OCTO 2.0:美团基于Service Mesh的服务治理系统详解
OCTO 2.0是美团下一代分布式服务治理系统,它基于美团现有服务治理系统OCTO 1.0与Service Mesh通信基础设施层的结合,是命名服务、配置管理、性能监控、限流鉴权等服务治理功能的全新演进版本。本文主要讲述OCTO 2.0的重要功能及实现思路,希望能对从事相关开发的同学有所帮助或者启发。
OCTO是美团内部的服务治理平台,包含服务通信框架、命名服务、服务数据中心和用户管理平台等组件,为公司内全部服务提供了整套的服务治理方案和统一的服务治理体验。我们在之前的几篇文章中分别从不同的角度介绍了OCTO平台的建设情况。包括:
-
《美团命名服务的挑战与演进》介绍了美团命名服务(MNS)从1.0到2.0演进的初衷、实现方案以及落地的效果,并介绍了命名服务作为一个技术中台组件,对业务的重要价值以及推动业务升级的一些成果。
-
《美团OCTO万亿级数据中心计算引擎技术解析》介绍了美团自研的OCTO数据中心计算引擎的演进历程及架构设计,同时详细地介绍其全面提升计算能力、吞吐能力、降低运维成本所采用的各项技术方案。
-
《美团大规模微服务通信框架及治理体系OCTO核心组件开源》介绍了OCTO的核心组件OCTO-RPC(Java通信框架)、OCTO-NS(命名服务)和OCTO-Portal(用户管理平台)的开源情况。
-
《复杂环境下落地Service Mesh的挑战与实践》从更高的视角介绍了美团当前的服务治理系统的发展史、所面临的困境和优化思路。对Service Mesh在美团大规模复杂服务场景下的落地做了深入的分析。
本文将继续介绍OCTO系统在Service Mesh化演进方面的工作。主要从数据面的角度,详细介绍各项技术方案的设计思路。
1 整体架构
我们先开看看OCTO 2.0的整体架构,如下图所示:

基础设施是指美团现有的服务治理系统 OCTO1.0,包括MNS、KMS(鉴权管理服务)、MCC(配置管理中心)、Rhino(熔断限流服务)等。这些系统接入到OCTO 2.0的控制平面,避免过多重构引入的不必要成本。
OCTO 2.0控制平面摒弃了社区的Istio,完全自研。数据平面基于开源Envoy改造。运维系统负责数据面组件的升级、发布等运维工作。更多的整体选型及原因可参考之前团队的文章: 《美团下一代服务治理系统 OCTO2.0 的探索与实践》。
对OCTO 2.0中的功能,我们分为Mesh和服务治理两个维度。下面我们来重点看下流量劫持、无损重启、服务路由等几个常见的问题,并阐述美团是如何结合现有比较完善的服务治理系统来解决这些问题的。
2 Mesh功能
2.1 流量劫持
OCTO 2.0并未采用Istio的原生方案,而是使用iptables对进出POD的流量进行劫持。主要考量了以下两个因素:
-
iptables自身存在性能损失大、管控性差的问题:
-
iptables在内核对于包的处理过程中定义了五个“hook point”,每个“hook point”各对应到一组规则链,outbond流量将两次穿越协议栈并且经过这5组规则链匹配,在大并发场景下会损失转发性能。
-
iptables全局生效,不能显式地禁止相关规则的修改,没有相关ACL机制,可管控性比较差。
-
在美团现有的环境下,使用iptables存在以下几个问题:
-
HULK容器为富容器形态,业务进程和其他所有基础组件都处于同一容器中,这些组件使用了各种各样的端口,使用iptables容易造成误拦截。
-
美团现在存在物理机、虚拟机、容器等多个业务运行场景,基于iptables的流量劫持方案在适配这些场景时复杂度较高。
鉴于上述问题,我们最终采用了Unix Domain Socket直连方式来实现业务进程和OCTO-Proxy之间的流量转发。
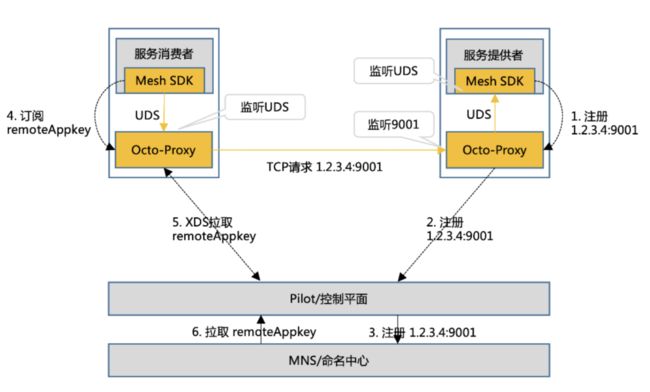
在服务消费者一方,业务进程通过轻量的Mesh SDK和OCTO-Proxy所监听的UDS地址建立连接。在服务提供者一方,OCTO-Proxy代替业务进程监听在TCP端口上,业务进程则监听在指定的UDS地址上。
该方案的优点是Unix Domain Socket相比于iptable劫持拥有更好的性能和更低的运维成本。缺点是需要Mesh SDK的支持。
2.2 服务订阅
原生Envoy的CDS/EDS请求是全量服务发现模式,即将系统中所有的服务列表都请求到数据面中。由于大规模集群中服务数量太多,真正所需的只是少数服务,所以需要改造成按需服务发现模式,仅请求需要访问的后端服务的节点列表。

在业务进程启动后,需要通过HTTP的方式向OCTO-Proxy发起订阅请求。OCTO-Proxy将所请求的后端服务Appkey更新到XDS中,XDS再向控制面请求特定的服务资源。
为了增加整个过程中的健壮性,降低后续运维成本,我们做了部分适配。例如,OCTO-Proxy的启动速度有可能慢于业务进程,所以在Mesh SDK中增加了请求的重试逻辑;将Mesh SDK和OCTO-Proxy之间的http请求改造成了同步请求,防止Pilot资源下发延时带来的问题;Mesh SDK的订阅信息也会保存在本地文件中,以便OCTO-Proxy热重启或者故障重启时使用。
2.3 无损热重启
2.3.1 流量损失场景
如何在基础组件升级过程中提供持续、不间断的服务,做到业务流量无损及业务无感知,是所有基础组件面临的一大难题。这个问题对于OCTO-Proxy这种处于流量核心链路上的组件更加重要。社区原生的Envoy自身已经支持了热重启功能但并不彻底,在某些场景下还是不能做到完全的流量无损。
下图分别在短连接和长连接两种场景下来说明OCTO-Proxy热重启时的流量损耗问题。

对于短连接,所有新的连接会在新的OCTO-Proxy上创建,旧OCTO-Proxy上已有的连接在响应到来后主动断开。旧OCTO-Proxy的所有短连接逐渐断开,这就是“Drain”(排空)的过程。连接排空之后,旧OCTO-Proxy主动退出,新的OCTO-Proxy继续工作。整个过程中的流量,完全无损。
对于长连接方式,SDK和旧OCTO-Proxy维持一条长连接不断开,并持续使用该连接发送请求。旧OCTO-Proxy进程最终退出时,该连接被动断开,此时可能尚有部分响应未返回,导致Client端请求超时。因此,Envoy的热重启对长连接场景的支持并不完美。
为了支持基础组件在升级过程中提供不间断的服务,业界目前主要使用的是滚动发布(Rolling Update)的方式:服务器分批停止服务,执行更新,然后重新将其投入使用,直到集群中所有实例都更新为新版本。在此过程中会主动摘掉业务流量,保证升级过程中业务流量不丢失。

美团内部因为要兼容物理机、虚拟机、容器,业界云原生使用K8s滚动升级的方式不太适用,所以在现有环境下,如何保证服务治理系统的高可用性以及业务的高可靠性是一个非常棘手的事情。
2.3.2 适配方案
当前方案是把业务服务分为两种角色,即对外提供服务的Server端角色和对外发起请求的Client端角色,针对两种不同的角色采用不同的热更新支持。
Client端OCTO-Proxy热更新:老的OCTO-Proxy在进入热重启状态后,对后续“新请求”直接返回含“热重启”标志的响应协议,Client SDK在收到含“热重启”标志的响应协议时,应主动切换新连接并请求重试(以避免当前Client SDK持有的旧连接由于旧OCTO-Proxy热重启流程完成后被主动关闭的问题)。这里需要注意,Client SDK需要“妥善”处理旧连接所在链路上遗留的所有“应答”协议。

通过这种Client SDK和OCTO-Proxy间的交互配合,可以支持Client端在OCTO-Proxy升级过程中保证流量的安全性。
Server端OCTO-Proxy热更新:Server侧OCTO-Proxy在热重启开始后,即会主动向Client侧OCTO-Proxy发送ProxyRestart消息,通知Client侧OCTO-Proxy主动切换新连接,避免当前Client侧OCTO-Proxy持有的旧连接由于Server侧旧OCTO-Proxy热重启流程完成后被强制关闭的问题。Client端OCTO-Proxy在收到“主动切换新连接”的请求后,应即时从可用连接池中移除,并“妥善”处理旧连接所在链路上遗留的所有“应答”协议(保守起见可标记连接不可用,并维持一段时间,比如OCTO-Proxy默认drainTime)。

2.4 数据面运维
2.4.1 LEGO运维方案
云原生环境中,Envoy运行在标准的K8S Pod中,通常会独立出一个Sidecar容器。可以使用K8s提供的能力来完成对Envoy Sidecar容器的管理,例如容器注入、健康检查、滚动升级、资源限制等。
美团内部所使用的容器运行时模式为“单容器模式”,即一个Pod内只包含一个容器(不考虑Pause容器)。由于业务进程以及所有的基础组件都运行在一个容器中,所以只能采用进程粒度的管理措施,无法做到容器粒度的管理。我们通过自研的LEGO平台解决了OCTO-Proxy的运维问题。

我们对LEGO-Agent做了定制化改造,增加了对OCTO-Proxy的热重启过程的支持。另外,LEGO-Agent还负责对OCTO-Proxy的健康检查、故障状态重启、监控信息上报和版本发布等。相对于原生K8s的容器重启方式,进程粒度重启会有更快的速度。
LEGO系统的另一个优点是,可以同时支持容器、虚拟机和物理机等多种运行时环境。
2.4.2 云原生运维方案
目前,我们也正在探索OCTO-Proxy云原生的运维方案,在此场景下最大的区别就是从进程粒度运维转变为了容器粒度运维,与业务应用做到了更好的解耦,同时可享受不可变基础设施等理念带来的红利,但是此场景带来的一个问题就是如何管理容器粒度的热重启。
为此,我们通过自研的Operator对OCTO-Proxy容器进行全生命周期的运维管理,并且期望通过Operator对OCTO-Proxy进行热重启,具体流程如下:

但是在实施过程中这个方案是有问题的,原因是K8s在底层设计上是不支持对运行中的Pod进行容器的增删操作,如果需要实现该方案,将需要对K8s底层组件进行定制化修改,这样将带来一定风险以及与社区的不兼容性。为了保证与社区的兼容性,我们对此热重启方案进行改造,最终使用双容器驻留热重启方案:

-
首先,我们在启动Pod时,给OCTO-Proxy不再只分配一个容器,而是分配两个容器,其中一个容器为正常运行状态,另一个容器为standby状态。
-
当需要对OCTO-Proxy进行热重启升级时,我们修改standby容器的镜像为最新OCTO-Proxy的镜像,此时开始热重启流程。
-
当热重启流程结束后,新容器进入正常工作状态,而旧容器进入等待状态,最终,我们将旧容器的镜像修改为standby镜像,结束整个热重启流程。
该方案利用一开始就驻留双容器在Pod内,避免了K8s对运行中Pod不能增删容器的限制,实现了在Pod中对OCTO-Proxy进行容器粒度的热重启。
3 未来规划
目前接入OCTO2.0系统的服务数量数千,天粒度流量数十亿。随着OCTO2.0在公司的不断推广,越来越多的服务开始接入,对我们的稳定性和运维能力提出了更高的要求。如何更细致的了解线上OCTO-Proxy以及所称在的业务系统的健康状况、如何在出现故障时能更及时的监测到并快速恢复是我们最近OCTO2.0系统建设的重点。除此之外,未来OCTO2.0的规划重点还包括:
-
运维、发布和稳定性建设朝云原生化方向探索。
-
支持公司内部Http服务的Mesh化,降低对中心化网关的依赖。
-
全链路mTLS支持。
4 作者简介
舒超、世朋、来俊,均来自美团基础架构部基础开发组,从事OCTO2.0的开发工作。
阅读更多
---
前端 | 算法 | 后端 | 数据
安全 | Android | iOS | 运维 | 测试
---------- END ----------
招聘信息
美团基础技术部-中间件研发中心-基础开发组,致力于研发公司级、业界领先的基础架构组件,研发范围涵盖分布式框架、命名服务、Service Mesh等技术领域。欢迎感兴趣的同学发送简历至:[email protected]。
也许你还想看
| 美团OCTO万亿级数据中心计算引擎技术解析
| 美团下一代服务治理系统 OCTO2.0 的探索与实践
| 美团大规模微服务通信框架及治理体系OCTO核心组件开源
