作用:
grep 用于过滤信息
sed 修改替换文件内容,擅长对文件中的行进行操作
awk 擅长统计分析文件内容,擅长对文件中的列进行操作
grep
参数
-a 二进制以文本方式搜索数据
-c 计算找到的搜索字符串总行数
-o 仅显示匹配到的内容 统计文件中出现的次数
-i 不区分大小写
-v 取反
-w 按照单词进行过滤
-r 递归查找目录下的内容
-n 显示行号
-E 支持扩展正则 =egrep
-A 显示目标行和目标行接下来的几行 如-A2
-B 显示目标行和目标行上面的几行
-C -C2相当于-A2 -B2 显示该行前后的几行
-l 过滤的时候只显示文件名,不显示文件内容
一些案例
过滤以m开头的行
grep "^m" test.txt
过滤以m结尾的行
grep "m$" test.txt
排除空行并打印行号
grep -vn "^$" test.txt
匹配任意字符,不包括空行
grep "." test.txt
匹配所有
grep ".*" test.txt
匹配有数字的行
grep "[0-9]" test.txt
匹配数字8至少出现1次或1次以上
grep -E "8{3,5}" test.txt
匹配数字8出现3-5次
grep -E "8{1,}" test.txt
创建一个测试文件
[[email protected] /test]$ cat >> /test/grepTest < 01
> 11
> 02
> 12
> 03
> 13
> EOF
测试1:过滤包含0 的信息
grep "0" /test/grepTest

测试2:显示包含关键字0的信息,以及上一行信息
作用:生产环境可用于查看log里的ERROR关键字,以及关键字上下文的解释说明
grep -B 1 "0" /test/grepTest
-B 表示向上 before
1 表示1行

测试3:查看包括关键字及后1行的信息
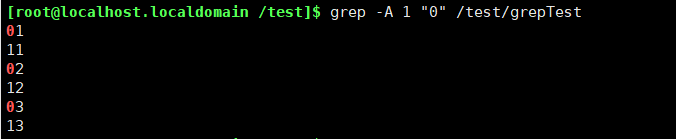
grep -A 1 "0" /test/grepTest
-A 表示向上 after
1 表示1行
测试4:查看包括关键字及前后1行的信息
grep -C 1 "02" /test/grepTest
-C 表示中心 centre
1 表示1行
02为关键字

测试5:统计关键字在文件出现的次数
grep -c "02" /test/grepTest
-c count 计数
02为关键字

sed
官方概念:字符流过滤编辑和文本字符转换工具
字符流编辑工具(行编辑工具) ==按照每行中的字符进行处理操作
PS:全屏编辑工具
vi/vim
sed是一个流编辑器,非交互式,一次处理一行的内容
处理时,把当前处理的行临时存储在缓冲区中,称为"模式空间"
接着用sed命令处理缓冲区中的内容,处理完成后,将缓冲区的内容送往屏幕
接着在处理下一行,不断重复,直到文件结束
文件的内容并没有被改变,除非重定向到存储输出
sed命令参数信息
-n 取消默认输出
-r 识别扩展正则
-i 编辑文件(将内存中的信息覆盖到磁盘)
-e 识别sed命令多个指令的操作
sed命令指令信息
p print 输出信息
i insert 插入信息,在指定信息前面插入新的信息
a append 附加信息,在指定信息后面附加新的信息
d delete 删除
s substitue 替换 如s###g
g global 全局 如s###g
c change 替换修改整行信息
具体功能:
①文件中添加信息的能力(增)
②文件中删除信息的能力(删)
③文件中修改信息的能力(改)
④文件中查询信息的能力(查)
处理文件的范围:
文本文件信息(小文件)
日志文件
配置文件
查看sed版本
sed --version
命令格式:
sed[参数][sed指令][文件信息]
SYNOPSIS
sed [OPTION]... {script-only-if-no-other-script} [input-file]...
如:sed -i 's#原内容#替换后内容#g' 需替换的文件test.txt
sed读取文件原理:
依次读取文件的每一行
查找是否匹配过滤条件
然后输出
作用说明:
①sed命令擅长对行进行操作处理
②擅长对文件的内容信息进行修改调整/删除
编写脚本:修改文件内容信息时
例子:
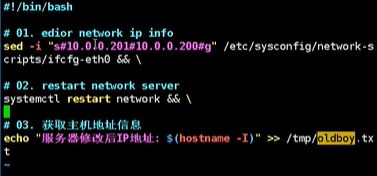
手动对网络服务中的ip地址进行修改:
第一个步骤:vi ifcfg-eth0
第二个步骤:重启网络服务
第三个步骤:检查网络
利用脚本修改网卡信息:
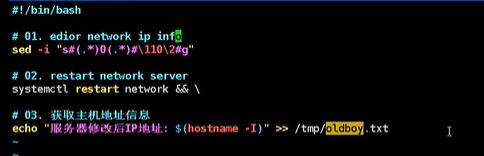
设置统配的
第一个.*可以匹配10.0.
0匹配0
()表示匹配完留存
\1表示前面第一个()的内容
10 是0修改成10
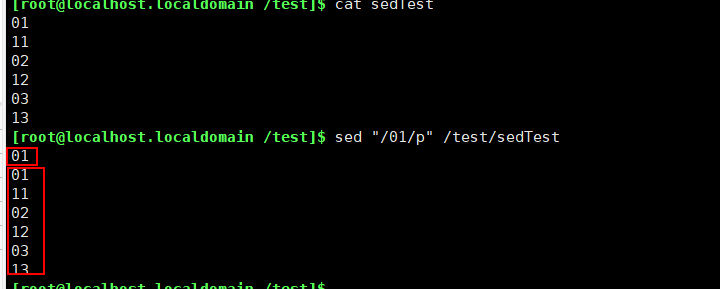
sed过滤查找
需要过滤的关键字放在//中间,如/关键字/
sed "/01/p" /test/sedTest
查找关键字01
p 代表print 输出
会将查找的关键字输出,并且源文件所有内容也会输出
若只需显示查找的关键字,使用-n参数
[[email protected] /test]$ sed -n "/01/p" /test/sedTest
01
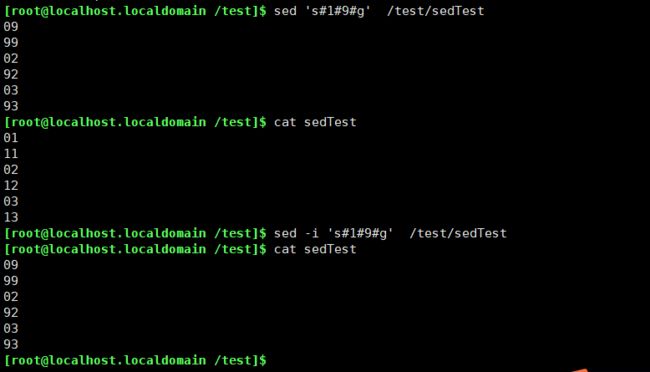
sed修改替换文件内容
测试1:将文件里的1替换为9
vim替换方式为:
:%s#1#9#g
sed替换方式为:
sed 's#1#9#g' /test/sedTest #临时替换
sed -i 's#1#9#g' /test/sedTest #-i 永久替换
tr替换命令
①源数据长度 > 替换后数据长度
abcd > 123
echo abcd|tr "abcd" "123"
[[email protected] /test]$ echo abcd|tr "abcd" "123"
1233
#abcd替换成123. abc-->123 , d-->3
②源数据长度 < 替换后数据长度
abc < 1234
echo abcd|tr "abc " "1234"
[[email protected] /test]$ echo abcd|tr "abc " "1234"
123d
#只替换了需要替换的前三位abc变为123
③源数据长度 = 替换后数据长度
abcd =1234
echo abcd|tr "abcd" "1234"
[[email protected] /test]$ echo abcd|tr "abcd" "1234"
1234
#没有什么特别的
sed命令实践操作##
准备文件:
cat >person.txt<
102,zhaoyao,CTO
103,Alex,COO
104,yy,CFO
105,feixun,CIO
106.oldboy.CIO
EOF
①sed命令信息查询
若只需显示查找的关键字,使用-n参数
p 代表print 输出
根据文件内容的行号进行查询:
测试1:根据行号,输出单行内容
显示第三行的内容
关键:3p
sed -n '3p' person.txt
测试2:根据行号,输出多行内容
(连续的多行)
输出1-3行
sed -n '1,3p' person.txt
测试3:根据行号,输出多行内容
(不连续的多行)
输出第一行和第三行
sed -n '1p;3p' person.txt
根据文件内容信息进行查询:
测试1:根据内容信息,输出单行内容
查找有oldboy的行的信息
sed -n '/oldboy/p' person.txt
测试2: 根据内容信息,输出多行内容(连续的多行)
将有oldboy到alex行的信息输出
关键: ,
sed -n '/oldboy/,/Alex/p' person.txt
测试3: 根据内容信息,输出多行内容(不连续的多行)
将有oldboy或alex行的信息输出
关键: ;
sed -n '/oldboy/p;/Alex/p' person.txt
②sed命令添加信息
-i 永久替换
p print 输出信息
i insert 插入信息,在指定信息前面插入新的信息
a append 附加信息,在指定信息后面附加新的信息
需求1:在文件的第一行添加信息
100,olbgirl,UFO
需要关键字:i 会在行的上面插入信息
1 表示第一行
sed -i '1i100,olbgirl,UFO' person.txt
需求2:在文件的最后一行添加信息
107,oldbbb,OOO
需要关键字:$ 表示最后一行
a 会在行的下面插入信息
sed -i '$a107,oldbbb,OOO' person.txt
需求3:在第三行后面添加oldboy
sed '3aoldboy' person.txt
需求4:在第二行前面添加oldboy
sed '2ioldboy' person.txt
需求5:
在oldboy行前面添加oldgirl,在oldboy后面添加olddog
分析:需先查找oldboy
多个命令使用-e
sed -e '/oldboy/ioldgirl' -e '/oldboy/aolddog' person.txt
③sed命令删除信息
关键字:d 代表delete
需求1:删除第三行(删除单行
sed '3d' person.txt
需求2:删除第2-6行(删除多行
sed '2,6d' person.txt
需求3:删除第2和6行(删除多行
sed '2d;6d' person.txt
需求4:取消空行
分析:先查找出空行
sed -n '/^$/d' person.txt
sed -n '/^$/!p' person.txt
④sed命令修改信息
sed 's###g'
若需要替换的内容包括#
可使用
sed 's///g'
经常使用的:
sed 's#()#\n#g' 后项引用前项进行替换 \n指的是前面的第n个()取到的内容. 所以我们需要把我们想要的内容,提前用()括起来
如:利用sed命令取出ip地址
第一个历程:
取出ip地址的行,第三行
ip address show eth0|sed -n '3p'
第一个历程:
取出ip地址,删除前部分匹配.*net 的,留下中间的,删除匹配后部分/24.*的
ip address show eth0|sed -n '3p'|sed -r 's#^.*net (.*)/24.*#\1#g'
-r识别扩展正则
取出此行的所有信息^.*net (.*)/24.*
取括号里匹配到的内容供后面的\1使用
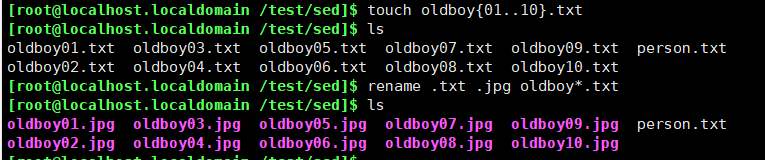
批量修改文件名
修改txt为jpg
[[email protected] /test/0214]$ touch oldboy{01..03}.txt
[[email protected] /test/0214]$ ls
oldboy01.txt oldboy02.txt oldboy03.txt
[[email protected] /test/0214]$ ls oldboy*|sed -r 's#(.*)txt#mv & \1jpg#g'|bash
[[email protected] /test/0214]$ ls
oldboy01.jpg oldboy02.jpg oldboy03.jpg
ls oldboy*txt|sed -r 's#(.*)txt#mv & \1jpg#g'|bash
-r 识别扩展正则
(.*)txt取出的是以txt结尾的内容
替换成
\1 取的是()内的,也就是txt之前的内容
&代表替换前的整体信息,类似于{}
mv
& =(.*)txt
\1jpg=oldboy01.jpg
批量重命名的命令:rename
rename .txt .jpg oldboy*.txt
.txt为文件名需要修改的部分
.jpg为需要修改后的
oldboy*.txt为需要修改的文件
注
①修改文件前,需对文件进行备份
可使用
-i.bak 代替-i
②在替换文件内容时,请勿使用
-ni ,会将文件内容进行清空
关于暂存区
sed----------> 模式空间----(-i参数)--->文件
h H ↓ g G
暂存区
暂存空间里默认存储一个空行
h 把模式空间里的内容拷贝到暂存缓存区
H 把模式空间里的内容追加到暂存缓冲区
g 取出暂存缓冲区的内容,将其复制到模式空间,覆盖该处原有内容
G 取出暂存缓冲区的内容,将其复制到模式空间,追加在原有内容后面
[root@instance-x0nj9foj scripts]# cat sed.txt
linjiahao
shisong
baishiming
默认的空行
第一行的内容写入到暂存区,替换最后一行输出
sed '1h;$g' sed.txt
[root@instance-x0nj9foj scripts]# sed '1h;$g' sed.txt
linjiahao
shisong
baishiming
linjiahao
降低一行的内容删除(从模式空间)但保留至暂存区,在最后一行调用暂存区追加输出
sed -r '1{h;d};$G' sed.txt
awk
擅长对列进行操作/进行数据信息的统计
官方概念:
gawk - pattern scanning and processing language
模式扫描和处理文件语言
查看版本:
awk --version
语法格式:
awk [选项] '模式' [文件信息]
内置变量
NR代表行 number records
NF 每一行有多少列 number of fields
FS 字段分隔符 field separator
在//中输入要查找的字符
OFS #指定输出字段分隔符
$0 #代表每行的所有内容
查询:
按照行号查询:
NR==代表行
示例1:查询第2行 awk 'NR==2' awkTest.txt
示例2:查看2-4行 awk 'NR==2,NR==4' awkTest.txt
示例3:查看2和4行 awk 'NR==2;NR==4' awkTest.txt
按照字符查询:
在//中输入要查找的字符
示例1:查看this 到 end 行
awk '/test/,/end/' awkTest.txt
示例2:查看this 和 end 行
awk '/test/;/end/' awkTest.txt
练习:
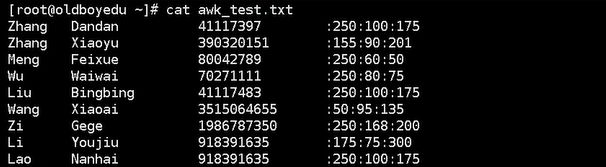
准备文档:
vim awk_test.txt
Zhang Dandan 41117397 :250:100:175
Zhang Xiaoyu 390320151 :155:90:201
Meng Feixue 80042789 :250:60:50
Wu Waiwai 70271111 :250:80:75
Liu Bingbing 41117483 :250:100:175
Wang Xiaoai 3515064655 :50 :95 :135
Zi Gege 1986787350 :250:168:200
Li Youjiu 918391635 :175:75:300
Lao Nanhai 918391635 :250:100:175

#查找到的内容以,分隔
awk '/Xiaoyu/{print $1","$3}' awk_test.txt
#查找到的内容默认以空格分隔
awk '/Xiaoyu/{print $1,$3}' awk_test.txt
print代表输出
$1代表包含Xiaoyu所在的行的第一列参数
,表示间隔,输出的是空格
$3是第三列参数
"," 代表输出的是,
也就是要取最后一列 :250:100:175的第二段100

$NF 代表最后一列
-F代表自定义以什么作为分隔符,awk默认以空格作为分隔符
awk '/Zhang/{print $4}' awk_test.txt|awk -F ":" '{print$3}'
默认分隔符改成 冒号:
+代表若是几个:相连,仍是一个分隔符
"[:]+"
利用-F "[: ]+" +将多个连续的分隔符汇总为一个整体
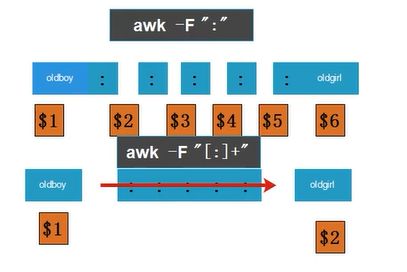
"[ :]" 以空格和冒号都作为分隔符
$(NF-1) 从后往前数1列
$3~/^41/
关键符号波浪线 ~ 对指定的列进行匹配
若是!~表示排除
表示取第三列,以41开头的
awk '$3~/^41/{print $1,$2,$3}' awk_test.txt

$3~第三列中
1$|5$ ,以1或者5结尾的
column -t 将结果以表格的方式呈现
awk '$3~/1$|5$/{print $1,$2}' awk_test.txt|column -t

显示上替换(输出的内容改变,文件真实内容不变)
gsub
g --gawk
sub --substitute
格式:
gsub(//,"",)
gsub(/需要替换的信息/,"修改成什么信息",哪一列需要被替换)
awk '$2~/Xiaoyu/{gsub(/:/,"$",$NF);print $NF}' awk_test.txt
$2~/Xiaoyu/ 第二列是Xiao的行
{gsub(/:/,"$",$NF) 将:替换为$,替换的列是NF列
输出NF列print $NF

排除文件中的空行/或者注释信息
grep -Ev "^#|^$" awkTest.txt
sed -n '/^#|^$/!p' awkTest.txt
awk '$0!~/^#|^$/' awkTest.txt
总结
awk中$符号的用法
$1 $2 $3 取第几列
$NF 取最后一列
$(NF-n) 取倒数第n列
$0 取所有列的信息
awk高级功能
①对日志信息进行计数
②对日志信息数值进行求和(如 对流量求和)
③对数组进行排序分析
④进行脚本编写
模式概念:
普通模式
①正则表达式作为模式
如:awk '/^123/{print $1}'
②利用比较匹配信息
如:NR==2 等于第二行
N2>2 大于第二行
N2<2 小于第二行
特殊模式
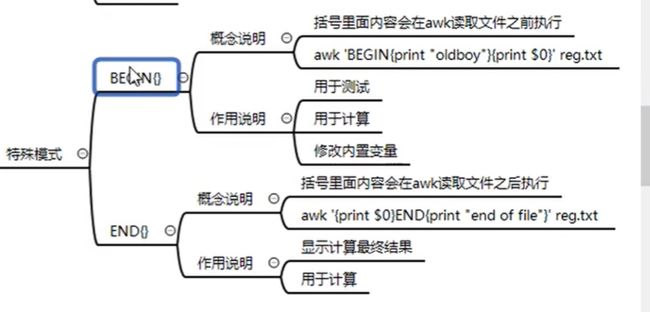
BEGIN{print}
在读取文件前,显示信息
如,加上表头
awk 'BEGIN{print "姓","名"}{print $0}' awk_test.txt|column -t
END{print}
在读取文件后,显示信息
用于计算
awk 'BEGIN{print 1+1}'
利用awk统计空行
每读取一个空行,i会加1
awk '/^#/{i++}END{print i}' /etc/services
统计系统中的虚拟用户,普通用户
统计普通用户数量
①用户信息保存文件:/etc/passwd
②找出普通用户的行,包含bash的 awk '$NF~/bash/' /etc/passwd
③统计
awk '$NF~/bash/{i++}END{print i}' /etc/passwd
虚拟用户数量
awk '$NF!~/bash/{i++}END{print i}' /etc/passwd
统计是否有人在暴力破解文件,扫描secure文件是否有输错密码的Failed password关键字
awk '/Failed password/{i++}END{print i}' /secure
求和
sum=sum+$n
n代表需要进行求和的列
对1-10的序列求和,
seq 10|awk '{sum=sum+$1;print sum}'
AWK的命令分为四种
#示例1,匹配awk 'pattern' filename
[root@shell ~]# awk '/root/' /etc/passwd
#示例2,处理动作 awk '{action}' filename
[root@shell ~]# awk -F: '{print $1}' /etc/passwd
示例3,匹配+处理动作 awk 'pattern {action}' filename
[root@shell ~]# awk -F ':' '/root/{print $1,$3}' /etc/passwd
[root@shell ~]# awk 'BEGIN{FS=":"} /root/{print $1,$3}' /etc/passwd
示例4:判断大于多少则输出什么内容 command |awk 'pattern {action}'
#/\/$/ 匹配以/结尾的 \转义符 $结尾
[root@shell ~]# df |awk '/\/$/ {if($3>50000)print $4}'
awk可以结合if,while,for使用
和java类似,和shell不同.
if
语句格式:
{ if(表达式){语句;语句;... }}
打印当前管理员用户名称
awk -F: '{ if($3>0 && $3<1000){i++}} END {print i}' /etc/passwd
if...else
{if(表达式){语句;语句;... }else{语句;语句;...}}
awk -F: '{if($3==0){print $1} else {print $7}}' /etc/passwd
awk -F: '{ if($3==0){i++} else if($3>0 && $3<1000){j++} else if($3>1000) {k++}} END {print "管理员个数"i; print "系统用户个数" j; print "系统用户个 数" }' /etc/passwd
for
awk 'BEGIN{for(i=1;i<=5;i++){print i} }'
while
awk 'BEGIN{ i=1; while(i<=10){print i; i++} }'