %>%
arrange(desc(value)) %>%
slice(c(1:num)) %>%
mutate(tax=as.character(tax))
prf_final <- prf_cln %>% filter(otu%in%mdat_mean$tax) %>%
mutate()
otu_table <- prf_final %>% select(-c("tax", "phylum")) %>%
rename("OTU_ID"="otu") %>%
mutate(OTU_ID=factor(OTU_ID, levels = mdat_mean$tax))
tax_table <- prf_final %>% select(c("tax", "phylum", "otu")) %>%
setNames(c("detail", "phylum", "OTU_ID")) %>%
mutate(detail=gsub("\\.", ";", detail)) %>%
mutate(phylum=factor(phylum, levels = merge_phy_top$tax))
res <- list(otutab=otu_table,
taxtab=tax_table)
return(res)
}
### circos
circos_fun <- function(mdat_table=family_table, tag="family"){
# mdat_table=family_table
# tag="family"
taxonomy <- mdat_table$taxtab
otu_table <- mdat_table$otutab
tax_phylum <- unique(taxonomy$phylum)
all_group <- unique(group_info$Group)
# merge table
otutab <- inner_join(taxonomy, otu_table, by="OTU_ID") %>%
arrange(phylum, OTU_ID) %>%
column_to_rownames("OTU_ID") %>%
select(group_info$SampleID)
# extra parameters
all_otu <- rownames(otutab)
all_sample <- group_info$SampleID
all_ID <- c(all_otu, all_sample)
accum_otu <- rowSums(otutab)
accum_sample <- colSums(otutab)
all_ID_xlim <- cbind(rep(0, length(all_ID)), data.frame(c(accum_otu, accum_sample)))
# inter parameters
otutab$otu_ID <- all_otu
plot_data <- otutab %>% tidyr::gather(key="SampleID", value="value", -"otu_ID") %>%
mutate(otu_ID=factor(otu_ID, levels = all_otu),
SampleID=factor(SampleID, levels = all_sample)) %>%
arrange(otu_ID, SampleID)
plot_data <- plot_data[c(2, 1, 3, 3)]
names(color_otu) <- all_otu
names(color_sample) <- all_sample
### output PDF file
name <- paste0(tag, "_circlize_plot.pdf")
pdf(name, width = 20, height = 8)
circle_size = unit(1, "snpc")
gap_size <- c(rep(3, length(all_otu) - 1), 6, rep(3, length(all_sample) - 1), 6)
circos.par(cell.padding = c(0, 0, 0, 0), start.degree = 270, gap.degree = gap_size)
circos.initialize(factors = factor(all_ID, levels = all_ID), xlim = all_ID_xlim)
circos.trackPlotRegion(
ylim = c(0, 1), track.height = 0.03, bg.border = NA,
panel.fun = function(x, y) {
sector.index = get.cell.meta.data("sector.index")
xlim = get.cell.meta.data("xlim")
ylim = get.cell.meta.data("ylim")
} )
for (i in 1:length(tax_phylum)) {
tax_OTU <- {subset(taxonomy, phylum == tax_phylum[i])}$OTU_ID
highlight.sector(tax_OTU, track.index = 1, col = color_phylum[i],
text = tax_phylum[i], cex = 0.5, text.col = "black",
niceFacing = FALSE)
}
for (i in 1:length(all_group)) {
group_sample <- {subset(group_info, Group == all_group[i])}$SampleID
highlight.sector(group_sample, track.index = 1, col = color_group[i],
text = all_group[i], cex = 0.7, text.col = 'black',
niceFacing = FALSE)
}
circos.trackPlotRegion(
ylim = c(0, 1), track.height = 0.05, bg.border = NA,
panel.fun = function(x, y) {
sector.index = get.cell.meta.data('sector.index')
xlim = get.cell.meta.data('xlim')
ylim = get.cell.meta.data('ylim')
} )
circos.track(
track.index = 2, bg.border = NA,
panel.fun = function(x, y) {
xlim = get.cell.meta.data('xlim')
ylim = get.cell.meta.data('ylim')
sector.name = get.cell.meta.data('sector.index')
xplot = get.cell.meta.data('xplot')
by = ifelse(abs(xplot[2] - xplot[1]) > 30, 0.25, 1)
for (p in c(0, seq(by, 1, by = by))) circos.text(p*(xlim[2] - xlim[1]) + xlim[1], mean(ylim) + 0.4, paste0(p*100, '%'), cex = 0.4, adj = c(0.5, 0), niceFacing = FALSE)
circos.lines(xlim, c(mean(ylim), mean(ylim)), lty = 3)
} )
circos.trackPlotRegion(
ylim = c(0, 1), track.height = 0.03,
bg.col = c(color_otu, color_sample),
bg.border = NA, track.margin = c(0, 0.01),
panel.fun = function(x, y) {
xlim = get.cell.meta.data('xlim')
sector.name = get.cell.meta.data('sector.index')
circos.axis(h = 'top', labels.cex = 0.4,
major.tick.percentage = 0.4, labels.niceFacing = FALSE)
circos.text(mean(xlim), 0.2, sector.name, cex = 0.4,
niceFacing = FALSE, adj = c(0.5, 0))
} )
circos.trackPlotRegion(ylim = c(0, 1), track.height = 0.03, track.margin = c(0, 0.01))
for (i in seq_len(nrow(plot_data))) {
circos.link(
plot_data[i,2], c(accum_otu[plot_data[i,2]],
accum_otu[plot_data[i,2]] - plot_data[i,4]),
plot_data[i,1], c(accum_sample[plot_data[i,1]],
accum_sample[plot_data[i,1]] - plot_data[i,3]),
col = paste0(color_otu[plot_data[i,2]], '70'), border = NA )
circos.rect(accum_otu[plot_data[i,2]], 0,
accum_otu[plot_data[i,2]] - plot_data[i,4], 1,
sector.index = plot_data[i,2],
col = color_sample[plot_data[i,1]], border = NA)
circos.rect(accum_sample[plot_data[i,1]], 0,
accum_sample[plot_data[i,1]] - plot_data[i,3], 1,
sector.index = plot_data[i,1],
col = color_otu[plot_data[i,2]], border = NA)
accum_otu[plot_data[i,2]] = accum_otu[plot_data[i,2]] - plot_data[i,4]
accum_sample[plot_data[i,1]] = accum_sample[plot_data[i,1]] - plot_data[i,3]
}
otu_legend <- Legend(
at = all_otu, labels = taxonomy$detail, labels_gp = gpar(fontsize = 8),
grid_height = unit(0.5, 'cm'), grid_width = unit(0.5, 'cm'),
type = 'points', pch = NA, background = color_otu)
pushViewport(viewport(x = 0.85, y = 0.5))
grid.draw(otu_legend)
upViewport()
circos.clear()
dev.off()
}
family levels circos
family_table <- get_tax_prf(prof = family, num = 15, class=4)
circos_fun(mdat_table = family_table, tag = "family")
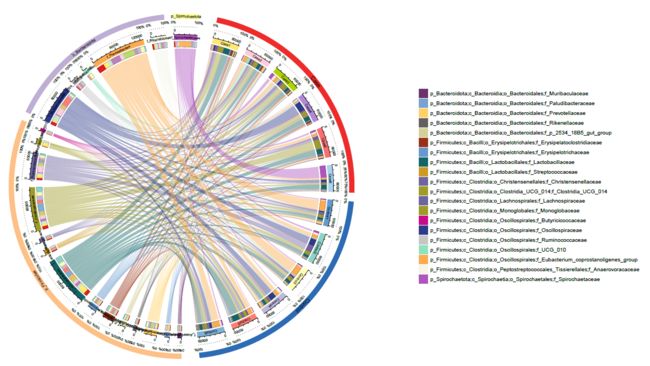
该circos图展示了21种OTU在12个样本中的丰度关系。其中,21种OTU可划分为3个门,12个样本可划分为2个分组。
左侧为circlize做图结果,分为5圈。
第一圈,各OTU的门水平分类以及各样本的分组信息;
第二圈,OTU相对丰度的百分比信息;
第三圈,OTU及样本主区块,以不同颜色和标签区分,区块外周的刻度为OTU的绝对丰度信息;
第四圈,OTU及样本副区块,与主区块(第三圈)对应,展示了各OTU在各样本中的丰度,以及各样本所含每种OTU的丰度信息;
第五圈,与OTU及样本副区块(第四圈)相对应,连线展示OTU、样本关联信息。
version
sessionInfo()
## R version 4.0.2 (2020-06-22)
## Platform: x86_64-w64-mingw32/x64 (64-bit)
## Running under: Windows 10 x64 (build 19042)
##
## Matrix products: default
##
## locale:
## [1] LC_COLLATE=English_United States.1252 LC_CTYPE=English_United States.1252 LC_MONETARY=English_United States.1252
## [4] LC_NUMERIC=C LC_TIME=English_United States.1252
## system code page: 936
##
## attached base packages:
## [1] grid stats graphics grDevices utils datasets methods base
##
## other attached packages:
## [1] ComplexHeatmap_2.4.3 circlize_0.4.10 tibble_3.0.3 dplyr_1.0.0
##
## loaded via a namespace (and not attached):
## [1] pillar_1.4.6 compiler_4.0.2 RColorBrewer_1.1-2 tools_4.0.2 digest_0.6.25 jsonlite_1.7.1
## [7] evaluate_0.14 lifecycle_0.2.0 clue_0.3-57 pkgconfig_2.0.3 png_0.1-7 rlang_0.4.7
## [13] cli_2.1.0 rstudioapi_0.11 yaml_2.2.1 parallel_4.0.2 xfun_0.18 stringr_1.4.0
## [19] knitr_1.30 cluster_2.1.0 generics_0.0.2 GlobalOptions_0.1.2 vctrs_0.3.2 tidyselect_1.1.0
## [25] glue_1.4.1 R6_2.5.0 GetoptLong_1.0.4 fansi_0.4.1 rmarkdown_2.5 tidyr_1.1.2
## [31] purrr_0.3.4 magrittr_1.5 ellipsis_0.3.1 htmltools_0.5.0 assertthat_0.2.1 shape_1.4.5
## [37] colorspace_1.4-1 utf8_1.1.4 stringi_1.5.3 crayon_1.3.4 rjson_0.2.20
引用
- 作图-使用circlize绘制样本物种丰度关联弦状图
参考文章如引起任何侵权问题,可以与我联系,谢谢。